
В этой статье мы продолжим рассматривать примеры использования технологий Big Data и Machine Learning в задачах профилактики и расследовании преступлений. Сегодня читайте, как машинное обучение и большие данные позволяют предупредить массовые убийства и выявить закладки наркотиков с помощью методов графовой аналитики и автоматической оценки сообщений в соцсетях. Machine Learning против...

Цифровизация и искусственный интеллект повышают эффективность не только коммерческого бизнеса, промышленных производств и государственных услуг. В этой статье мы расскажем, как технологии больших данных (Big Data) и машинное обучение (Machine Learning) борются с незаконным оборотом наркотиков. Читайте в сегодняшнем материале 3 примера практического использования науки о данных (Data Science) в...

Сегодня мы расскажем про интерактивные карты преступности в России и за рубежом, а также рассмотрим, как технологии больших данных (Big Data) и машинного обучения (Machine Learning) помогают обнаружить и предупредить городские преступления. Читайте в этой статье, что такое Crime Mapping, где уже запущены биометрические системы идентификации подозреваемых и как дроны...

В контексте темы бережливого производства в ИТ, сегодня мы расскажем про анализ требований к разработке ПО в условиях Agile-подходов к организации работы и соответствия жестким рамкам отечественных ГОСТов и зарубежных стандартов. Читайте в нашей статье, что говорит BABOK по этому поводу и когда нужно запускать процесс создания программной документации, чтобы...

Ранее мы рассказывали, что общего между бережливым производством и DevOps. Сегодня рассмотрим, как 7 принципов Lean отражены в разработке программного обеспечения. Также читайте в нашей статье об актуальности методологии ITIL для проектов цифровизации и внедрения технологий больших данных (Big Data). 7 принципов Lean в ИТ Мы уже упоминали, что впервые...
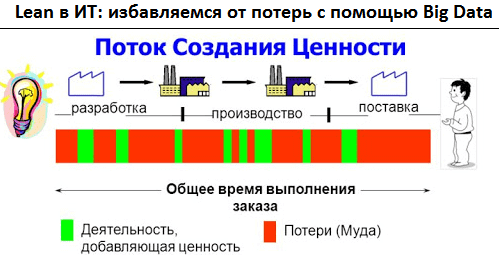
Продолжая разговор про бережливое производство в ИТ, сегодня мы рассмотрим виды потерь и источники их возникновения, а также поговорим, как принципы Lean помогают бизнесу избавиться от муда, мури и мура средствами больших данных (Big Data). 8 видов потерь в Lean с примерами из ИТ Прежде всего, поясним значение понятий муда,...
Не претендуя на лавры Мэри и Тома Поппендиков, которые впервые освятили применение Lean в разработке ПО, сегодня мы расскажем, как идеи бережливого производства реализуются в области Big Data. Читайте в нашей статье про принцип вытягивания в Apache Kafka, концепцию «точно вовремя» в Apache Spark, SMED в Kubernetes и облачных кластерах...
Чтобы сделать курс Аналитика больших данных для руководителей еще более интересным, мы продолжаем включать в него темы про методы производственной оптимизации. Сегодня рассмотрим, что такое бережливое производство (Lean) и почему Agile вообще и DevOps в частности активно используют принципы этой концепции. Также читайте в нашей статье, чем Lean отличается от системы...
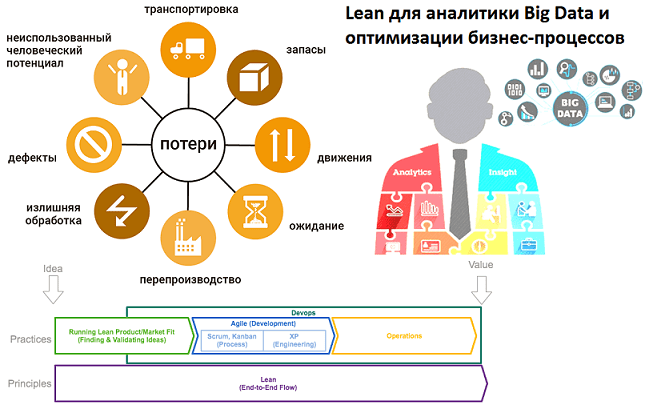
Вчера мы рассмотрели, что такое функционально-стоимостный анализ (ФСА) и как этот метод позволяет оценить бизнес-процессы в денежном выражении. Однако, результаты ФСА, в первую очередь, ориентированы на оптимизацию с точки зрения финансов, а не организации и технологий. Исправить ситуацию помогут принципы бережливого производства (Lean). Сегодня мы расскажем об одном из них...

В этой статье мы расскажем, что такое функционально-стоимостный анализ, как он связан с концепцией бережливого производства (Lean) и каким образом позволяет оценить и оптимизировать бизнес-процессы. Также рассмотрим, почему этому методу стоит уделить внимание при изучении основ цифровизации, а также в рамках проектов по внедрению технологий больших данных (Big Data). Что...
Сегодня мы рассмотрим, что такое расширенная аналитика и дополненное управление данными, как они связаны с цифровизацией бизнеса и почему исследовательское бюро Gartner включило эти технологии в ТОП-10 самых перспективных трендов 2020 года. Читайте в нашей статье, как машинное обучение (Machine Learning) помогает аналитикам и руководителям находить во множестве больших данных...
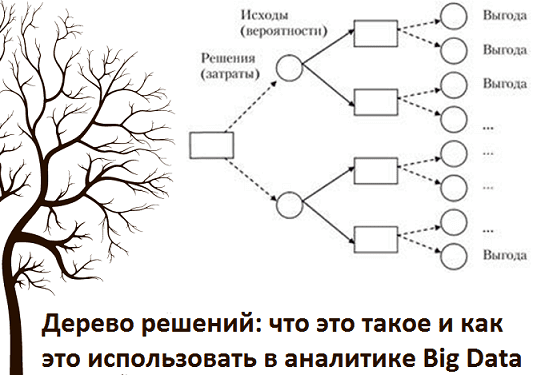
Продолжая насыщать курс Аналитика больших данных для руководителей важными понятиями системного анализа, сегодня мы рассмотрим, что такое дерево решений (Decision Tree). А также расскажем, как этот метод Data Mining и предиктивной аналитики используется в машинном обучении, экономике, менеджменте, бизнес-анализе и аналитике больших данных. Как растут деревья решений: базовые основы Начнем...

11 марта 2020 года ВОЗ объявила о пандемии нового коронавируса (Covid-19), который в декабре 2019 был впервые обнаружен в китайском мегаполисе Ухань. С тех пор вирус стремительно распространяется по всей планете, вызывая острые респираторные заболевания. Сегодня мы расскажем, почему, несмотря на повсеместные карантины и обвал мировых рынков, все не все...
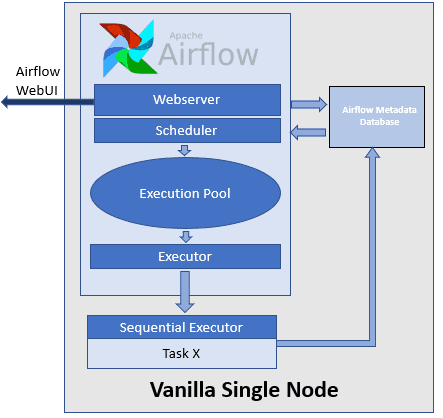
Недавно мы рассказывали про Airflow Kubernetes Executor, который позволяет выполнять задачи DAG-графа Эйрфлоу в среде Kubernetes, развертывая Docker-контейнер на отдельном пользовательском модуле (pod). Сегодня рассмотрим, какие еще есть исполнители задач в Apache Airflow, как они используются при автоматизации batch-процессов обработки больших данных и с какими проблемами можно столкнуться при их...
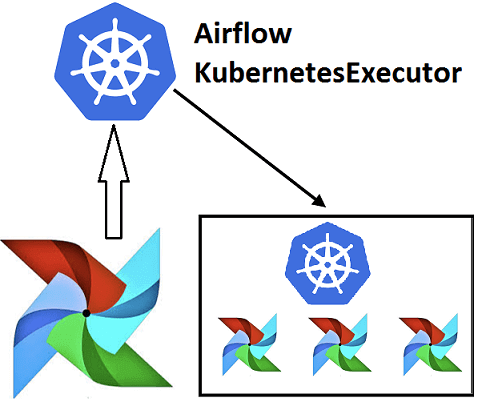
Эффективное обучение AirFlow, также как курсы по Spark, Hadoop, Kafka и другим технологиям больших данных (Big Data) также включают нюансы интеграции этого фреймворка с другими средами. Например, вчера мы рассматривали преимущества DevOps-подхода к разработке Data Flow на примере взаимосвязи Apache Airflow с Kubernetes посредством специальных операторов. Продолжая эту тему, сегодня...

Вчера мы рассказали, почему запускать Airflow на Kubernetes – это эффективно и выгодно для всех участников batch-процессов с большими данными (Big Data): разработчиков Data Flow, Data Scientist’ов, аналитиков и инженеров. Сегодня рассмотрим, что такое Airflow Kubernetes Operator и чем он отличается от подобной разработки компании Google. Как работает AirFlow Kubernetes...

ДАРИМ ПРИЗЫ ЗА ОТЗЫВЫ в 2020 году! Итоги акции "Напиши отзыв и получи шанс выиграть наушники Sony WH-1000XM3 !" В 2020 году «Школа Больших Данных» проводила для своих слушателей Розыгрыш призов: напиши и опубликуй отзыв по прослушанному курсу в Google или Yandex и участвуй в розыгрыше 5 Bluetooth наушников Sony WH-1000XM3....

Чтобы обучение Airflow было максимально приближенным к практике, сегодня мы поговорим про особенности реального внедрения этого фреймворка для разработки, планирования и мониторинга пакетных процессов обработки больших данных (Big Data) с учетом современного DevOps-подхода. Читайте в нашей статье, зачем вообще нужна связка Apache Эйрфлоу с Kubernetes и как это реализовать технически....

Продолжая говорить про обучение Airflow, сегодня мы рассмотрим ключевые преимущества и основные проблемы этой библиотеки для автоматизации часто повторяющихся batch-задач обработки больших данных (Big Data). Также мы собрали для вас пару полезных советов, как обойти некоторые ограничения Airflow на примере кейсов из Mail.ru, IVI и АльфаСтрахования. Чем хорош Apache AirFlow:...
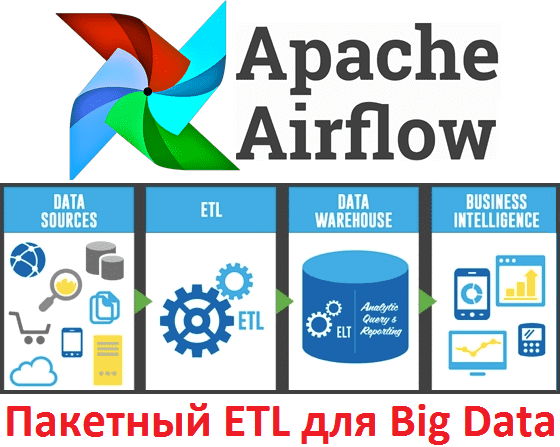
В этой статье мы поговорим про Apache AirFlow - эффективный инструмент для пакетных ETL-задач при работе с большими данными (Big Data): что это такое, как работает и чем полезен для инженера данных (Data Engineer). Также рассмотрим несколько практических примеров реального использования этой библиотеки для разработки, планирования и мониторинга batch-процессов. Что...