
Недавно мы писали про чтение данных из AWS S3 с помощью PySpark-задний. Продолжая разбираться, как перейти от HDFS к облачным объектным хранилищам, сегодня рассмотрим пример чтения и записи файлов из Google Cloud Storage с помощью Apache Spark. От HDFS к GCS Распределенная файловая система Apache Hadoop (HDFS) уже много лет...

Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью...

Можно ли применять Apache Spark Structured Streaming для пакетных заданий и в каких случаях это целесообразно. Разбираемся, как устроена потоковая передача событий в Spark Structured Streaming, с какой частотой разные режимы триггеров микропакетной обработки данных запускают потоковые вычисления и что выбрать дата-инженеру. Потоковая передача событий и пакетные задания: versus или...
В июле 2022 года на конференции Data and AI Summit компания Databricks представила новый проект для экосистемы Apache Spark под названием Spark Connect. Что это такое и как оно пригодится разработчикам распределенных приложений и дата-инженерам, читайте далее. Что не так с Apache Spark и зачем нужен новый проект Databricks Появившись...

Сегодня мы продолжим говорить про Apache Spark Structured Streaming и его применение для обновления данных в таблицах Delta Lake. А также на практических примерах разберем, как выполняются основные операции работы с данными средствами Spark Structured Streaming API. Таблицы в Delta Lake Delta Lake – это уровня хранилища данных с открытым...

Продолжая недавний разговор про Apache Spark Structured Streaming, сегодня рассмотрим, как этот движок потоковой обработки данных помогает дата-инженеру реализовать идемпотентную запись в таблицы Delta Lake, а также выполнить операции слияния и обновления/вставки в помощью метода foreachBatch(). Идемпотентность потоковых приложений Apache Spark Идемпотентность – важное свойство распределенных систем, которое гарантирует, что...

Разработка высоконагруженных систем потоковой аналитики больших данных включает не только написание кода, но и его оптимизацию. Поэтому разработчикам приложений Apache Spark Structured Streaming и дата-инженерам полезно знать, как можно повысить эффективность своих Big Data систем. В этой статье мы рассмотрим конфигурации и приемы, которые могут ускорить пакетные и потоковые вычисления....
Мы уже писали про использование криптографии в Apache Spark. Сегодня в рамках обучения дата-инженеров и разработчиков распределенных приложений рассмотрим, как шифровать столбцы датафрейма в PySpark и расшифровывать их с использованием алгоритма шифрования AES. Основы кибербезопасности: ликбез по шифрованию данных Шифрование данных преобразует данные в другую форму или код, чтобы их...
Рассмотрим, как дата-инженеры Airbnb делятся своим опытом перевода корпоративного Data Lake на Apache HDFS в облачное объектное хранилище AWS S3. Почему пришлось переводить аналитические нагрузки с Apache Hive на Iceberg и Spark, и какие результаты это принесло. Предыстория: Data Lake на HDFS и Apache Hive Будучи крупнейшей онлайн-площадкой для размещения...
Сегодня разберем тему, важную для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Почему чтение данных из реляционных баз в Apache Spark может быть медленным и как его ускорить, изменив SQL-запрос или структуру таблицы. JDBC-источники данных для Apache Spark Apache Spark является средством обработки, а не хранения больших данных. Поэтому, чтобы использовать...

Сегодня рассмотрим важную тему для обучения дата-инженеров и разработчиков распределенных Spark-приложений. Как устроена потоковая обработка данных в Apache Spark Structured Streaming, зачем нужны водяные знаки и с какими сложностями при этом можно столкнуться. Как работают водяные знаки в потоковой передача событий Apache Spark Библиотека потоковой обработки событий Structured Streaming основана...

Чтобы добавить в наши практические курсы по Apache Spark еще больше приемов, полезных для дата-инженеров и разработчиков, сегодня рассмотрим, как упаковать PySpark-приложение, используя нативные Python-функции и сторонние решения. Отличия Virtualenv от PEX и Conda. 4 способа упаковать PySpark-приложение для запуска в кластере Apache Spark Разработчики распределенных приложений знают, что недостаточно...
При том, что большинство современных озер данных представляют собой облачные объектные хранилища типа AWS S3, многие предприятия хранят данные в собственном кластере HDFS или даже MinIO. Поэтому сегодня специально для обучения дата-инженеров и ИТ-архитекторов рассмотрим, что представляет собой это хранилище и насколько хорошо с ним взаимодействует Apache Spark. Что такое...
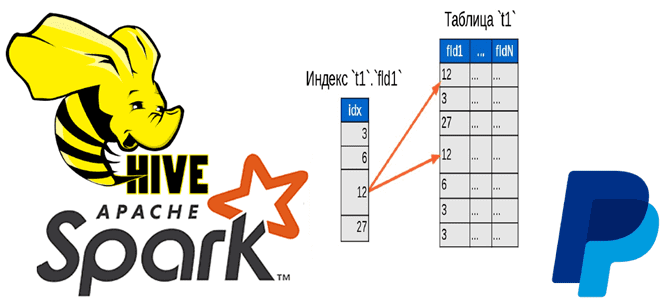
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро. Трудности бакетирования в Hive и Spark Вычислительный движок Apache Spark отлично...

Мы уже писали, что технологии Big Data ориентированы на работу с большими данными, а не множеством маленьких. Сегодня рассмотрим подробнее, почему Apache Hadoop, Spark и основанные на HDFS NoSQL-СУБД Hive и HBase плохо работают с большим количеством маленьких файлов, а также как это исправить. Почему HDFS плохо работает со множеством...

Мы регулярно добавляем в наши курсы по Apache Flink и Spark для дата-инженеров полезные материалы и инструменты, которые помогают повысить эффективность разработки и эксплуатации приложений аналитики больших данных. Читайте далее, что такое SeaTunnel и как эта высокопроизводительная платформа интеграции распределенных данных упрощает их потоковую синхронизацию средствами SQL-заданий Apache Flink и...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, что такое динамическое партиционирование таблиц в Apache Spark, зачем это нужно и как реализовать такие вставки разделов. Разбираем на практическом примере. Что такое динамическое партиционирование в Apache Spark Партиционирование – это разделение данных на основе значения столбца и их сохранение...

В отличие от каменных зданий, архитектуры данных постоянно меняются. Сегодня рассмотрим новую архитектурную модель под названием BigLake, выпущенную Google весной 2022 года. Что это такое, как устроено, чем похоже на Lakehouse, озеро данных и Data Mesh, а также чем от них отличается и какую пользу несет для конвейеров аналитики Big...

Сегодня рассмотрим особенности использования оператора LIMIT в Spark SQL: как он выполняется и почему вместо него лучше использовать оператор TABLESAMPLE. Для этого в рамках обучения дата-инженеров, разработчиков распределенных приложений и аналитиков данных заглянем под капот оптимизатора Catalyst в Apache Spark и сравним физические планы выполнения SQL-запросов. Недостатки оператора LIMIT в...

Недавно мы писали про Lakesoul – новое унифицированное решение для хранения потоковых и пакетных таблиц, которое реализует архитектуру данных LakeHouse. Сегодня заглянем под капот этого унифицированного механизма на базе Apache Spark и разберемся с преимуществами его последнего релиза. Как работает LakeSoul: краткий обзор Напомним, LakeSoul от команды DMetaSoul представляет собой...