
Сегодня рассмотрим несколько рекомендаций по построению масштабной и устойчивой экосистемы интеграции корпоративных данных на базе Apache AirFlow от компании Astronomer, которая активно способствует продвижению и коммерциализации этого популярного инструмента дата-инженерии. Как организовать эффективную маршрутизацию рабочих процессов с пакетным ETL-оркестратором: 3 лучших практики. Стандартизация сред разработки и промышленной эксплуатации с Kubernetes...
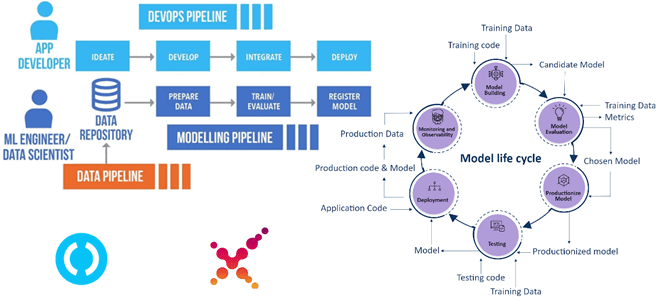
Чтобы сделать наши курсы для специалистов в области Data Science и ML-инженеров еще более полезными, сегодня рассмотрим, как организовать сквозной CI/CD-конвейер разработки и развертывания системы машинного обучения в соответствии с MLOps-концепцией на 4-х популярных Python-инструментах: MLflow, DVC, Airflow, ClearML. А в качестве примера практической реализации этой идеи разберем кейс банка...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим проблемы неконстистентности чтения из графовой СУБД Neo4j и способы их решения. Что такое bookmarks-механизм, как работает объект сеанса в Neo4j в кластерном режиме и при чем здесь драйверы. Зачем нужны закладки в Neo4j Драйверы графовой...
Мы уже писали про главные недостатки Apache NiFi как инструмента потоковой маршрутизации данных и организации ETL-процессов. Одним из них считается высокое потребление дискового пространства. Почему это случается и как с этим бороться: тонкости работы с потоковыми файлами на уровне жесткого диска - процессоры, очереди, сохранение и изменения FlowFile в Apache...
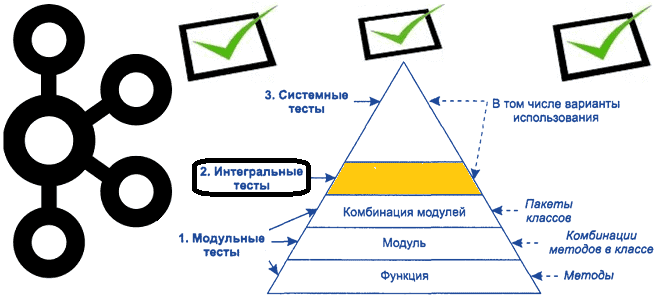
Продолжая важную для обучения разработчиков распределенных приложений и дата-инженеров тему про тестирование Big Data систем на базе Apache Kafka, сегодня рассмотрим некоторые средства для создания интеграционных тестов. Краткий ликбез по интеграционному тестированию приложений Apache Kafka В отличие от модульного тестирования, которое мы разбирали ранее, интеграционное тестирование сосредоточено на интерфейсах и потоке...
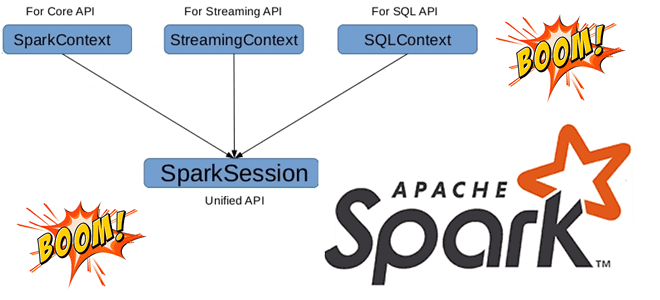
Может ли быть несколько сеансов в одном Spark-приложении с разной конфигурацией, зачем нужен метод foreachBatch() в структурированной потоковой передаче и чем он отличается от foreach(), почему возникает ошибка Table or view not found: microBatch и как ее обойти. В рамках обучения разработчиков Apache Spark и дата-инженеров заглядываем под капот этого...

Школа Больших Данных продолжает серию митапов по Apache Spark. Второй митап состоится 11 мая в 17:00 МСК по теме «Установка Apache Spark - это просто». Митап проводит специализированный учебный центр по технологиям Big data — Школа Больших данных. https://bigdataschool.ru За 2 часа митапа будет немного теории и много практики -...

Почему следует избегать PythonOperator в конвейере обработки пакетных данных на Apache Airflow и что использовать вместо этого оператора для описания задач DAG. Когда лаконичный CLI лучше наглядного GUI, где и как применять библиотеку Python Fire для оркестрации, а также планирования запуска batch-заданий. Зачем нам CLI или что не так с PythonOperator...

Практически на каждом маркетплейсе есть раздел с рекомендованными товарами, фильмами, объявлениями и т.д. Сервисы аудиокниг предлагают пользователям обратить внимание на определенные аудиокниги, которые выбираются исходя из предпочтений пользователя. Площадки с объявлениями стремятся показать наиболее интересные для пользователя объявления в разделе рекомендаций. Примеры есть практически на каждом интернет ресурсе. Давайте разберемся...

Как изменять правила фильтрации данных без перезапуска потокового Flink-приложения: практический пример для разработчиков и дата-инженеров. Чем подход с ключами состояний отличается от широковещательных соединений, каковы достоинства и недостатки этих альтернатив. Фильтрация данных в статике и динамике Практически каждая платформа потоковой передачи событий позволяет использовать фильтрацию операторов для отбора данных согласно...
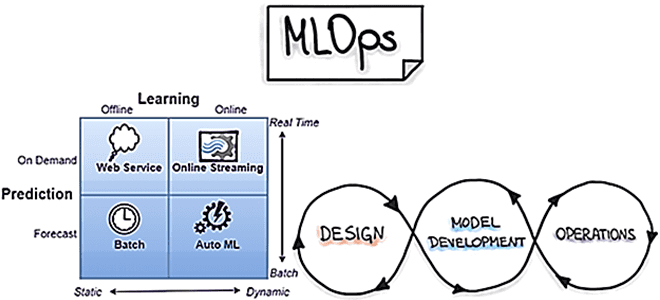
Сегодня рассмотрим наиболее распространенные в MLOps стратегии развертывания, т.е. подходы к внедрению моделей машинного обучения в производство. Выбор стратегии зависит от бизнес-требований и от контекста применения результатов ML-моделирования. Какие бывают стратегии и как они реализуются: краткий ликбез с примерами для ML-инженеров и MLOps-специалистов. Пакетное прогнозирование и веб-сервисы для MLOps Это...

Недавно мы писали про рекомендательную систему американской медиа-компании Meredith Corporation на основе графовой СУБД Neo4j и алгоритма непересекающихся множеств (Union-Find). Продолжая эту тему в рамках нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, как построить простой рекомендательный движок с помощью выражений и операторов языка запросов Cypher...
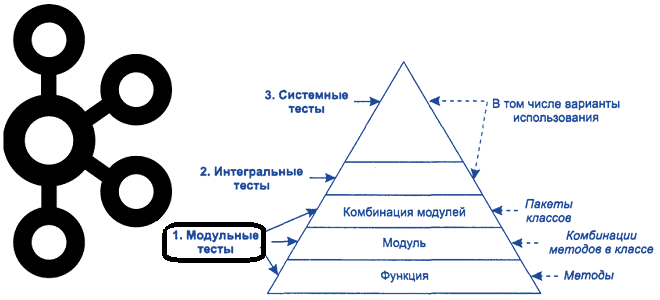
Чтобы сделать наши курсы по Apache Kafka еще полезнее, сегодня разберем, как тестировать распределенные приложения на базе этой платформы потоковой обработки событий. Краткий ликбез для разработчика Kafka Streams и дата-инженера: классы, методы и приемы модульных тестов с примерами. Ликбез по модульному тестированию: что такое mock-объекты Про виды тестирования мы уже...

В этой статье для дата-инженеров и администраторов кластера рассмотрим, как считать данные из распределенной файловой системы Apache Hadoop в MPP-СУБД Greenplum. Архитектура и принцип работы PXF-коннектора к HDFS с примерами команд. Интеграция Greenplum и Hadoop через PXF-коннекторы Мы уже писали, что представляет собой интеграционный фреймворк PXF (Platform Extension Framework), который...

Школа Больших Данных запускает серию митапов по Apache Spark. Первый состоится 20 апреля по теме «Apache Spark за 2 часа - для нетерпеливых». Митап рассчитан на инженеров данных, разработчиков и просто интересующихся: научимся использовать основную абстракцию Spark - датафреймы - за 2 часа. Неплохо немного знать python, но это необязательно. Во время митапа...

Сегодня заглянем под капот Apache Spark и разберем, для чего этому популярному вычислительному движку база метаданных, как ее назначить и что не так с хранилищем данных по умолчанию. Зачем уходить от Apache Derby к Hive и как это сделать: краткий ликбез с примерами для обучения дата-инженеров и разработчиков распределенных приложений....

Продолжая рассматривать примеры для обучения дата-инженеров по построению ETL-конвейеров, сегодня разберем, как перенести данные из облачного объектного хранилища AWS S3 в озеро данных на Hadoop HDFS с помощью готовых процессоров Apache NiFi. Такой кейс актуален для многих предприятий, которым необходимо мигрировать с сервисов Amazon в другие хранилища больших данных. Перенос...

Недавно в Google Dataproc появился бессерверный Apache Spark. Разбираемся, что это такое и зачем нужно дата-инженерам. Как работает serverless Spark в облачной платформе Google и почему выбирать между Dataflow и Dataproc стало еще сложнее. Блеск и нищета Google Dataproc Напомним, Google Dataproc – это облачный Hadoop, который работает аналогично другим...

Запуск Apache Airflow с Kubernetes сегодня стал стандартом де-факто. Однако, при практическом развертывании Airflow с помощью исполнителя Kubernetes и оператора пода в кластере этой платформы оркестрации контейнерных приложений возникает множество препятствий и трудностей. Сегодня рассмотрим, как обойти их с помощью service-mesh проекта с открытым исходным кодом Istio, какие проблемы могут при...
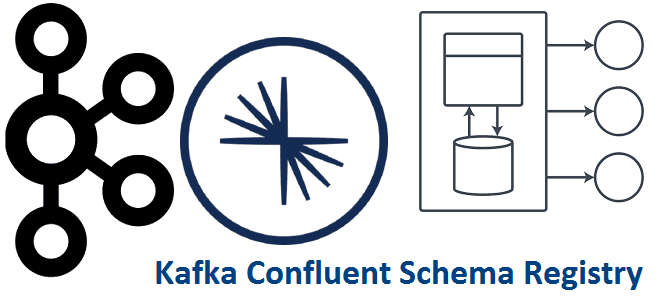
Мы уже рассказывали, что такое реестр схема Apache Kafka и зачем он нужен. Чтобы глубже разобраться с этой темой, важной для обучения разработчиков распределенных приложений и дата-инженеров, сегодня заглянем под капот Schema Registry и разберем работу этого компонента платформы Confluent Apache Kafka с продюсерами и потребителями. Еще раз про реестр...