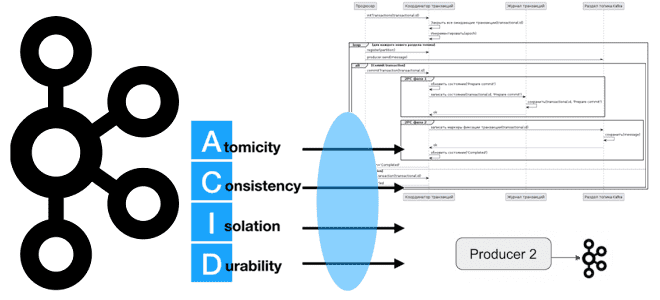
Как Apache Kafka реализует требование к атомарности транзакций с помощью координатора и журнала транзакций: принцип Atomic в ACID и его иллюстрация на UML-диаграмме последовательности публикации сообщений в раздел топика. Транзакционная публикация сообщений в Apache Kafka Хотя Apache Kafka не является базой данных, эта платформа потоковой передачи событий все же хранит...
Почему планировщик Apache AirFlow чувствителен к всплескам рабочих нагрузок, из-за чего тормозит база данных метаданных, как исправить проблемы с файлом DAG, лог-файлами и внешними ресурсами: разбираемся с ошибками пакетного оркестратора и способами их решения. Проблемы с планировщиком Хотя Apache AirFlow позиционируется как довольно простой фреймворк для оркестрации пакетных процессов с...
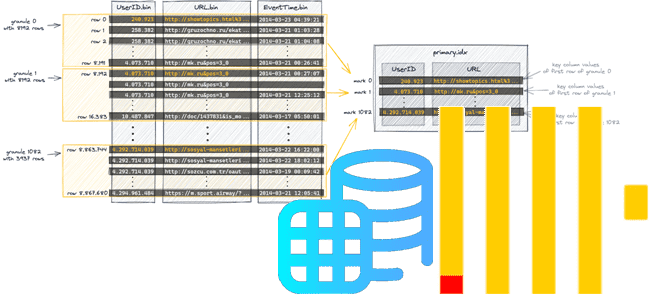
Как ClickHouse реализует разреженные индексы, что такое гранула, чем отличается широкий формат хранения данных от компактного, и почему значения первичного ключа в диапазоне параметров запроса должны быть монотонной последовательностью. Тонкости индексации в ClickHouse Индексация считается одним из наиболее известных способов повышения производительности базы данных. Индекс определяет соответствие значения ключа записи...
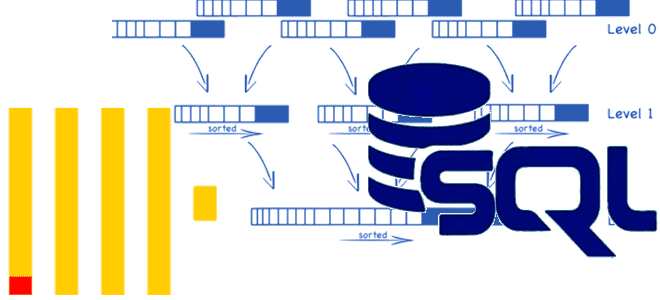
Что такое модификатор FINAL в SELECT-запросе ClickHouse, с какими табличными движками он работает, почему снижает производительность и как этого избежать. Тонкости потокового выполнения SQL-запросов в колоночной СУБД. Зачем в SELECT-запросе ClickHouse нужен модификатор FINAL? Хотя SQL-запросы в ClickHouse имеют типовую структуру, их реализация зависит от используемого движка таблиц. Например, запрос...

Школа Больших Данных проводит бесплатный митап для дата-инженеров, разработчиков и администраторов «Apache Spark на Kubernetes своими руками». Митап состоится 30 мая 2024 года в 17:00 МСК. Мероприятие рассчитано на инженеров данных, разработчиков и просто интересующихся. Специальной подготовки не требуется: неплохо немного уметь программировать на Python, но это не обязательно. В...

3 апреля стартовал прием заявок на участие в самом масштабном международном хакатоне «Лидеры цифровой трансформации». КАК ПРИНЯТЬ УЧАСТИЕ «Лидеры цифровой трансформации» – главное ИТ-событие, объединяющее талантливых специалистов из разных уголков мира. В рамках конкурса участники разрабатывают новые цифровые продукты и сервисы по запросу города, бизнеса и регионов. В хакатоне могут...
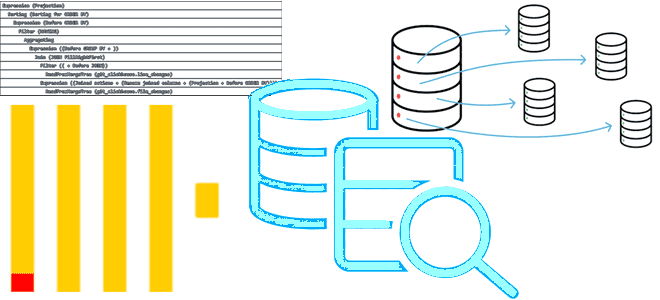
Как равномерно распределить по шардам ClickHouse уже существующие данные, зачем профилировать запросы, какие профилировщики поддерживает эта колоночная СУБД и каким образом их использовать. Ребалансировка шардов в ClickHouse Какой бы быстрой не была база данных, ее работу всегда хочется ускорить еще больше. Одним из популярных способов ускорения распределенной СУБД является шардирование...

Как прочитать данные из ClickHouse в Apache NiFi или загрузить их в таблицу колоночной СУБД: настройки подключения, использование процессоров и тонкости потоковой интеграции. Подключение к ClickHouse из Apache NiFi Как и интеграция ClickHouse с Apache AirFlow, связь этой колоночной СУБД с приложением NiFi реализуется с помощью решения сообщества, средствами самого...

Как расширить возможности Apache Flink с помощью дополнительных плагинов: подключение внешних ресурсов и обогащение отказов пользовательскими метками. Разбираемся с продвинутыми настройками для эффективной эксплуатации фреймворка. Внешние ресурсы Apache Flink Помимо процессора и памяти, многим рабочим нагрузкам также требуются другие ресурсы, например, графические процессоры для глубокого обучения. Для поддержки внешних ресурсов...
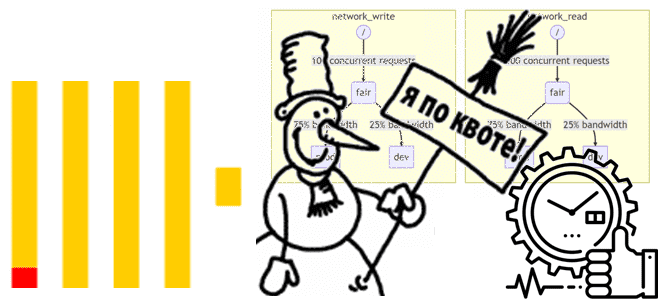
Как эффективно распределять и использовать ресурсы ClickHouse, зачем ограничивать возможности пользователей с помощью квот и классифицировать рабочие нагрузки. Управление ресурсами в ClickHouse Благодаря своей децентрализованной архитектуре ClickHouse, когда один экземпляр включает несколько серверов, к которым напрямую приходят запросы пользователей, эта колоночная СУБД работает очень быстро. Для репликации данных и выполнения...
Проблемы управления данными в мультиарендной среде или как Databricks решил изолировать клиентские приложения Apache Spark на общей виртуальной машине Java друг от друга и от самого фреймворка (драйвера и исполнителей). Знакомство с Lakeguard на базе каталога Unity. Проблемы управления данными в мультитенантной среде Компания Databricks не просто развивает и продвигает...
Практическая демонстрация потокового SQL-конвейера, который преобразует данные, потребленные из Apache Kafka, и записывает результаты в Elasticsearch, используя Debezium-коннекторы и задания Apache Flink в облачной платформе Decodable. Потребление сообщений из Apache Kafka Я уже показывала пример интеграции Apache Kafka и Elasticsearch с помощью sink-коннектора, а также конвейер с ClickHouse Cloud. Сегодня...
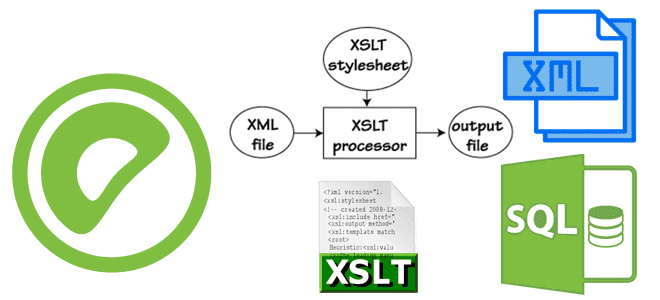
Как Greenplum хранит и обрабатывает XML-документы, зачем для этого нужны утилиты gpfdist и gpload, каковы их конфигурации для выполнения XSLT-преобразований XML-файлов и их загрузки/выборки во внешние таблицы MPP-СУБД. Работа с XML-документами и XSLT-преобразования в Greenplum Greenplum, как и PostgreSQL, также поддерживает работу со сложными типами данных и может вести себя...

Чем полезна интеграция ClickHouse с Apache Airflow и как ее реализовать: операторы в пакете провайдера и плагине на основе Python-драйвера. Принципы работы и примеры использования. 2 способа интеграции ClickHouse с AirFlow Продолжая разговор про интеграцию ClickHouse с другими системами, сегодня рассмотрим, как связать эту колоночную СУБД с мощным ETL-движком Apache...
От чего зависит задержка передачи данных из Apache Kafka в ClickHouse, как ее определить и ускорить интеграцию брокера сообщений с колоночной СУБД: настройки и лучшие практики. Интеграция ClickHouse с Kafka Чтобы связать ClickHouse с внешними системами, в этой колоночной СУБД есть специальные механизмы – интеграционные движки таблиц. Например, для взаимодействия...

Зачем устанавливать максимальный для каждого задания Apache Flink, для чего stateful-оператору пользовательский UUID, как выбрать подходящий бэкенд хранения состояний, от чего зависит оптимальный интервал создания контрольных точек и где настраивается высокая доступность менеджера заданий. 5 главных настроек перед запуском Flink-приложения в производственное развертывание Перед запуском приложения Apache Flink в производственное...
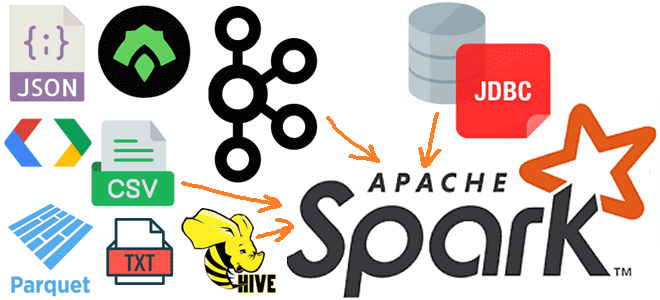
Какие источники исходных данных поддерживает Apache Spark для пакетной и потоковой обработки, обеспечивая отказоустойчивые вычисления в большом масштабе средствами SQL и Structured Streaming. Источники данных Apache Spark SQL и структурированной потоковой передачи Будучи фреймворком для создания распределенных приложений обработки больших объемов данных, Apache Spark может подключаться к разным источникам этих...
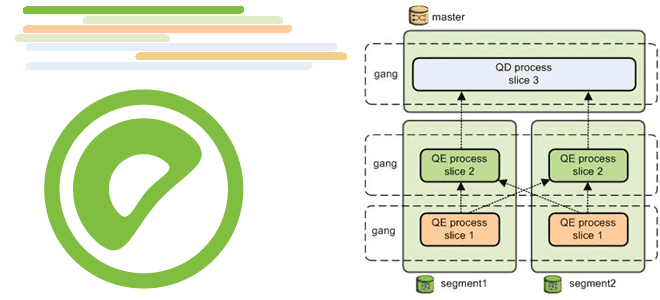
Как координатор Greenplum на мастер-хосте рассылает сегментам планы выполнения запросов, что такое курсор параллельного получения результатов оператора SELECT и каким образом его использовать для аналитики больших данных в этой MPP-СУБД. Особенности рассылки планов SQL-запросов в Greenplum на выполнение Хотя Greenplum основана на PostgreSQL, некоторые механизмы работы этих СУБД отличаются. Например,...
Как эффективно распределять и использовать ресурсы ClickHouse, зачем ограничивать возможности пользователей с помощью квот и классифицировать рабочие нагрузки. Управление ресурсами в ClickHouse Благодаря своей децентрализованной архитектуре ClickHouse, когда один экземпляр включает несколько серверов, к которым напрямую приходят запросы пользователей, эта колоночная СУБД работает очень быстро. Для репликации данных и выполнения...

Чем кэширование в OLAP-системах отличается от OLTP и как устроен кэш запросов ClickHouse: принципы работы, конфигурационные настройки и примеры использования SELECT-оператора. Особенности кэширования в ClickHouse Кэширование является одним из методов повышения производительности, который сокращает время на получение результатов вычислений за счет их хранения в области быстрого доступа. Обычно кэшируются результаты...