
23 июня 2023 года опубликован очередной релиз Apache Spark 3.4.1, который считается отладочным выпуском для предыдущего, содержащий исправления стабильности. Помимо исправления ошибок, в нем также 16 новых фичей и более 20 улучшений, самые главные из которых мы рассмотрим далее. Исправления ошибок и новые фичи Apache Spark 3.4.1 Поскольку выпуск считается...
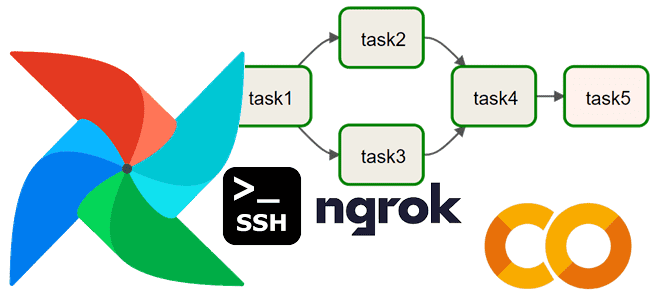
Сегодня рассмотрим, как выполнить DAG Apache AirFlow, запустив его в интерактивной среде Colab и получив доступ в веб-GUI этого фреймворка, создав туннель локального хоста на публичный URL с помощью утилиты ngrok. В качестве примера построим простой конвейер из 5 задач. Запуск Apache AirFlow в Google Colab Чтобы не повторять содержимое...

Зачем биомедикам понадобился свой язык описания онтологий, как эти задачи решает BioCypher и при чем здесь Neo4j: практическое приложение Data Science и графовых алгоритмов в биомедицинской сфере. Что такое BioCypher Графовые алгоритмы активно применяются в биомедицине для анализа различных биологических данных, таких как геномные, протеомные, данные о белковых взаимодействиях и...
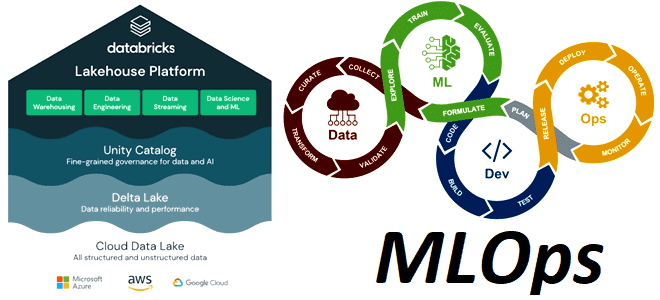
Мы уже писали, какие инструменты пригодятся MLOps-инженеру для развертывания моделей машинного обучения в производственных средах. Сегодня рассмотрим, как сделать это, используя MLOps-паттерны и средства платформы Databricks Lakehouse. MLOps в production: шаблоны развертывания на платформе Databricks MLOps представляет собой набор лучших практик и инструментов для автоматизации управления кодом, данными и моделями,...

15 июня 2023 года опубликован очередной выпуск самой популярной распределенной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.5.0, особенно важными для разработчиков, дата-инженеров и администраторов кластера. Обновления брокеров, контроллеров, продюсеров и потребителей Релиз Apache Kafka 3.5.0 богат на новинки: в нем 50 улучшений и почти 80 исправленных ошибок....
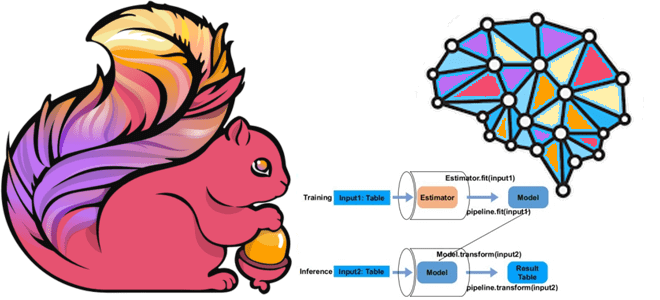
Как построить конвейер машинного обучения с помощью библиотеки Flink ML, из каких компонентов она состоит и как работает, а также что позволяет объединить алгоритмы потоковой обработки данных Apache Flink с ML-моделями. Что такое Flink ML Помимо MLeap, библиотеки сериализации для моделей машинного обучения, Apache Flink также включает Flink ML —...

Как расширить возможности MPP-СУБД Greenplum, используя фоновые рабочие процессы и почему это небезопасно. А также рассмотрим, что такое API Greenplum Partner Connector и как это использовать. Фоновые рабочие процессы Обычно фоновыми процессами в СУБД называются системные задания, которые запускаются при запуске базы данных и выполняют различные служебные задачи. К таким рутинным сервисным задачам...
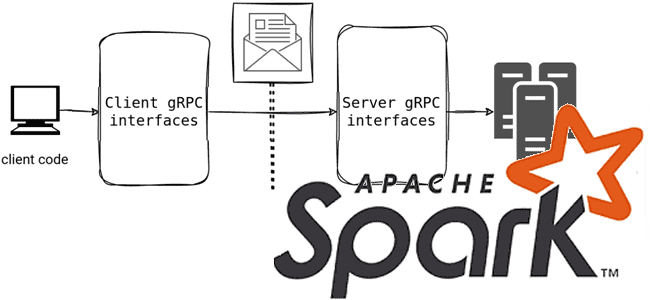
Мы уже писали, что в выпуске 3.4.0 от апреля 2023 года Spark Connect представил несвязанную архитектуру клиент-сервер, которая обеспечивает удаленное подключение к кластерам Spark из любого приложения, работающего в любом месте. Сегодня рассмотрим подробнее, как это работает и каковы плюсы для практического использования. Что такое Spark Connect и зачем это...
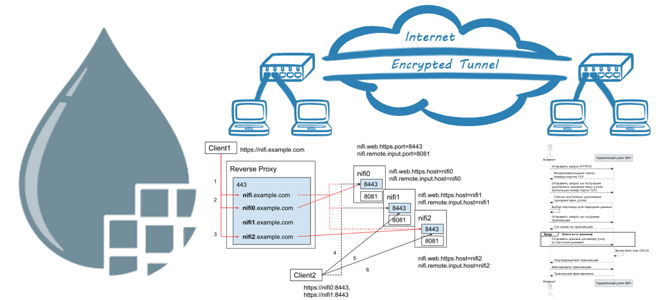
Будучи распределенным ETL/ELT-инструментом потоковой передачи данных, Apache NiFi имеет соответствующие средства, которые обеспечивают взаимодействия между разными узлами кластера. Одним из них является протокол Site-to-Site (S2S), с которым мы познакомимся далее. Что такое протокол S2S При отправке данных из одного экземпляра NiFi в другой можно использовать множество различных протоколов, наиболее предпочтительным...

Формат данных в озере или гибридном хранилище типа Data LakeHouse сильно влияет на скорость выполнения аналитических запросов. Сегодня рассмотрим, как Apache CarbonData делает аналитику больших данных в реальном времени еще быстрее. Что такое Apache CarbonData Традиционные форматы данных, часто используемые в проектах Big Data, такие как CSV и AVRO, имеют...

Сегодня рассмотрим, как запустить Apache AirFlow на мощностях Google в интерактивной среде Colab и войти в веб-GUI этого фреймворка, создав туннель локального хоста на публичный URL с помощью утилиты ngrok. Запуск Apache AirFlow в Google Colab Хотя Google Colab является мощным облачным окружением для запуска и написания Python-кода, выполнение написанных...
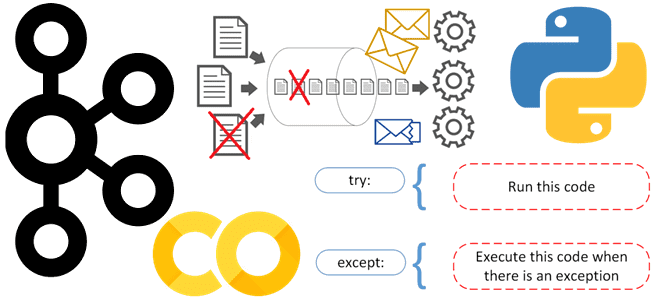
Самый простой способ организовать обработку и логирование ошибок в приложении-потребителе, чтобы продолжать считывание из Apache Kafka, даже если продюсер изменил структуру полезной нагрузки сообщения. Публикация данных в Kafka Напомним, Apache Kafka, в отличие от RabbitMQ, не позволяет организовать очередь недоставленных сообщений (DLQ, Dead Letter Queue) средствами самой платформы, о чем мы...
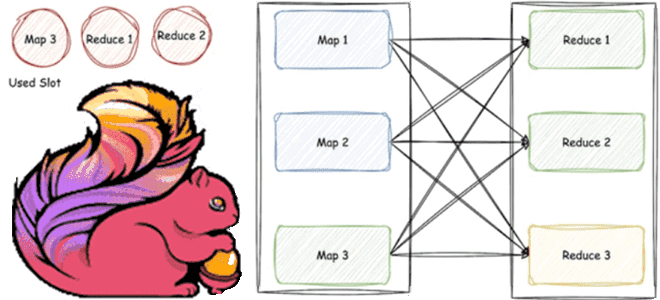
Что не так с планированием задач shuffle-операций, какие проблемы пакетной обработки данных устраняет введение гибридной перетасовки в Apache Flink 1.16 и как работает этот режим Hybrid Shuffle. Что такое режим гибридного перемешивания в Apache Flink В версии Apache Flink 1.16, о которой мы писали здесь, был впервые представлен режим гибридной...

Сегодня заглянем внутрь Neo4j, чтобы разобраться с базовыми концепциями этой графовой базы данных. Какие уровни изоляции транзакций поддерживаются в Neo4j, почему одна установка по умолчанию содержит две базы данных, что такое составная БД и как с этим работать. Транзакции в Neo4j Neo4j — это популярная нативная графовая СУБД, способная управлять...
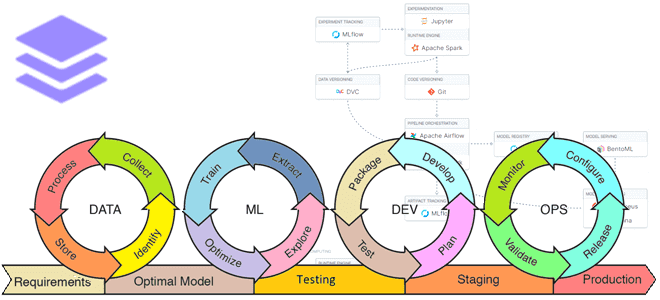
Вчера я нашла очень интересный MLOps-проект, который позволяет построить конвейер поддержки жизненного цикла системы машинного обучения, используя более 50 популярных инструментов. Что такое MyMLOps и как это пригодится ML-инженерам. Что такое MyMLOps: новый сервис для MLOps Чтобы реализовать идеи концепции MLOps автоматизации всего жизненного цикл системы машинного обучения, от подготовки...
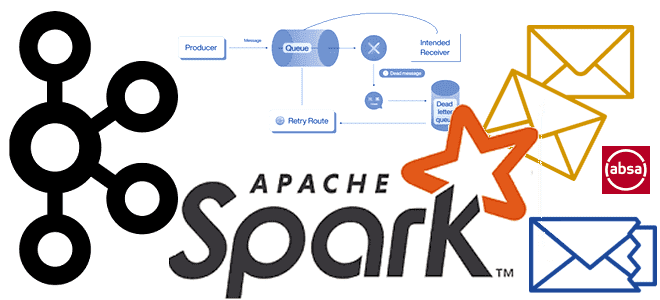
Недавно мы писали про лучшие практики работы с очередями недоставленных сообщений в Apache Kafka. Сегодня рассмотрим, как реализовать DLQ для AVRO-сообщений в приложении Spark Streaming c библиотекой ABRiS. DLQ для Apache Kafka в Spark-приложении Ситуация, когда приложение-продюсер вдруг изменяет формат или схему данных, публикуемых в Apache Kafka, на практике случается....
Почему DevOps-подходы не так просто внедрить в инженерию данных, что не так с реестром Apache NiFi и зачем расширять набор инструментов Toolkit собственным Java-приложением для автоматизированной миграции потоковых конвейеров в разные среды развертывания. Что не так с реестром Apache NiFi с точки зрения DevOps-инженера Изначально Apache NiFi был создан как...
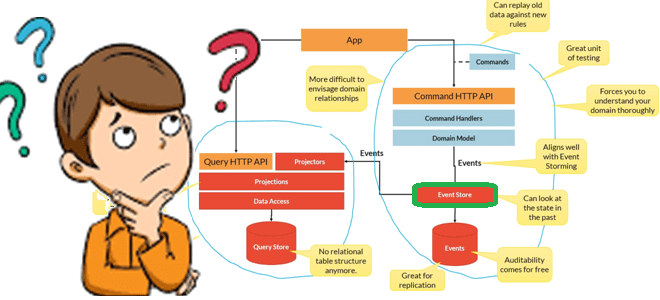
Что представляет собой паттерн проектирования микросервисов под названием источник событий (Event Sourcing) и как его реализовать в реляционных базах данных и NoSQL-системах. Разбираемся с архитектурой данных и архитектурой ПО на практических примерах. Архитектурный шаблон Event Sourcing Многие архитектурные шаблоны рассматривают сущности (entity) как основную концепцию, описывая способы их сохранения и...

Будучи популярным фреймворком для оркестрации пакетных процессов обработки Apache AirFlow образует вокруг себя целую экосистему. Сегодня познакомимся с некоторыми инструментами, которые пригодятся дата-инженеру для проектирования и отладки конвейеров данных: ADA, Ditto, Amundsen, gusty и Viewflow. Аналитика системных метрик Apache AirFlow с ADA и Amundsen ADA — это микросервис, созданный для...

Недавно мы писали про группы общего доступа в Apache Kafka, которые планируется реализовать в KIP-932. Сегодня рассмотрим, как именно это предполагается сделать. Принципы работы группы общего доступа Предложение по улучшению Kafka (KIP, Kafka Improvement Proposal) предполагает внесение значительных изменений. Все начинается с публикации предложения, которое рассматривается сообществом, комментируется и пересматривается до...