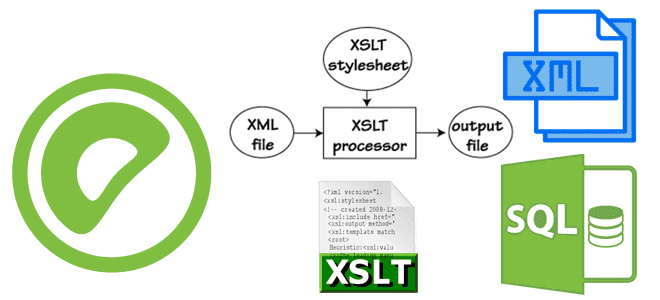
Как Greenplum хранит и обрабатывает XML-документы, зачем для этого нужны утилиты gpfdist и gpload, каковы их конфигурации для выполнения XSLT-преобразований XML-файлов и их загрузки/выборки во внешние таблицы MPP-СУБД. Работа с XML-документами и XSLT-преобразования в Greenplum Greenplum, как и PostgreSQL, также поддерживает работу со сложными типами данных и может вести себя...

Чем полезна интеграция ClickHouse с Apache Airflow и как ее реализовать: операторы в пакете провайдера и плагине на основе Python-драйвера. Принципы работы и примеры использования. 2 способа интеграции ClickHouse с AirFlow Продолжая разговор про интеграцию ClickHouse с другими системами, сегодня рассмотрим, как связать эту колоночную СУБД с мощным ETL-движком Apache...
От чего зависит задержка передачи данных из Apache Kafka в ClickHouse, как ее определить и ускорить интеграцию брокера сообщений с колоночной СУБД: настройки и лучшие практики. Интеграция ClickHouse с Kafka Чтобы связать ClickHouse с внешними системами, в этой колоночной СУБД есть специальные механизмы – интеграционные движки таблиц. Например, для взаимодействия...

Зачем устанавливать максимальный для каждого задания Apache Flink, для чего stateful-оператору пользовательский UUID, как выбрать подходящий бэкенд хранения состояний, от чего зависит оптимальный интервал создания контрольных точек и где настраивается высокая доступность менеджера заданий. 5 главных настроек перед запуском Flink-приложения в производственное развертывание Перед запуском приложения Apache Flink в производственное...
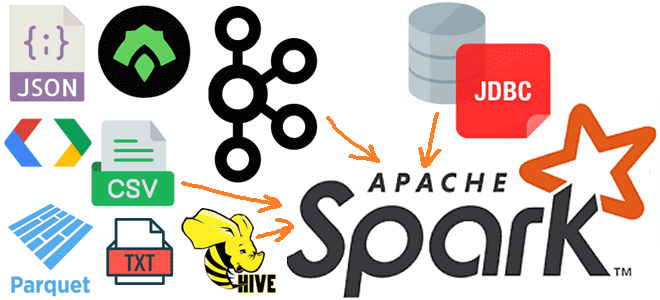
Какие источники исходных данных поддерживает Apache Spark для пакетной и потоковой обработки, обеспечивая отказоустойчивые вычисления в большом масштабе средствами SQL и Structured Streaming. Источники данных Apache Spark SQL и структурированной потоковой передачи Будучи фреймворком для создания распределенных приложений обработки больших объемов данных, Apache Spark может подключаться к разным источникам этих...
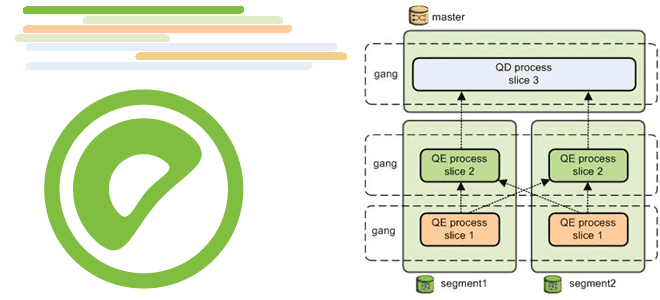
Как координатор Greenplum на мастер-хосте рассылает сегментам планы выполнения запросов, что такое курсор параллельного получения результатов оператора SELECT и каким образом его использовать для аналитики больших данных в этой MPP-СУБД. Особенности рассылки планов SQL-запросов в Greenplum на выполнение Хотя Greenplum основана на PostgreSQL, некоторые механизмы работы этих СУБД отличаются. Например,...
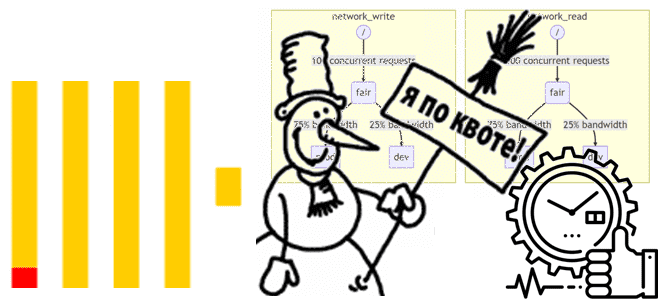
Как эффективно распределять и использовать ресурсы ClickHouse, зачем ограничивать возможности пользователей с помощью квот и классифицировать рабочие нагрузки. Управление ресурсами в ClickHouse Благодаря своей децентрализованной архитектуре ClickHouse, когда один экземпляр включает несколько серверов, к которым напрямую приходят запросы пользователей, эта колоночная СУБД работает очень быстро. Для репликации данных и выполнения...

Чем кэширование в OLAP-системах отличается от OLTP и как устроен кэш запросов ClickHouse: принципы работы, конфигурационные настройки и примеры использования SELECT-оператора. Особенности кэширования в ClickHouse Кэширование является одним из методов повышения производительности, который сокращает время на получение результатов вычислений за счет их хранения в области быстрого доступа. Обычно кэшируются результаты...
Как с Apache Flink настроить локальную службу OLAP, а также развернуть ее в рабочей среде производственного кластера: архитектура, принципы работы и параметры конфигурации для сложных аналитических сценариев. Служба Flink OLAP: архитектура и принципы работы Идея выделить в Apache Flink механизм OLAP для анализа данных в потоковом хранилище появилась еще год...
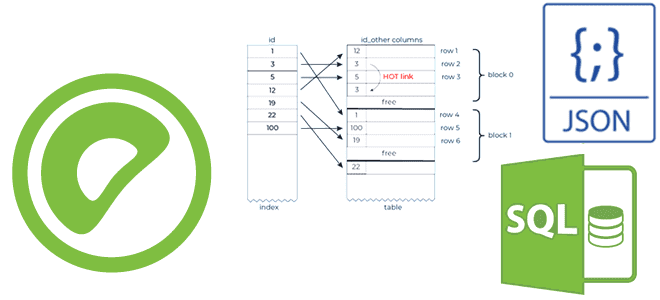
Как Greenplum индексирует JSON-документы, что такое GIN-индекс в PostgreSQL, чем он отличается от B-дерева и хэш-таблицы, когда и как их использовать, а также почему поддерживается только индексация JSONB-полей. Как Greenplum индексирует JSONB-документы Поскольку Greenplum основана на PostgreSQL, она также поддерживает работу со сложными типами данных и может вести себя подобно...

30 апреля 2024 года опубликован очередной выпуск ClickHouse, который включает 13 новых функций, 16 улучшений производительности и 65 исправлений ошибок. Знакомимся с самими интересными новинками релиза 24.4. Значимые новинки Clickhouse 24.2 Начнем с повседневных операций с таблицами: теперь в ClickHouse можно зараз удалить несколько таблиц со всем их содержимым, используя...
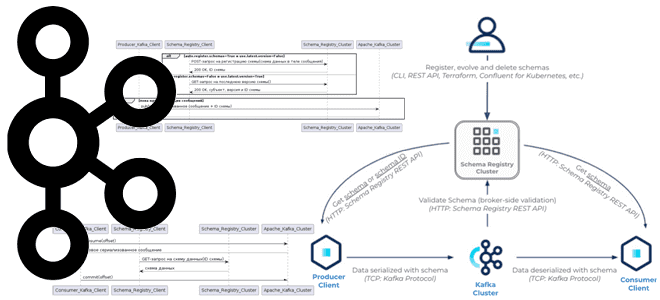
Почему клиентское приложение для публикации сообщений или их потребления из Kafka при использовании реестра схем существует в двух экземплярах, что добавляется к сериализованному сообщению, где хранится идентификатор схемы и другие тонкости работы с Confluent Schema Registry. Сериализация и десериализация сообщений с реестром схем Apache Kafka Недавно я показывала небольшую демонстрацию...
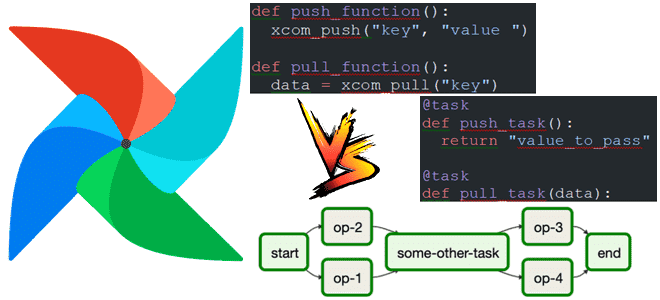
Чем API TaskFlow отличается от традиционных операторов Apache Airflow, можно ли их использовать вместе и как это сделать для более эффективной передачи данных между задачами DAG с помощью механизма XCom: несколько примеров. Что такое API TaskFlow в Apache Airflow Чтобы реализовать конвейер обработки данных в Apache AirFlow, можно использовать традиционные...

Что такое assert, зачем это нужно в тестировании и отладке, как эта конструкция применяется для сравнения датафреймов в PySpark: примеры работы функций assertDataFrameEqual() и assertSchemaEqual() в Apache Spark. Что такое assert: конструкция тестирования При разработке PySpark-приложения дата-инженер чаще всего оперирует такими структурами данных, как датафрейм. Датафрейм (DataFrame) – это распределенная...
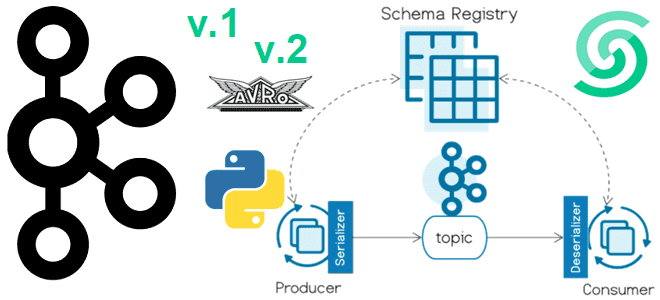
Версионирование схемы сообщений в формате AVRO с использованием реестра схем Apache Kafka и библиотеки confluent_kafka: практический пример на Python в Google Colab. Публикация сообщений в Kafka с использованием реестра схем Недавно я показывала пример использования реестра схем (Schema Registry) Apache Kafka при публикации сообщений. Сегодня рассмотрим версионирование схемы данных в...
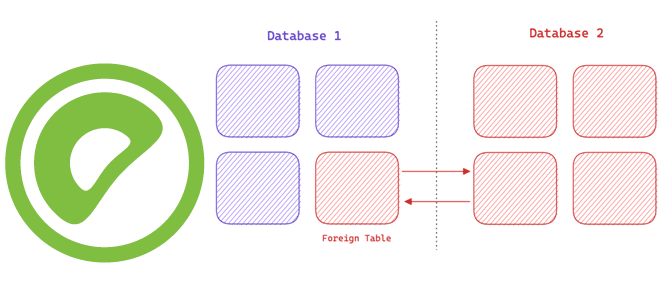
Чем внешняя таблица Greenplum отличается от сторонней, и как они преобразуются друг в друга: организация доступа к данным вне базы, FDW-обертки и протоколы для интеграции MPP-СУБД с другими источниками информации. Сторонняя таблица в Greenplum Термины внешняя (external) и сторонняя (foreign) table похожи, но нюансы их использования в Greenplum отличаются. Такие...
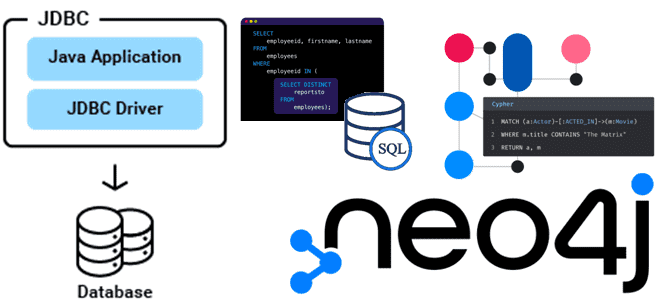
Что не так с общим Java-драйвером Neo4j, зачем нужен JDBC-драйвер, какие функции он поддерживает, а что не позволяет разработчику делать с этой графовой базой данных. Что не так с общим Java-драйвером Neo4j и зачем нужен JDBC-драйвер 25 марта 2024 года вышла 6-я версия драйвера JDBC для графовой СУБД Neo4j, поддерживаемого...
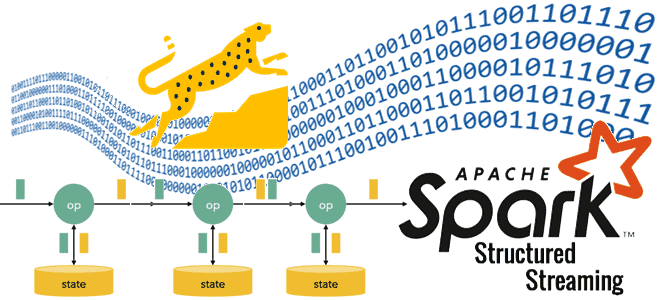
Где stateful-операторы хранят состояния, почему RocksDB лучше HDFSBackedStateStore и как Databricks адаптировал key-value хранилище к особенностям Spark Structured Streaming, чтобы сделать потоковую обработку больших данных еще быстрее. Где stateful-операторы Spark Structured Streaming хранят состояния? Хотя Apache Spark Structured Streaming реализует потоковую парадигму обработки информации, он по-прежнему использует микропакеты, т.е. ограниченные...

8 апреля 2024 года вышел очередной релиз Apache AirFlow. Знакомимся с ключевыми новинками выпуска 2.9: от функций работы с наборами данных до настроек внешнего объектного хранилища в качестве бэкенда XCom-объектов и особенностей поддержки Python 3.12. Наборы данных и гибкое планирование DAG Airflow Выпуск 2.9 содержит более 35 интересных новых функций,...
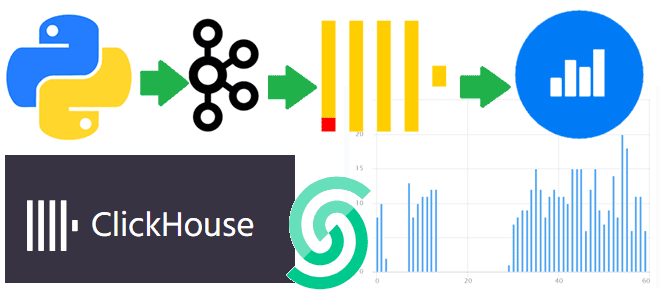
Как связать ClickHouse с Apache Kafka: примеры проектирования и реализации онлайн-аналитики с использованием облачного сервиса колоночной СУБД, брокера сообщений и BI-системы Яндекса. Постановка задачи и проектирование потокового конвейера Для взаимодействия с внешними хранилищами ClickHouse использует специальные механизмы – интеграционные движки таблиц. Вчера я показывала пример интеграции ClickHouse со встроенной key-value...