
Сегодня познакомимся с сервером истории Apache Spark: зачем он нужен, как работает и при чем здесь слушатели событий. Отладка и мониторинг распределенных приложений для дата-инженера в веб-GUI. Что такое сервер истории Apache Spark Каждый раз при запуске Spark-приложения его контекст SparkContext запускает веб-интерфейс по умолчанию на порту 4040. Если несколько...

Как разработчику выбрать подходящий режим развертывания для своего Spark-приложения, достоинства и недостатки клиентского и кластерного режимов, а также особенности запуска под управлением YARN. Архитектура и режимы развертывания Spark-приложения Будучи фреймворком для создания приложений быстрой обработки Big Data, Apache Spark имеет несколько режимов развертывания, которые зависят от варианта запуска Spark-приложения: на...
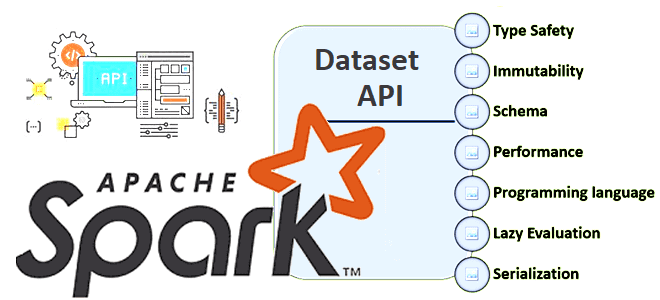
В Apache Spark есть 3 структуры данных, каждая из которых имеет собственный API со своими достоинствами и недостатками. Сегодня разберем плюсы и минусы Dataset API, а также рассмотрим особенности JOIN-операций в нем. Почему Dataset API в Apache Spark работает только со Scala и Java Напомним, структура данных Dataset впервые появилась...
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...
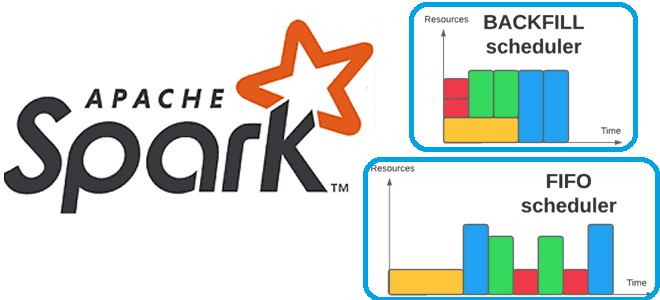
Что такое backfill-операции в конвейерах заданий Apache Spark, чем они отличаются от исторического заполнения датасетов, зачем их автоматизировать и как это сделать. Что такое backfilling для заданий Apache Spark Мы уже писали про понятие backfill на примере модификации DAG при добавлении новых заданий в конвейер Apache AirFlow. Эта функция полезна,...

Как организовать эффективное планирование заданий Apache Spark в микросервисной архитектуре, управляемой событиями, с помощью паттернов Idempotent Consumer и Transactional Outbox. Проблемы оркестрации Spark-заданий shell-скриптами и переход к EDA-архитектуре При большом количестве приложений Apache Spark, которые взаимодействуют друг с другом как самостоятельные микросервисы, растет сложность управления ими. В частности, shell-скрипты позволяют...

Чтобы сделать наши курсы для дата-инженеров и разработчиков распределенных приложений еще более полезными, сегодня мы расскажем про новый бесплатный сервис от маркетплейса Joom для поиска проблем с производительностью Spark-заданий. Разбираемся, как он работает и чем полезен дата-инженеру. 4 главных проблемы Spark-приложений, их последствия и трудности обнаружения Если количество Spark-приложений невелико,...

Как MLOps-инженеры платформы онлайн-курсов Udemy ускорили цикл разработки и внедрения проектов машинного обучения, используя возможности Amazon SageMaker для создания и отладки Spark-приложений в удаленном облачном кластере. MLOps на AWS Чтобы воспользоваться преимуществами бесшовной интеграции процессов разработки и развертывания машинного обучения согласно концепции MLOps, совсем не обязательно выстраивать собственную платформу из...

Как использовать преимущества графических процессоров для Spark-приложений аналитики больших данных и машинного обучения с помощью библиотек RAPIDS. Знакомимся с ускорителем Spark RAPIDS и его возможностями сделать популярный вычислительный движок еще быстрее. Что такое RAPIDS Accelerator для Apache Spark и как он работает Системы Machine Learning, особенно проекты глубокого обучения, уже...

Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh. Что такое Delta Sharing и при чем здесь Data Lake Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и...

Как повысить скорость выполнение SQL-запросов в Spark-приложениях, используя Gluten – новый вычислительный движок, объединяющий несколько векторизированных механизмов выполнения с поддержкой аппаратных ускорителей. Что такое Gluten и как он появился в Apache Spark Когда данных много, их обработка может длиться долго. Чтобы ускорить вычисления с Big Data, разработчики распределенных приложений и...
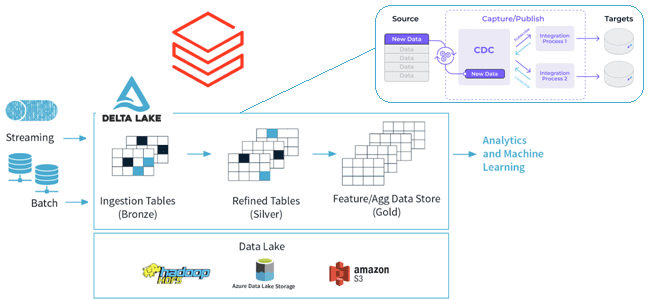
Как реализовать CDC для Delta Lake: разбираемся с функцией Change Data Feed от Databricks, которая позволяет быстро узнать обо всех изменениях строк в дельта-таблицах озера данных. Польза и принципы работы CDF для дата-инженера и архитектора данных. CDC для Delta Lake Идея сбора и обработки не всего объема данных, а только...

Мы уже писали, как ускорить выполнение заданий Spark SQL по чтению данных из JDBC-источников. В продолжение этой важной темы для обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, зачем настраивать опции функции spark.read() и как это сделать наиболее эффективно. Скорость выполнения SQL-запросов и параметры чтения данных из JDBC-источников в Apache...

Чем задание в Spark-приложениях отличается от задачи, зачем нужны этапы и при чем здесь драйверы с исполнителями. Разбираемся с основами разработки в самом популярном движке для распределенных вычислений: ликбез для дата-инженеров. Основные концепции Spark-приложений Приложение Spark — это программа, созданная с помощью Spark API и работающая в совместимом с этим...

Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark...
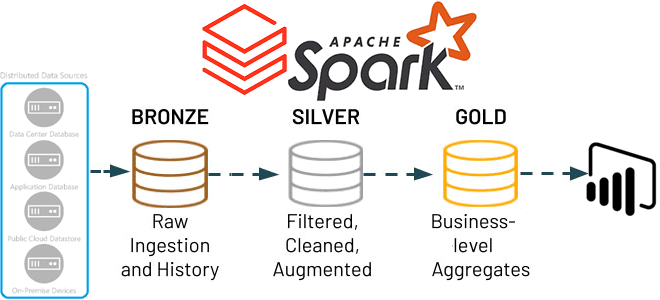
В этой статье для обучения дата-инженеров и ИТ-архитекторов рассмотрим, как Apache Spark Structured Streaming помогает реализовать самообслуживаемый сервис потоковой передачи данных в Delta Lake. А также вспомним каноническую 3-хслойную модель этого уровня хранения от Databricks. Много потоковых сценариев в одном приложении Apache Spark Structured Streaming Мы недавно писали, что архитектуры,...

Специально для обучения дата-инженеров и разработчиков распределенных программ, сегодня рассмотрим подходы к организации модульного тестирования Spark-приложений через классы тестовых данных. Зачем и как генерировать эти классы, где их хранить и при чем здесь система автоматической сборки приложений Gradle. Сборка и тестирование Spark-приложений Модульное тестирование лежит в основе проверки работоспособности программного...

Как Apache Spark организует параллельные вычисления, зачем нужны аккумуляторы и каким образом они помогают организовать мониторинг качества данных в аналитических конвейерах их обработки. Смотрим с точки зрения дата-инженера и разработчика распределенных приложений. Как Apache Spark распараллеливает обработку данных Параллельная обработка — это метод вычислений, при котором работает более одного ЦП...

В этой статье для обучения дата-инженеров и разработчиков распределенных приложений, сегодня разберем опыт ИТ-компании Similarweb, где Apache Spark на платформе Databricks вместо AWS Athena ускорил пакетную обработку данных в 50 раз. Также рассмотрим приемы повышения производительности ODBC-драйвера Databricks для улучшенного взаимодействия с озерами данных. Постановка задачи и ограничения POC для...

Учитывая рост интереса к DevOps-инструментам, сегодня рассмотрим, зачем переводить кластер Apache Spark, управляемый YARN, в Kubernetes, и как это сделать наиболее эффективно. А также разберем, какие системные метрики контейнерных Spark-приложений надо отслеживать и с помощью каких средств. Зачем переводить кластер Apache Spark от YARN на Kubernetes Apache Spark не зря...