 1030
1030 
Содержание
Сложности развертывания контейнерных stateful-приложений и как их решить с Argo Rollouts и Kubernetes Downward API: примеры YAML-конфигураций канареечного развертывания Spark-приложения.
Расширение стратегий развертывания в Kubernetes с Argo Rollouts
Мы уже писали, в чем сложности оркестрации параллельных заданий на платформе Kubernetes и как их можно решить с помощью Argo Workflows — контейнерного движка рабочих процессов с открытым исходным кодом. Однако, помимо Argo Workflows, в экосистеме Argo есть еще один полезный инструмент, который пригодится для управления контейнерными распределенными приложениями — Argo Rollouts. Это контроллер Kubernetes, который включает набор пользовательских определений ресурсов (CRD, Custom Resource Definition) для реализации расширенных возможностей развертывания приложений в Kubernetes, в т.ч. сине-зеленое и канареечное развертывание. Подробнее про стратегии развертывания мы писали здесь. В Kubernetes есть объект Deployment, который позволяет разработчикам автоматически развертывать приложения на узлах кластера этой платформы управления контейнерными приложениями. Однако, в объекте Deployment отсутствуют популярные стратегии развертывания, в частности, сине-зеленое и канареечное. Argo Rollouts, реализованный как Kubernetes CRD, расширяет объекта Deployment, позволяя использовать эффективные стратегии развертывания. По умолчанию он поддерживает только одну службу/приложение. Однако, это можно исправить, изменив соответствующие настройки.
Пример конфигурации Argo Rollouts для развертывания новой версии Spark-приложения с использованием стратегии канареечного развертывания может выглядеть как следующий YAML-файл:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: spark-app
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: spark-app
template:
metadata:
labels:
app: spark-app
spec:
containers:
- name: spark-container
image: my-spark-app:2.0 # Текущая версия приложения
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
strategy:
canary:
steps:
- setWeight: 20 # Отправка 20% трафика на новую версию
- pause:
duration: 60s # Пауза для мониторинга
- setWeight: 50 # Увеличение до 50%
- pause:
duration: 60s
- setWeight: 100 # Полный переход на новую версию
analysis:
templates:
- templateName: rollout-analysis
args:
- name: success-rate
value: "95"
analysis:
templates:
- name: rollout-analysis
metrics:
- name: success-rate
interval: 1m
count: 3
successCondition: result >= 95
provider:
prometheus:
address: http://prometheus-server.default.svc.cluster.local
query: |
sum(rate(http_requests_total{app="spark-app", status=~"2.."}[1m]))
/
sum(rate(http_requests_total{app="spark-app"}[1m])) * 100
В этой конфигурации канареечного развертывания сперва 20% трафика перенаправляется на новую версию Spark-приложения. Затем после временной паузы (1 минута) для мониторинга стабильности доля трафика увеличивается до 50% трафика. После новой паузы выполняется полный переход на новую версию. Также используется шаблон rollout-analysis, который проверяет показатель success-rate, рассчитываемый как отношение успешных HTTP-запросов (статусы 2xx) к общему числу запросов за 1 минуту. По условию не менее 95% запросов должны быть успешными.
Развертывание stateful-приложений
Argo Rollouts довольно просто использовать для stateless-приложений. Он поддерживает несколько распространенных провайдеров трафика, включая Kubernetes API Gateway, и может автоматически включать или отключать производственный трафик в новой версии приложения в случае сине-зеленого развертывания или постепенно переключать трафик для канареечного. Но для stateful-приложений, которые зависят от базы данных или очереди, возможностей Argo Rollouts недостаточно. Однако, многие Spark- или Flink-приложения распределенной обработки данных являются stateful, поскольку данные в реальном времени поступают непрерывно, и для их корректной обработки часто требуется хранить состояние между событиями. Например, для вычисления скользящих средних или агрегаций по окнам времени необходимо запоминать предыдущие данные. Кроме того, многие аналитические задачи включают в себя операции, которые зависят от предыдущих значений данных. Stateful-обработка позволяет выполнять такие операции, как группировка, сортировка или объединение данных на основе накопленного состояния. Наконец, хранение состояния позволяет системе восстанавливаться после сбоев без потери данных.
Возвращаясь к проблеме развертывания stateful-приложений, отметим, что стабильное приложение отслеживает производственную очередь или базу данных, где хранятся состояния. После запуска новой, предварительной, версии приложения она тоже будет забирать рабочие данные из производственной очереди, чего следует избежать в тестовом режиме. Разумеется, можно просто приостановить развертывание и вручную перенаправить новую версию приложения в другую очередь. Это решение будет работать, но оно не очень изящное. Можно сделать по-другому, используя Argo Rollouts вместе с Kubernetes Downward API.
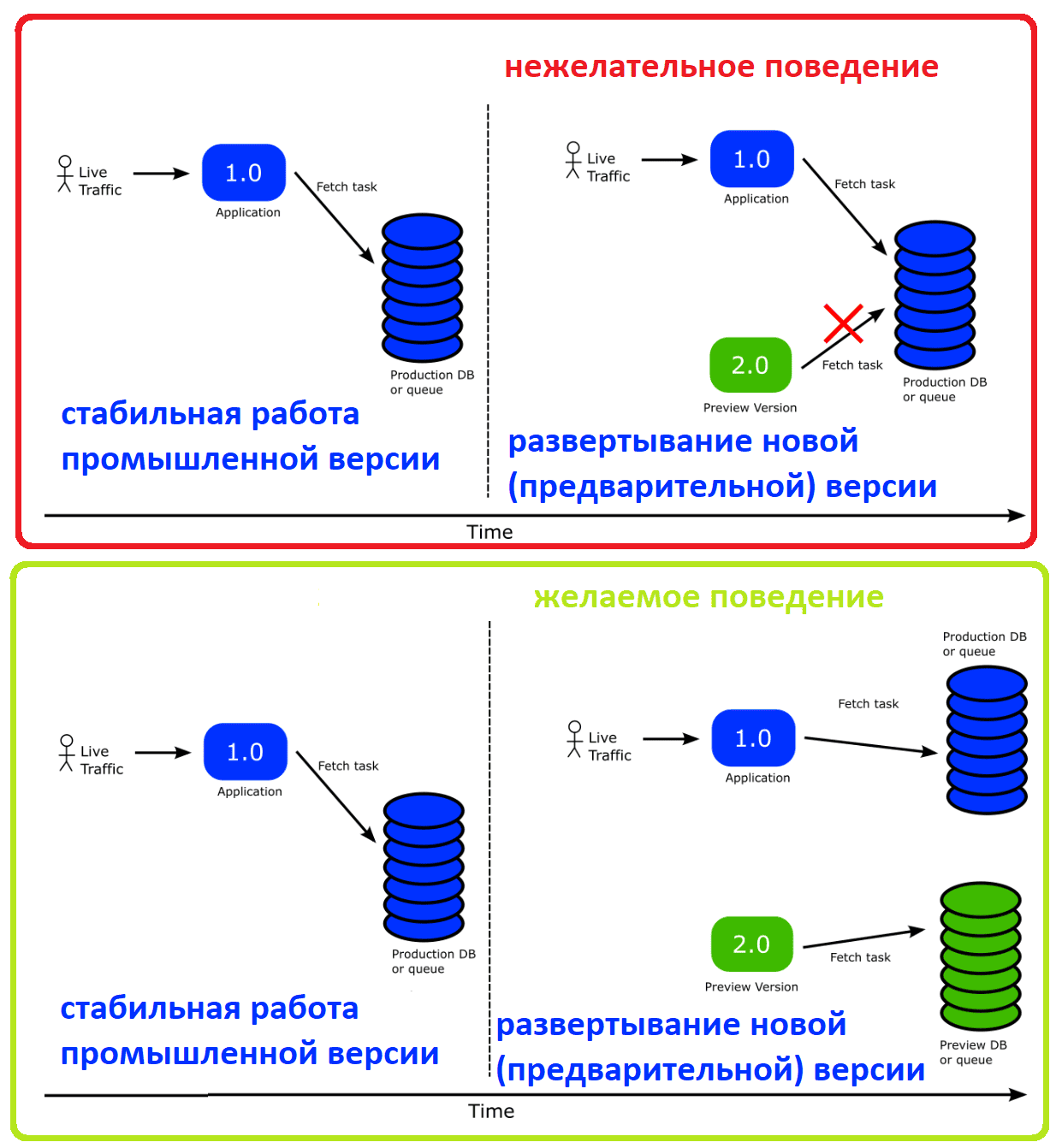
Kubernetes Downward API – это встроенный механизм Kubernetes, который позволяет передавать любые метки Pod в контейнерное приложение, монтируя их как файлы или переменные среды.
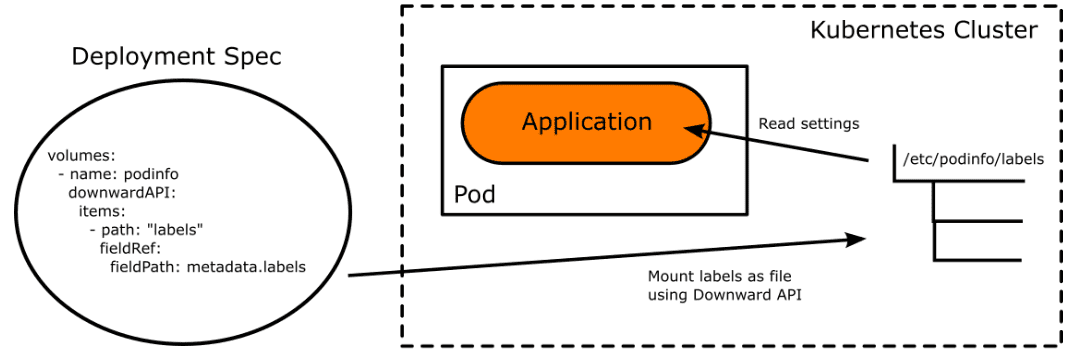
Kubernetes Downward API отлично сочетается с эфемерными метками Argo Rollouts, позволяющими указать контроллеру, что надо автоматически добавлять или удалять определенные метки в развертывание. Эти метки можно преобразовать в конфигурацию приложения с помощью API Downward. Чтобы приложение знало об этих изменениях, необходимо обеспечить автоматическую перезагрузку параметров конфигурации при обновлении файлов, которые их содержат. Это реализуется на стороне кода приложения. В результате процесс развертывания будет выглядеть так:
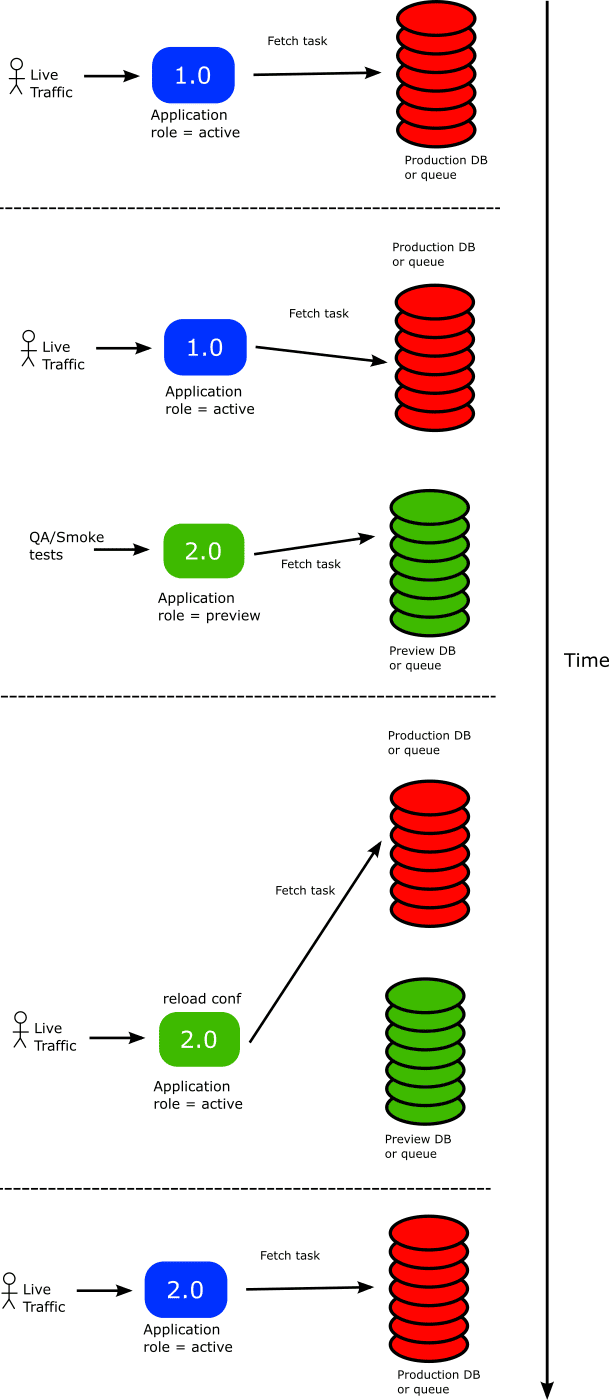
Пример манифеста Rollout для Spark-приложения, который использует Downward API для передачи меток в конфигурацию приложения, может выглядеть так:
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: spark-app-rollout
namespace: default
spec:
replicas: 3
strategy:
canary:
steps:
- setWeight: 25
- pause:
duration: 10m
- setWeight: 50
- pause:
duration: 10m
- setWeight: 100
selector:
matchLabels:
app: spark-app
template:
metadata:
labels:
app: spark-app
# Эфемерная метка, управляемая Argo Rollouts
rollout-pod-template-hash: "{{.Rollout.Status.CurrentPodHash}}"
spec:
containers:
- name: spark-container
image: spark:3.1.1
ports:
- containerPort: 8080
env:
- name: APP_VERSION
valueFrom:
fieldRef:
fieldPath: metadata.labels['rollout-pod-template-hash']
# Использование Downward API для передачи меток в приложение
volumeMounts:
- name: config
mountPath: /etc/config
readOnly: true
volumes:
- name: config
downwardAPI:
items:
- path: "app-version"
fieldRef:
fieldPath: metadata.labels['rollout-pod-template-hash']
В этом примере, также, как и в прошлом, используется стратегия канареечного развертывания, чтобы постепенно увеличивать количество подов с новой версией приложения с мониторингом стабильности. Эфемерная метка rollout-pod-template-hash служит уникальным идентификатором версии приложения и автоматически обновляется контроллером Argo Rollouts при каждом изменении шаблона пода. Эта эфемерная метка передается внутрь контейнера с помощью переменной окружения APP_VERSION. Конфигурация тома монтируется как конфигурационный файл, содержащий значение метки. Это полезно, когда приложение читает конфигурацию из файловой системы.
Вышеприведенный манифеста надо сохранить в YAML-файл и применить его в kubectl, используя команду apply –f. Отслеживать статус Rollout можно также через CLI-утилиту, вызвав в kubectl команду argo rollouts get rollout или использовать интерфейс пользователя Argo Rollouts для наглядного мониторинга.
Для развертывания новой версии Spark-приложения следует обновить образ контейнера в манифесте Rollout и снова применить изменения. После этого Argo Rollouts автоматически начнет процесс канареечного развертывания с обновленной конфигурацией, используя Downward API для передачи новых меток в приложение.
Научитесь работать с Kubernetes и Argo Workflows на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

