
В этой статье рассмотрим 2 способа физической группировки данных для ускорения последующей обработки в Apache Hive и Spark: партиционирование и бакетирование. Чем они отличаются друг от друга, что между ними общего и какой рост производительности дает каждый из методов в зависимости от задач аналитики больших данных средствами Spark SQL. Еще...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим, что такое DataStax Enterprise Graph. Читайте далее, как немецкая ИТ-компания Traversals с помощью этой распределенной графовой СУБД построила масштабное аналитическое решение для кибербезопасности, обнаружения мошенничества, анализа конкурентов и оповещения клиентов в реальном времени. Также разберем, при...

Сегодня в качестве полезного примера для обучения дата-инженеров и разработчиков Spark-приложений, разберем кейс компании Pinterest по интерактивной аналитике больших данных средствами SQL-модуля этого популярного фреймворка. Читайте далее, почему дата-инженеры решили заменить HiveServer2 на Spark Thrift JDBC/ODBC, зачем понадобилось писать собственный клиент поверх Apache Livy и как это было сделано. Зачем...
В недавней статье про преимущества хранилища метаданных Apache Hive и другие плюсы этого популярного инструмента SQL-on-Hadoop, мы упоминали формат открытых таблиц Iceberg как альтернативу для хранения огромных наборов аналитических данных. Он добавляет высокопроизводительные SQL-подобные таблицы в вычислительные механизмы Spark, Trino, Presto, Flink и Hive. Сегодня рассмотрим подробнее, что такое Apache Iceberg и...

В продолжение недавней статьи для дата-инженеров про альтернативные платформы потоковой передачи событий вместо Apache Kafka, сегодня рассмотрим пример аналитики больших данных средствами Flink SQL, записи результатов в Elasticsearch и их визуализации в Kibana. Читайте далее, чем Redpanda отличается от Kafka, а Flink – от Apache Spark с точки зрения потоковой...

В рамках обучения разработчиков Spark-приложений, аналитиков данных и дата-инженеров, сегодня рассмотрим, как улучшить и визуализировать понимание обработки данных в этом Big Data фреймворке. Читайте далее про API встроенных механизмов наблюдения за качеством данных в Apache Spark и открытые библиотеки профилирования на примере Deequ. 2 уровня абстракции мониторинга Spark-приложений для дата-инженера...

Анализ данных в рамках пользовательский сеансов (сессий) – довольно востребованный кейс в Apache Spark, который не так просто реализовать из-за особенностей потоковой и пакетной обработки, а также эксплуатационных расходов. Сегодня рассмотрим, как работают сеансовые окна Spark Structured Streaming и каковы ограничения этого фреймворка. Что такое сеансовые окна: краткий ликбез по...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...

В этой статье для дата-инженеров рассмотрим кейс компании PayPal, которая переводит свои аналитические рабочие нагрузки из локального кластера Apache Spark в Google Cloud Processing. Читайте далее, чем это решение оказалось лучше выполнения Spark-заданий в кластере DataProc с использованием данных BigQuery и облачного хранилища Google (GCS, Google Cloud Storage) для потоковой...

Продвигая наш новый курс по графовым алгоритмам на больших данных, сегодня рассмотрим, почему концепция графов сегодня так востребована в Big Data и Machine Learning. Вас ждет краткий ликбез по модулю GraphX в Apache Spark и его отличия от API GraphFrames, а также особенности кластерной обработки и сохранения данных графа свойств....
В этой статье для разработчиков Spark-приложений и дата-аналитиков рассмотрим новый оптимизатор этого фреймворка, Radiant. Он основан на SQL-оптимизаторе Catalyst и представляет собой open-source проект от энтузиастов сообщества Apache Spark. Читайте далее, чем хорош Spark-Radiant и как использовать его для оптимизации SQL-запросов при аналитике больших данных. Что такое SQL-оптимизатор Spark-Radiant и...
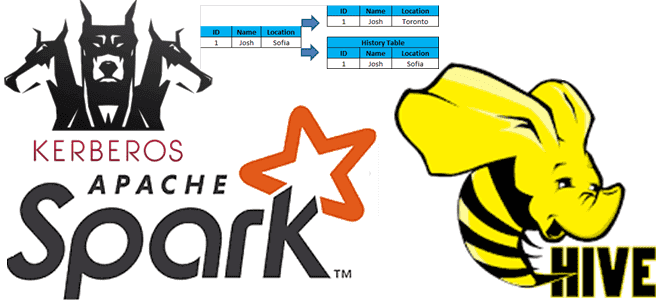
В этой статье для разработчиков распределенных приложений Apache Spark, администраторов SQL-on-Hadoop и дата-аналитиков рассмотрим особенности аутентификации удаленного пользователя, а также отслеживание измененных данных в таблицах Apache Hive. Читайте далее, зачем ограничивать доступ к keytab-файлу в кластерах с поддержкой защищенного протокола Kerberos, а также как реализовать отслеживание медленно меняющихся измерений в...

В рамках обучения разработчиков Spark-приложений, сегодня рассмотрим, как сохранить датафрейм в памяти вне кучи исполнителя и зачем это нужно. Вас ждет краткий ликбез по управлению памятью в Apache Spark с описанием настраиваемых конфигураций. Также на простом практическом примере разберем, как это сделать и где в пользовательском веб-интерфейсе фреймворка посмотреть результаты...

В этой статье для дата-инженеров мы собрали лучшие практики построения масштабируемых конвейеров обработки данных, а также популярные рекомендации по проектированию ETL/ELT-процессов с Apache Spark, AirFlow и другими технологиями Big Data. Читайте далее, когда ELT лучше ETL и наоборот, чем хорош Apache Spark в конвейерах обработки Big Data, зачем нужен AirFlow,...

При том, что Apache Spark является одной из главных технологий стека Big Data, этот фреймворк не очень хорошо работает с множеством файлов небольшого размера. Поэтому в рамках обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, почему это происходит, зачем динамически сжимать файлы в Apache Spark и как это делает платформа...

Сегодня разберем кейс компании Renault по масштабированию своей цифровой платформы и снижению затрат с помощью BigQuery и Apache Spark на Google Dataproc. Цифровизация в автомобильной промышленности: конвейер сбора и аналитики больших данных с производства средствами Google сервисов и снижение затрат на облако в 2 раза через изменение конфигурации Spark SQL....

В рамках курсов для дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим пример построения системы потоковой передачи для аналитики больших данных на базе Apache Kafka, Spark и Google BigQuery. Читайте далее про Proof of Concept для конвейера продуктовой аналитики, который обрабатывает 50 миллиардов событий каждый день, и какие важные уроки ИТ-архитектор...

YARN считается самым распространенным диспетчером ресурсов в кластерах Apache Hadoop и Spark, отвечая за выделение ресурсам распределенным приложениям. Сегодня в рамках обучения дата-инженеров и администраторов Hadoop рассмотрим достоинства и недостатки 3-х вариантов планирования ресурсов в YARN. Читайте далее, что такое иерархия очереди и как вычисляется ее мгновенная справедливая доля. Планирование...

Сегодня в рамках обучения дата-аналитиков и разработчиков Spark-приложений, рассмотрим еще несколько особенностей этого фреймворка. Почему count() работает по-разному для RDD и DataFrame, как отличается уровень хранения при применении метода cache() для этих структур, когда использовать SortWithinPartitions() вместо sort(), а также парочка тонкостей обработки Parquet-таблиц в Spark SQL и кэширование метаданных...

Специально для разработчиков распределенных приложений, Data Scientist’ов и аналитиков больших данных, работающих с Apache Spark, в этой статье мы собрали несколько полезных советов по ежедневным операциям в этом фреймворке. Читайте далее, как добавить библиотеку TypeSafe в файл sbt-конфигурации Spark-приложения, получить датафреймы из JSON-массивов и структур, а также обработать CSV-формат с...