
Эта статья открывает наш цикл посвященный бесплатному курсу лекций по "Apache Airflow для новичков" и закладывает фундамент для осовения всей темы. Мы разберемся, зачем вообще нужен оркестратор, как Airflow устроен внутри и как его запустить за пять минут, чтобы начать первые эксперименты. Архитектура и философия: почему Apache Airflow...

Как управлять топиками Kafka: полное удаление, очистка и аварийные сценарии Apache Kafka — мощный инструмент, но без должного ухода он быстро "захламляется". Топики, которые вы создавали для тестов, старые проекты или просто логи, со временем начинают занимать место и мешать. А иногда они разрастаются так, что кластер "ложится"...

Данные без контекста - это просто шум Представьте, что вы нашли старую пиратскую карту. На ней есть крестик, обозначающий сокровище. Но сама карта порвана, условные обозначения стерты, а масштаб неизвестен. Что вы будете делать с этой информацией? Ничего. Без контекста, без дополнительных данных о данных, эта карта -...

Business Intelligence — это не отчеты. Это компас для вашего бизнеса Представьте себя капитаном большого корабля в открытом море во время шторма. Как вы будете прокладывать курс? Полагаясь на интуицию и старые карты, нарисованные от руки? Возможно, вам повезет. Но скорее всего, вы налетите на рифы или заблудитесь. А теперь...

За пределами таблиц. Темная сторона корпоративных данных Представьте себе айсберг. Мы видим его верхушку, сияющую на солнце — она понятна, измерима и предсказуема. Это наши структурированные данные в базах и хранилищах. Но мы знаем, что 90% массы айсберга скрыто под водой. Точно так же и в мире корпоративной...

Введение. Цена молчания. Почему изолированные данные убивают ваш бизнес Мы с Вами сегодня поговорим об интеграции данных. Представьте себе человеческий организм. Мозг (руководство) принимает решения, руки (отдел продаж) выполняют задачи, голос (маркетинг) общается с миром, а ноги (логистика) обеспечивают движение. Все это работает слаженно благодаря центральной нервной системе, которая мгновенно...

Данные — не только актив, но и токсичный актив Почему защита и безопасность данных важна? В мире бизнеса принято говорить, что данные — это новый ценный актив, новая нефть. Это правда, но лишь наполовину. Гораздо честнее будет сказать так: данные — это как радиоактивное топливо для атомной станции. При...

Данные как океан. Где его хранить и как им управлять? Раньше, лет 15-20 назад, корпоративные данные были похожи на большое, но вполне обозримое озеро. Его можно было разместить в собственном "бассейне" — локальном дата-центре, и спокойно им управлять. Сегодня ситуация изменилась кардинально. Данные превратились в бескрайний, бушующий океан. Они...

Модель данных — язык, на котором бизнес говорит с технологиями Есть старая айтишная мудрость: "Написать код легко. Гораздо сложнее написать правильный код для правильной модели данных". И это абсолютная правда. Любую ошибку в коде можно исправить относительно безболезненно. А вот ошибка, заложенная в саму структуру данных, в модель, обходится...

Архитектура данных— невидимый фундамент вашего бизнеса Представьте, что вы решили построить небоскреб. С чего вы начнете? Вряд ли с выбора панорамных окон и покупки дорогой итальянской мебели для пентхауса. Любой здравомыслящий человек начинает с фундамента. С прочного, продуманного, железобетонного основания, способного выдержать вес сотен этажей, порывы ветра и даже...

Data Governance — не «Большой Брат», а правила дорожного движения Представьте себе оживленный мегаполис в час пик. Тысячи машин (данные) несутся по сложной сети дорог (IT-системы), управляемые разными водителями (сотрудники). А теперь вообразите, что в этом городе внезапно отключили все светофоры, убрали разметку, дорожные знаки и посты ДПС. Что...

Введение: Управление хаосом. Как выжить и преуспеть в цифровую эпоху Представьте, что данные в вашей компании — это ее центральная нервная система. Когда она работает слаженно, сигналы проходят мгновенно, решения принимаются быстро и точно, а весь организм — бизнес — становится гибким, умным и адаптивным. Он чувствует изменения на рынке...

В современном мире объём данных, генерируемых в реальном времени, растёт экспоненциально. По прогнозам, к 2025 году рынок аналитики real-time данных достигнет $38.6 миллиардов, что подчёркивает критическую важность их мгновенной обработки. В таких условиях традиционные batch-системы уступают место фреймворкам потоковой обработки, среди которых Apache Flink занимает лидирующие позиции благодаря своей производительности,...
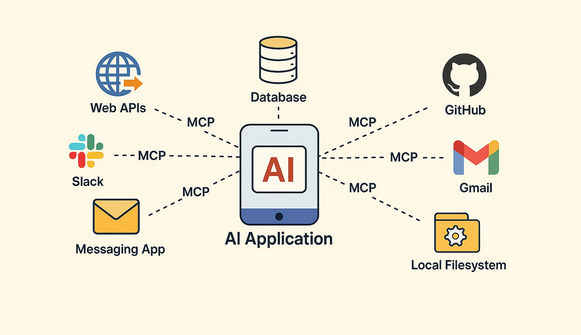
Model Context Protocol (MCP) — это открытый стандарт, разработанный для унификации взаимодействия между моделями искусственного интеллекта, особенно большими языковыми моделями (LLM), и внешними инструментами. До появления MCP интеграция ИИ с внешними API была сложной. Разработчикам приходилось писать уникальный код для каждого нового инструмента. Это замедляло разработку и создавало зависимость от...

Сан-Франциско, 29 июля 2025 г. — Технологический мир замер в ожидании самого масштабного обновления в области искусственного интеллекта за последние годы. По данным авторитетных изданий, включая The Verge и Reuters, компания OpenAI готовится выпустить свою следующую флагманскую модель, GPT-5, уже в первой половине августа этого года. Инсайдерская информация и...

Поздравляем! Если вы читаете эти строки, значит, вы прошли полный путь от первого изучения ClickHouse до понимания его самых глубоких механизмов. За эти десять статей мы превратились из новичков, задающихся вопросом "Что такое колоночная СУБД?", в уверенных пользователей, способных не только писать сложные аналитические запросы, но и проектировать, оптимизировать и...
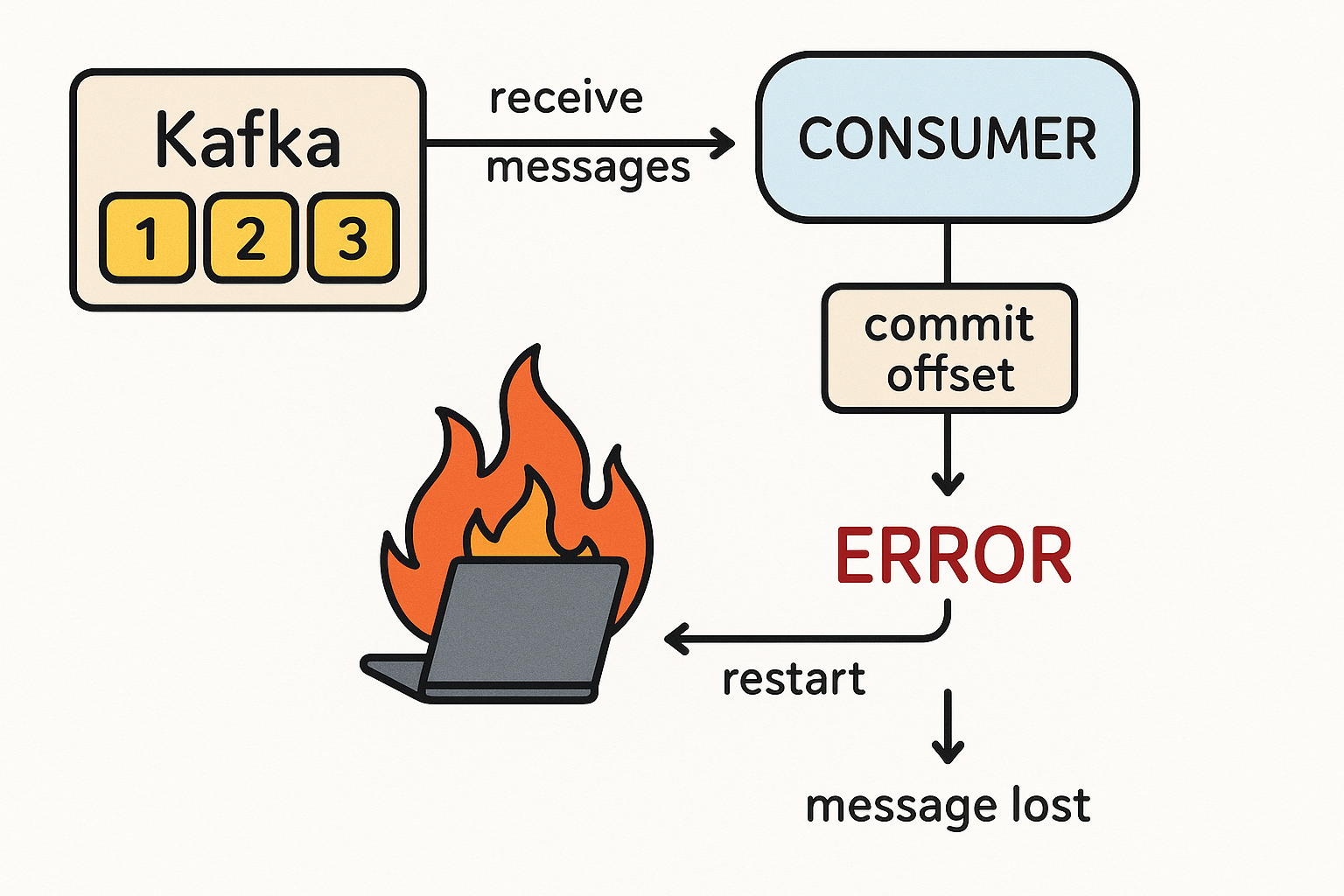
В мире распределенных систем, гарантии доставки сообщений, при передаче данных между сервисами — это фундаментальная задача. Но что происходит, когда мы отправляем сообщение из точки А в точку Б через сеть, которая по своей природе ненадежна? Сетевые задержки, сбои серверов, перезапуски приложений — все это может привести к потере или...

Мы с вами научились виртуозно писать запросы, строить сложные аналитические отчеты и интегрировать ClickHouse с другими системами. Но чтобы вся эта мощь работала стабильно и предсказуемо в production, кластер требует внимания и ухода. Написание запросов — это работа аналитика или разработчика, а поддержание здоровья системы — это задача администратора баз...
Оконные функции ClickHouse и работа с массивами данных. Мы с вами уже прошли большой путь: научились эффективно хранить данные, оптимизировать таблицы, выполнять базовые и сложные запросы и даже интегрироваться с внешними системами. Казалось бы, мы можем практически всё. Но как ответить на такие вопросы: "Каково время между последовательными действиями каждого...
До сих пор мы рассматривали ClickHouse как самостоятельную систему: создавали в нем таблицы и загружали данные. Однако в реальном мире данные редко живут в одном месте. Транзакционная информация находится в реляционных базах вроде MySQL или PostgreSQL, архивы логов — в объектных хранилищах типа Amazon S3, а потоки событий в реальном...