
В продолжение темы про новое в экосистеме Apache Hadoop, сегодня мы расскажем о проекте Ozone: как и зачем появилось это масштабируемое распределенное хранилище объектов, чем оно отличается от HDFS, что у него общего с Amazon S3 и как этот фреймворк позволяет совместить преимущества SaaS-подхода с локальными кластерами Big Data. ...

В последнее время в мире Big Data все меньше можно услышать новостей про Apache Hadoop. Сегодня рассмотрим, почему мифы о смерти Хадуп – это всего лишь мифы и как будет развиваться эта мощная экосистема хранения и обработки больших данных в будущем. Читайте в нашей статье про слияния и поглощения ведущих...

Обработка естественного языка (Natural Language Processing, NLP) является перспективным направлением Data Science и Big Data. Сегодня мы расскажем вам о применении методов NLP в PySpark. В этой статье вы узнаете об обычной токенизации и на основе регулярных выражений, стоп-словах русского и английского языков, а также о N-граммах в PySpark. Токенизация...

Сегодня поговорим про сохранение состояний при потоковой обработке больших данных с помощью Apache Spark и рассмотрим особенности Structured Streaming в новой версии этого популярного Big Data фреймворка. Читайте далее про Stateless и Stateful приложений в реальном времени, управление состояниями, связь DStream с RDD и UI в Spark Structured Streaming. Состояния в...

Вчера мы рассказывали про нововведения в Apache Spark 3.0 и упомянули про улучшения в SparkR. Сегодня рассмотрим, почему в новой версии фреймворка вызов пользовательских функций стал быстрее в 40 раз и какие еще проблемы работы с R были решены в этом релизе. Что не так со SparkR: десериализация и особенности...

Чтобы сделать наши курсы по Spark еще более интересными и добавить в них самые актуальные тренды, сегодня мы расскажем о новом релизе этого Big Data фреймворка. Читайте далее, что нового в Apache Spark 3.0 и почему Spark SQL стал еще лучше. 10 лет в Big Data или немного истории В...
В прошлый раз мы говорили о решении задачи классификации в рамках Machine Learning с помощью PySpark MLlib. Сегодня рассмотрим задачу регрессии. Читайте далее: что такое линейная регрессия, L1 и L2 регуляризация, алгоритм подбора значений гиперпараметров Grid Search, а также применение кросс-валидации в PySpark. Датасет с домами на продажу Обучать модель...

PySpark позволяет работать не только с большими данными (Big data), но и создавать модели машинного обучения (Machine Learning). Сегодня мы расскажем вам о модуле ML и покажем, как обучить модель Machine Learning для решения задачи классификации. Читайте у нас: подготовка данных, применение логистической регрессии, а также использование метрик качеств в...

При всех своих достоинствах Delta Lake, включая коммерческую реализацию этой Big Data технологии от Databricks, оно обладает рядом особенностей, которые могут расцениваться как недостатки. Сегодня мы рассмотрим, чего не стоит ожидать от этого быстрого облачного хранилище для больших данных на Apache Spark и как можно обойти эти ограничения. Читайте далее,...

Продолжая разговор про Delta Lake, сегодня мы рассмотрим, чем это быстрое облачное хранилище для больших данных в реализации компании Databricks отличается от классического озера данных (Data Lake) на Apache Hadoop HDFS. Читайте далее, как коммерческое Cloud-решение на Apache Spark облегчает профессиональную деятельность аналитиков, разработчиков и администраторов Big Data. Больше, чем...

Озеро данных (Data Lake) на Apache Hadoop HDFS в мире Big Data стало фактически стандартом де-факто для хранения полуструктурированной и неструктурированной информации с целью последующего использования в задачах Data Science. Однако, недостатком этой архитектуры является низкая скорость вычислительных операций в HDFS: классический Hadoop MapReduce работает медленнее, чем аналоги на Apache...

В прошлый раз мы говорили о том, как установить PySpark в Google Colab, а также скачали датасет с помощью Kaggle API. Сегодня на примере этого датасета покажем, как применять операции SQL в PySpark в рамках анализа Big Data. Читайте далее про вывод статистической информации, фильтрацию, группировку и агрегирование больших данных...

Самообслуживаемая аналитика больших данных – один из главных трендов в современном мире Big Data, который дополнительно стимулирует цифровизация. В продолжение темы про self-service Data Science и BI-системы, сегодня мы рассмотрим, что такое Cloudera Data Science Workbench и чем это зарубежный продукт отличается от отечественного Arenadata Analytic Workspace на базе Apache...

Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при...
Недавно мы рассказывали, что такое PySpark. Сегодня рассмотрим, как подключить PySpark в Google Colab, а также как скачать датасет из Kaggle прямо в Google Colab, без непосредственной загрузки программ и датасетов на локальный компьютер. Google Colab Google Colab — выполняемый документ, который позволяет писать, запускать и делиться своим Python-кодом через...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
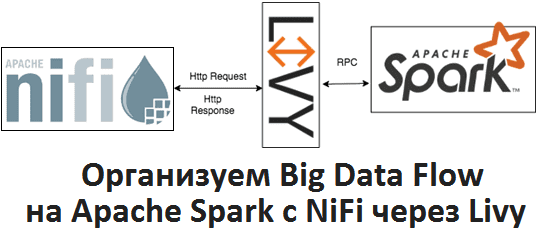
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...

Продолжая разговор про Apache Livy, сегодня мы сравним этот REST API для Spark c другой популярной Big Data системой планирования рабочих процессов для управления заданиями Hadoop – Oozie. Читайте в нашей статье, что такое Apache Oozie, чем он похож на Livy и в чем между ними разница, а также когда...
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Сегодня поговорим про построение конвейеров обработки данных (data pipeline) на примере совместного использования Apache Spark с Airflow и рассмотрим типовые проблемы этой комбинации. Читайте в нашей статье, как автоматизировать задачи пакетной и потоковой обработки больших данных (Big Data) с помощью гибкого REST-API Apache Livy, включая работу с Python-кодом, отказоустойчивость и...