
Сегодня рассмотрим, чем корпоративное обучение большим данным (Big Data) отличается от индивидуального. Читайте в нашей статье, почему образовательные курсы по Apache Kafka, Hadoop, Spark и другим технологиям Big Data сплотят ваших сотрудников лучше любого тимбилдинга и как повысить эффективность такого обучающего тренинга. Почему корпоративное обучение Big Data эффективнее индивидуальных курсов:...

Вчера мы рассказывали, от чего зависит скорость работы Apache Kafka и как можно повысить. Сегодня рассмотрим подробнее, как именно конфигурация отправителей (производителей, producers) сообщений влияет на общую производительность этой распределенной Big Data системы потоковой агрегации событий. Что такое конфигурация производителей Apache Kafka Напомним, общая производительность Кафка зависит от следующих факторов:...

Продолжая практическое обучение Kafka, сейчас мы рассмотрим, от чего зависит производительность этой распределенной Big Data системы потоковой агрегации событий. Частично эту тему мы уже рассматривали в статье про применение Кафка в высоконагруженных проектах. Читайте в сегодняшнем материале, какие параметры влияют на скорость работы Кафка и как можно ее повысить. Как...

Цифровизация не всегда приносит только положительные результаты: увеличение прибыли, сокращение расходов и прочие бонусы оптимизации бизнеса. Большие данные – это большая ответственность, с которой справится не каждый. В этой статье мы собрали 5 самых ярких событий ИТ-мира за последнюю пару лет, связанных с большими данными (Big Data) и машинным обучением...
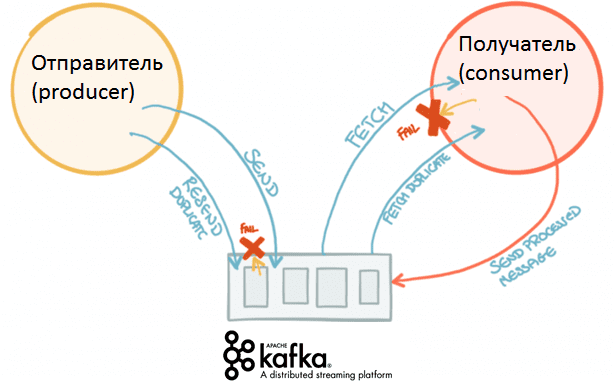
Вчера мы говорили про концепцию QaaS, очереди сообщений в Apache Kafka и другие проблемы производительности высоконагруженных систем с использованием этой Big Data платформы. Сегодня рассмотрим сложности многопоточной обработки событий в разном порядке: когда возникают подобные ситуации и как их решить. Для этого еще раз сравним Кафку с ее вечным конкурентом,...

При всех достоинствах Apache Kafka, для этого популярного Big Data средства управления сообщениями характерны определенные трудности в обеспечении производительности. Сегодня мы поговорим про некоторые проблемы использования этого распределенного брокера сообщений в высоконагруженных системах. В качестве реального примера рассмотрим особенности практического использования Кафка в отечественном сервисе объявлений Авито. Что такое высоконагруженная...

Сегодня мы поговорим про одно из ключевых понятий управления проектами и бизнес-анализа: что такое приоритизация, почему это важно в цифровизации и внедрении технологий больших данных (Big Data). Также рассмотрим основные методы и практические техники расстановки приоритетов, которые будут полезны каждому менеджеру (руководителю) и любому специалисту: аналитику, разработчику, инженеру и исследователю...
Рассматривая практическое обучение Kafka, сегодня мы поговорим, зачем нужен Zookeeper и можно ли использовать Кафка без этой централизованной службы синхронизации распределенных сервисов. Читайте в нашей статье о роли Zoo в системах обработки больших данных (Big Data) и о том, может ли Apache Kafka эффективно работать без Zookeeper, а также как...

Продолжая разговор о том, как выбрать курсы по Kafka и другим технологиям больших данных (Big Data), сегодня рассмотрим, кому и в каких случаях нужно такое повышение квалификации. В этой статье мы собрали для вас 5 прикладных кейсов по Кафка для ИТ-профессионалов разных специальностей, от системного администратора до Data Engineer’а. А...

В этой статье мы рассмотрим наиболее значимые факторы по выбору образовательных курсов по Apache Kafka и другим технологиям больших данных (Big Data). А также расскажем, как эти условия реализуются в нашем учебном центре, чтобы сделать повышение квалификации ИТ-специалистов и руководителей максимально эффективным. Что важно при выборе курсов по Кафка Проанализировав...
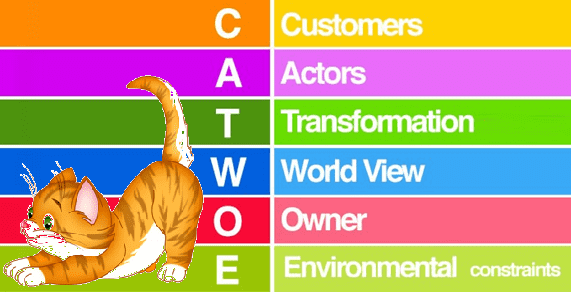
Сегодня мы поговорим о том, что такое CATWOE и зачем эта техника бизнес-анализа нужна руководителю. Также рассмотрим практическое применение этого метода на примере реального бизнес-кейса по цифровизации крупного предприятия и внедрения Big Data системы промышленного интернета вещей (Industrial Internet of Things, IIoT) в виде RFID-технологий. Как сэкономить время на бизнес-анализ...

Вчера мы писали, что cybersecurity биометрии пока не слишком надежна: обмануть можно как дактилоскопический сканер на смартфоне, так и крупную систему больших данных (Big Data). Сегодня поговорим о мерах обеспечения информационной безопасности биометрических данных: многофакторной аутентификации, защите цифровых шаблонов и кратной верификации. А также расскажем, когда государственная цифровизация в России...

Сравнив между собой наиболее популярные методы биометрии, сегодня мы подробнее рассмотрим, насколько они устойчивы к фальсификациям. Читайте в этой статье, как хакеры обманывают сканер отпечатков пальцев, путают Big Data системы уличной видеоаналитики и выдают себя за другое лицо с помощью модной технологии машинного обучения (Machine Learning) под названием Deep Fake....
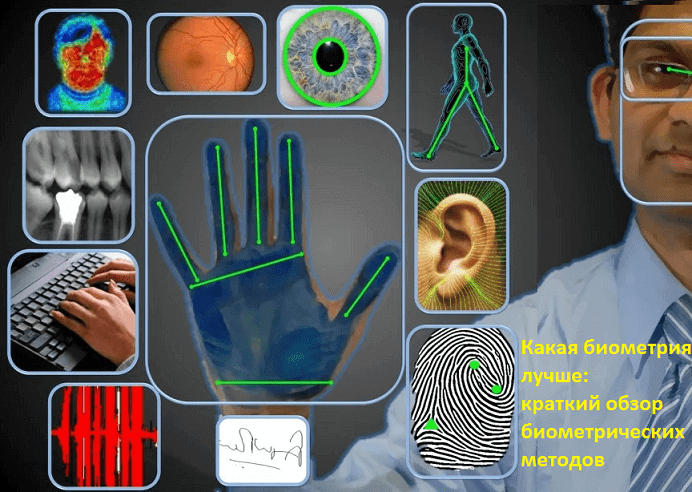
Продолжая рассматривать уязвимости биометрических систем, сегодня мы поговорим про отличия разных методов биометрии. Проанализируем быстроту их работы и устойчивость к фальсификации, а также используемые технологии Big Data и Machine Learning. Кроме того, сравним ставшие привычными способы идентификации личности по фотографии лица, снимкам глаз, отпечаткам пальцев и ладоней с более «экзотическими»...

В прошлой статье мы рассказывали о самых крупных утечках данных из биометрических Big Data систем в России и за рубежом. Сегодня рассмотрим характерные уязвимости биометрии: естественные ограничения методов идентификации личности с помощью машинного обучения (Machine Learning, ML) и целенаправленные атаки. 2 главные уязвимости биометрических Big Data систем на базе Machine...

В то время, как нацпрограма «Цифровая экономика» активно продвигает использование биометрических персональных данных россиян в качестве основных идентификаторов для государственных Big Data систем и коммерческих сервисов, информация продолжает утекать. В этой статье мы собрали наиболее крупные инциденты с утечками данных из биометрических систем в России и за рубежом. Как утекают...

Мы уже рассказывали, как машинное обучение применяется для прогнозирования будущих событий в финансовом секторе, нефтегазовой промышленности, логистике, HR-менеджменте, девелопменте, страховании, муниципальном управлении, маркетинге, ритейле и других отраслях экономики. Сегодня рассмотрим еще несколько практических примеров такого приложения Machine Learning и в этом контексте разберем одно из ключевых понятий Data Science по...

Продолжая тему Cybersecurity, сегодня мы поговорим про биометрические системы: что это такое, как они работают и чем нарушают требования GDPR и № 152-ФЗ. Также в этом материале мы собрали для вас примеры таких наиболее известных проектов на базе технологий Big Data и Machine Learning. Что такое биометрические персональные данные и...

Сегодня мы коснемся процесса управления требованиями и рассмотрим, как техника SQUARE (Security Quality Requirements Engineering) помогает снизить риски в проектах по цифровизации бизнеса и разработке Big Data систем. Читайте в нашем материале, что такое информационная безопасность, BABOK и Gherkin, а также когда и как формулировать требования к cybersecurity на ранних...

В этой статье мы снова поговорим про GDPR и наиболее крупные утечки данных, почему случаются такие инциденты cybersecurity. Также рассмотрим аналитические методы и техники, которые помогут обнаружить ключевые причины таких проблем и снизить риски их возникновения. Читайте в нашем материале, что такое диаграмма Исикавы и зачем нужен подход SQUARE при...