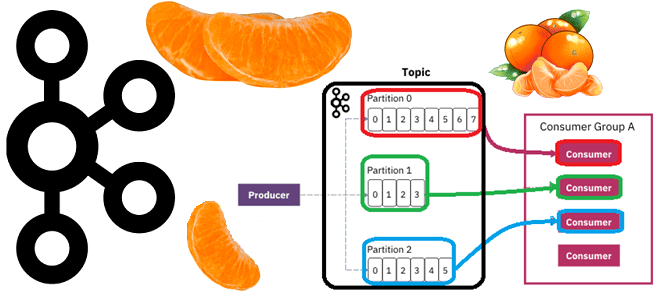
Почему раздел называется единицей параллелизма и как определить оптимальное число разделов в топике Apache Kafka в зависимости от количества потребителей и вариативности их поведения, разницы пропускной способности публикации и потребления сообщений, семантики партиционирования, толерантности к упорядоченности событий и ресурсных возможностей узла кластера. Что учитывать при разделении топика Apache Kafka Хотя...
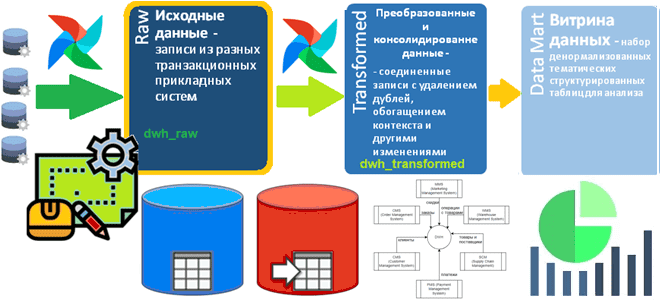
Как определить структуру Raw-слоя корпоративного хранилища данных: пример проектирования и DDL-скрипт для кейса электронной коммерции, выбор компонентов решения для архитектуры данных. Постановка задачи: анализ систем-источников Сегодня корпоративные хранилища данных (DWH, Data Warehouse) обычно реализуются в виде нескольких баз данных, связанных ETL-процессами. Причем каждая из этих гомогенных или гетерогенных, т.е. на...
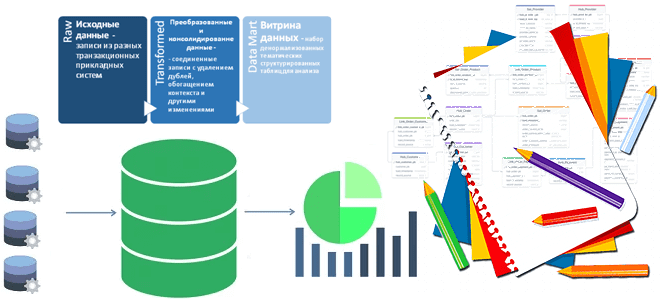
Как построить хранилище данных с подходом Data Vault: пример проектирования схемы данных и разработка DDL-скрипта для Transformed-слоя DWH интернет-магазина. Слоистая структура DWH и подход Data Vault Корпоративное хранилище данных (DWH, Data Warehouse) часто бывает гетерогенным, т.к. организованным с помощью нескольких баз данных, связанных ETL-процессами. Согласно концепции слоистой архитектуры (LSA, Layered...

Что такое гонка данных, почему она опасна в ETL-заданиях и как ее избежать: зачем разделять задания репликации в RAW-слой хранилища от их преобразования и сохранения в Transformed-слое DWH перед созданием витрин данных для BI-приложений. Что такое гонка данных в дата-инженерии Одна из главных особенностей распределенных систем – это задержка между...
29 января 2024 года вышла очередная веха 2-ой версии Apache NiFi, которая включает ряд новых функций и существенных обновлений зависимостей, а также несколько критических изменений. Рассмотрим самые интересные из них. Новые процессоры Apache NiFi 2.0.0-M2 С точки зрения управления версиями, веха рассматривается как некоторое значимое обновление, контрольная точка, меняющая дальнейшее...

Что такое graceful shutdown в Apache Kafka, когда используется такое плавное завершение работы, при чем здесь синхронизация реплик и как это влияет на плановые операции обслуживания кластера. Как работает механизм Graceful shutdown в Apache Kafka Благодаря множеству внутренних механизмов обеспечения отказоустойчивости, Apache Kafka имеет высокую надежность и позволяет строить нагруженные...

Почему тормозит Cypher-запрос к Neo4j, как его отладить и чем оператор PROFILE отличается от EXPLAIN. Краткий ликбез с примерами выполнения запросов к графовой базе данных для аналитиков и разработчиков. Как выполняются Cypher-запросы в Neo4j Любой дата-аналитик и разработчик, работающий с базами данных, знает, что одной из самых частых причин медленного...

От оркестрации и синхронизации конвейеров обработки данных до управления хранилищами, включая хранение состояний для stateful-приложений: сложности проектирования архитектуры потоковой обработки событий и способы их решения. Основные сложности проектирования современной архитектуры данных Из-за принципиальных отличий потоковой парадигмы обработки данных от пакетной, что разбиралось здесь, задача проектирования дата-конвейеров сильно усложняется, т.к. редко...

Как найти зависший процесс в базе данных Greenplum, создать резервную копию каталога, разделить лог-файл по тестам и проверить его на наличие повреждений. Знакомимся с набором утилит gpsupport. 6 инструментов утилиты gpsupport для техподдержки Greenplum Как и любая крупная система Greenplum, помимо компонентов, обеспечивающих ее ключевые функции, также включает дополнительные инструменты,...

Как с помощью Flink SQL организовать потоковую агрегацию данных из таблицы PostgreSQL: знакомство с API таблиц в Ververica Cloud на практическом примере. API таблиц Ververica Cloud: создаем внешние источники и приемники данных Как я недавно рассказывала, немецкая фирма Ververica создала высокопроизводительный облачный сервис для обработки данных в реальном времени на...
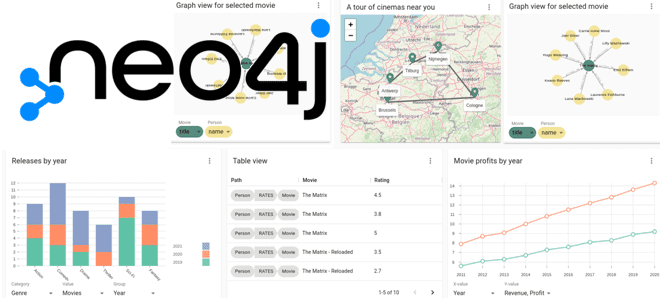
Создаем визуализации Cypher-запросов к своему графу в графовой базе данных Neo4j с помощью дэшборда NeoDash на примере анализа финансовых транзакций в банке. Python-генерация графа в Neo4j с фейковыми данными Поскольку NoSQL-СУБД Neo4j отлично подходит для задач графовой аналитики больших данных благодаря своей нативно графовой модели хранения данных, ее можно использовать...
Сегодня я покажу, как проверить доступность веб-сайта с помощью http-хука в Apache AirFlow и отправить результаты проверки в Телеграм-бот. Еще раз про хуки и соединения Apache AirFlow Доступность системы является ключевым свойством информационной безопасности. Проверить, что веб-сервис доступен, можно по статусу HTTP-ответа на GET-запрос. Чтобы делать такую проверку периодически, т.е....

Что такое WSL, Docker и как запустить веб-сервер Apache AirFlow в контейнере на локальной машине в Ubuntu поверх Windows вместо любимого Google Colab. Пошаговое руководство для начинающих дата-инженеров. Краткий ликбез по WSL и Docker для любителей Windows Обычно я всегда запускала веб-сервер Apache AirFlow в интерактивной среде Google Colab, которая...
Недавно я писала, как с помощью source-коннектора Debezium организовать потоковый захват изменения данных из таблицы PostgreSQL путем публикации CDC-событий в Apache Kafka. Продолжая эту тему, сегодня покажу пример визуализации аналитики этих данных в Kibana, предварительно загрузив их в Elasticsearch с sink-коннектором Aiven. Постановка задачи и проектирование конвейера Как обычно, в...
Зачем менять базу данных метаданных в производственном развертывании Apache AirFlow и как это сделать: пошаговое руководство для дата-инженера с примерами и рекомендациями. 5 шагов перехода от SQLLite к PostgreSQL: миграция базы данных метаданных Apache AirFlow Чтобы планировать и запускать конвейеры обработки данных, Apache AirFlow хранит сведения о задачах, DAG, исполнителях,...
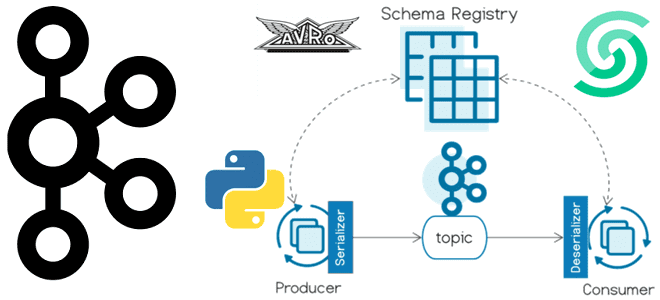
Сегодня я покажу пример использования реестра схем для Apache Kafka на платформе Upstash, API которого полностью совместим со Schema Registry от Confluent. Пишем продюсер на Python, используя библиотеку confluent_kafka. Еще раз о том, что такое реестр схем Kafka и чем он полезен Реестр схем (Schema Registry) – это модуль Confluent...

Когда журналирование событий может привести к OOM-ошибке, где отслеживать системные метрики приложения Apache Spark, зачем сжимать лог-файлы и как это сделать. Логирование системных метрик в приложении Apache Spark Поскольку фреймворк Apache Spark изначально предназначен для создания высоконагруженных распределенных приложений пакетной и потоковой обработки больших объемов данных, он позволяет отслеживать системные...
Зачем Databricks выпустил Arc, чем это отличается от Splink, и как эти инструменты позволяют решать проблему связывания данных с помощью алгоритмов машинного обучения. Как работает связывание данных Продолжая разговор про качество данных и разрешение сущностей (entity resolution) , сегодня подробно рассмотрим этап связывания записей с использованием логики на основе правил...
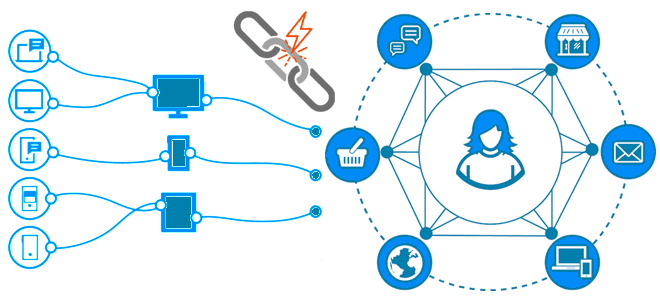
Как качество данных связано с разрешением сущностей, чем entity resolution отличается от identity resolution, зачем нужны графы идентичности, как их построить и где использовать. Борьба за качество данных с entity resolution Результаты аналитической обработки данных напрямую зависят от их качества, о ключевых показателях и задачах обеспечения которого мы писали здесь....
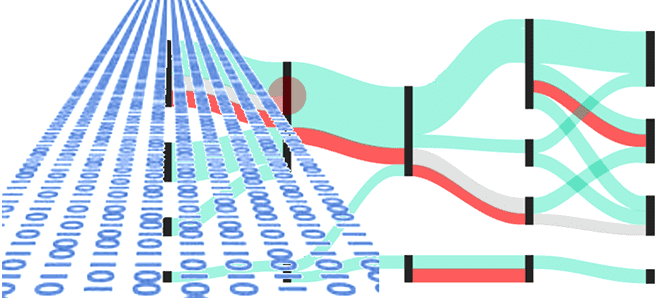
Чем пакетная парадигма обработки данных отличается от пакетной и как она реализуется на практике: принципы работы и воплощение в Big Data на примере Apache Spark, Kafka и Flink. Еще раз о разнице потоковой и пакетной парадигмы обработки данных Пакетная обработка и потоковая обработка — это две разные парадигмы обработки данных....