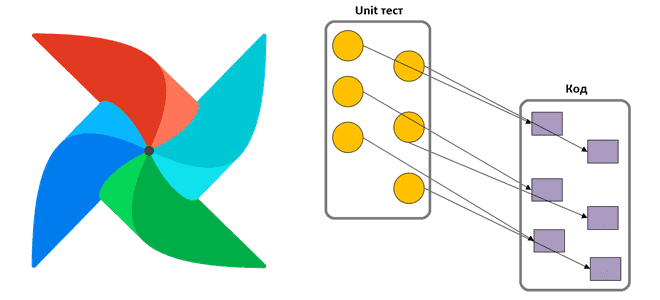
Благодаря возможности написать собственный Python-код для операторов и задач DAG’ов, Apache Airflow позволяет разработчикам Data Flow и инженерам данных создавать сложные и эффективные конвейеры пакетной обработки данных. Обеспечить надежность этого многообразия поможет качественное тестирование пользовательского кода. Рассмотрим примеры и рекомендации по написанию модульных тестов. Зачем тестировать DAG AirFlow? Модульные тесты...

Поскольку тема импортозамещения сейчас стала особенно актуальной, сегодня рассмотрим отечественный программно-аппаратный комплекс для хранения и аналитической обработки данных СКАЛА-Р МБД8. Что это такое, как использовать и при чем здесь продукты Arenadata. Машины больших данных СКАЛА-Р МБД8 и Arenadata Разработчиком программно-аппаратного комплекса «Машина больших данных» СКАЛА-Р МБД8 является российская компания ООО...
Недавно мы писали про проектирование микросервисной архитектуры на базе Apache Kafka. В продолжение этой актуальной для ИТ-архитекторов, разработчиков и дата-инженеров темы, сегодня рассмотрим опыт американской медиакомпании Storyblocks по переходу от монолитной архитектуры системы поставки контента к распределенным микросервисам с Apache Kafka в Confluent Cloud. Постановка задачи: монолит vs микросервисы По...

В этой статье для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных разберем пример перевода сервиса Strava с кластера Cassandra в облачное хранилище AWS S3 и какую роль в этом сыграл вычислительный движок Apache Spark. Постановка задачи: слишком дорогая Cassandra Strava – это глобальный сервис отслеживания активности велосипедистов, бегунов...
Для практического обучения разработчиков Data Flow и инженеров данных, сегодня разберем способ аутентификации пользователей Apache NiFi на примере Okta OIDC в качестве сервиса провайдера удостоверений. Также вспомним другие способы аутентификации пользователей в этом потоковом маршрутизаторе. Аутентификация в Apache NiFi: краткий ликбез Apache NiFi поддерживает различные типы методов аутентификации пользователей: с...
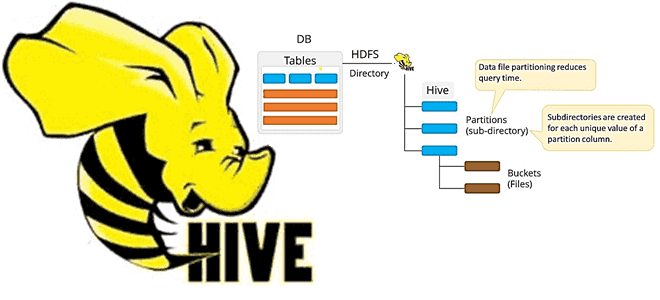
Что такое MSCK REPAIR TABLE в Apache Hive, зачем нужна эта команда, ее достоинства и недостатки, а также альтернативные варианты для задач пакетной дата-инженерии. Разбираем на примере конвейера обработки данных в ML-приложениях при работе с Data Lake. Команда MSCK REPAIR TABLE в Apache Hive В ML-приложениях особенно важно, как озеро данных (Data...

Сегодня заглянем под капот Tanzu Greenplum Text: архитектура и принципы работы этого средства поиска и анализа текстов, интегрированного с популярной MPP-СУБД. Как движок наподобие Elasticsearch связывает кластер Apache Solr с базой данных Greenplum и зачем здесь нужен Zookeeper. Что такое Tanzu Greenplum Text Мы уже рассказывали про основные функциональные возможности...

В рамках обучения ИТ-архитекторов и разработчиков распределенных приложений рассмотрим, что представляет собой Transactional Outbox и как этот паттерн проектирования микросервисной архитектуры можно реализовать с помощью Neo4j и Apache Kafka, чтобы создать масштабируемый, общий и абстрактный способ запроса информации независимо от типа объекта. Постановка задачи: проблемы микросервисной архитектуры и способы их...
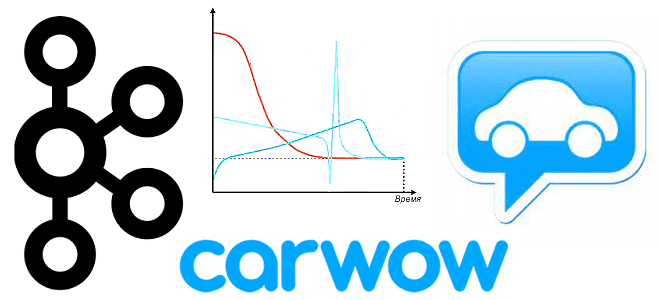
Мы уже рассказывали, что такое Graceful shutdown на примере Spark Streaming. Сегодня разберем реализацию этой идеи плавного завершения задач в потоковой обработке данных применяется в компании Carwow при работе с Apache Kafka и dyno-контейнерами приложений Heroku. Потоковая обработка данных и проблема завершения потоковых заданий в контейнерах Heroku Carwow - британская...

Практический пример аналитики больших данных в реальном времени с Apache Spark, Kafka, ClickHouse и AWS S3: возможности, архитектура, также специально для дата-инженеров и разработчиков распределенных приложений рассмотрим, сколько времени нужно для разрешения каждого вызова API в определенном временном диапазоне. Анализ событий пользовательского поведения в реальном времени Основным продуктом международной ИТ-компании...
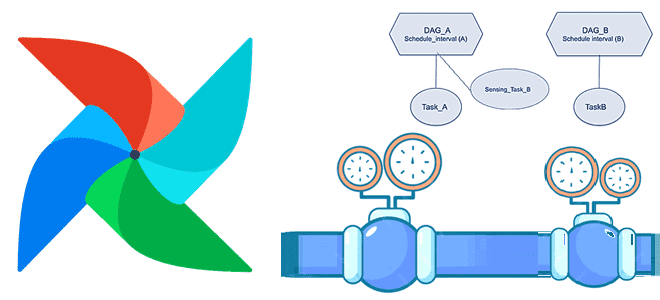
Мы уже писали про датчики или сенсоры - особый тип операторов Apache AirFlow, предназначенных для ожидания какого-то события. Сегодня рассмотрим практический пример обучения дата-инженеров и разработчиков по использованию внешнего сенсора в рамках типовой задачи дата-инженерии по организации ETL/ELT-процессов при поэтапной загрузке данных в DWH для OLAP-систем. Постановка задачи: поэтапная загрузка...

В этой статье для дата-инженеров и администраторов SQL-on-Hadoop рассмотрим, что такое Cloudera Data Platform Operational Database, как это связано с Apache HBase и Phoenix. Также разберем, каким образом перенести данные из кластера HBase в Cloudera Operational Database, избежав их потери и других подводных камней. Что такое Cloudera Operational Database: назначение...
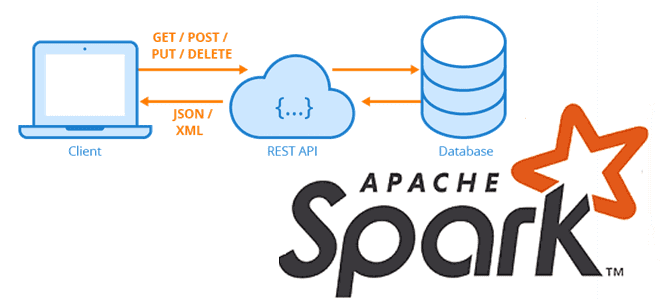
Сегодня рассмотрим, как загружать большие объемы данных из REST API-сервисов с Apache Spark, написав на PySpark собственную UDF-функцию с преобразованием withColumn(), чтобы воспользоваться всеми преимуществами распределенных вычислений этого фреймворка. Локальное исполнение на драйвере и распараллеливание REST-API вызовов в Apache Spark Мы уже рассказывали, что конвертация Python-скрипта в распределенный код Apache...

В феврале 2022 года вышел новый релиз Cloudera Flow Management 2.1.3 для совместного использования с Cloudera Manager и CDP Private Cloud Base 7.1.7. Этот выпуск основан на Apache NiFi 1.15, о новинках которого мы ранее рассказывали здесь, здесь и здесь. Сейчас рассмотрим основные преимущества этого решения. 5 главных улучшений в...

Сегодня поговорим про администрирование кластера Apache Kafka и разработку потоковых приложений передачи и разберем, как обеспечить их работу в бессерверном режиме с платформой Upstash. Финансовая экономия, простота сопровождения и другие преимущества FaaS-сервисов и serverless-подхода с RESTfull API для обработки событий в реальном времени. Снова про serverless: что такое Upstash Kafka...
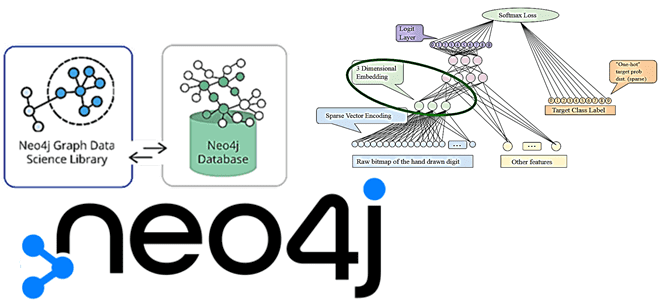
В рамках нашего нового курса графовым алгоритмам в бизнес-приложениях, сегодня разберем эмбеддинг-алгоритмы в библиотеке Graph Data Science СУБД Neo4j: их особенности и возможности практического использования для задач обработки естественного языка (NLP). Также рассмотрим, чем FastRP отличается от GraphSAGE с Node2Vec. NLP, эмбеддинги и Graph Data Science В обработке естественного языка...

Что такое Hive Transform, зачем это нужно дата-инженеру и разработчику распределенных приложений, где и как использовать эту функцию популярного средства SQL-on-Hadoop. Краткий обзор альтернативного способа операций с данными в Apache Hive, его возможности и ограничения, а также связь с HiveQL. Преобразования в Apache Hive Apache Hive – это популярная экосистема...

Как организовать удобный мониторинг за приложениями Apache Spark в кластере Kubernetes с помощью Prometheus и Grafana: пошаговый guide для администраторов и дата-инженеров с примерами. Создаем свою альтернативу наглядным дэшбордам AWS EMR с Java-библиотекой Dropwizard Metrics и средством настройки оповещений Alertmanager. Не только AWS EMR или как следить за Spark-приложениями в...

В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза. MLOps с AirFlow и MLFlow в облаке AWS Ранее...

В октябре прошлого года вышел крупный релиз Apache AirFlow 2.2.0. Разбираем его главные фичи, которые больше всего интересны с точки зрения инженерии данных: пользовательские расписания и декораторы, отложенные задачи, а также валидация параметров DAG по JSON-схеме. Краткий обзор обновлений AirFlow 2.2.0 Хотя последней версией популярного batch-планировщика задач Apache Airflow на...