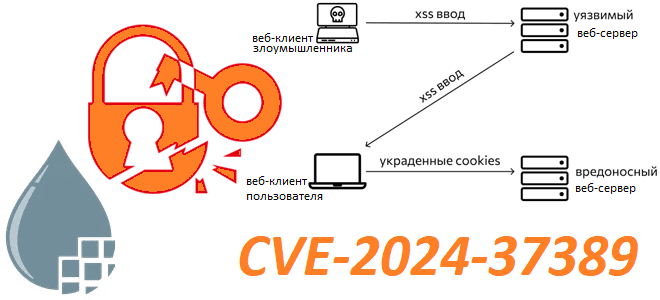
Как уязвимость CVE-2024-37389 может привести к выполнению произвольного кода в Apache NiFi: контекст параметров и межсайтовый скриптинг в веб-приложении для визуального проектирования конвейера обработки данных. Параметры свойств и их контекст в Apache NiFi 8 июля 2024 года в мажорном релизе Apache NiFi обнаружена уязвимость средней степени серьезности, связанная с неправильной...
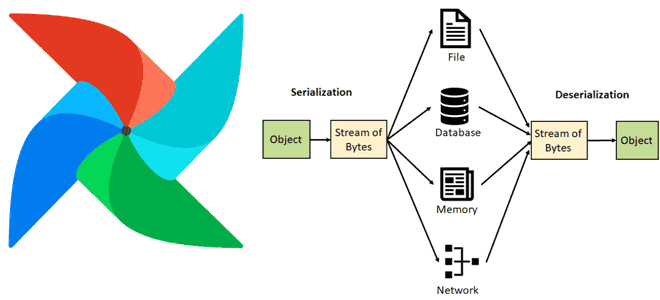
Как Apache AirFlow сериализует и десериализует данные, зачем с версии 2 включена обязательная сериализация DAG в JSON, почему для пользовательской сериализации рекомендуются словари или примитивы и что поможет сократить нагрузку на базу данных метаданных через настройку параметров сериализации в конфигурационном файле фреймворка. Сериализация данных в Apache AirFlow Чтобы сохранить данные...
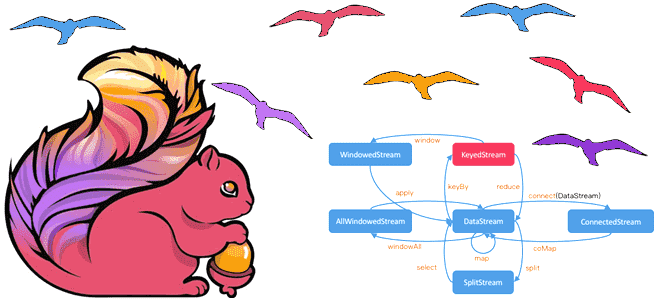
Чем DataSet API отличается от DataStream, зачем переходить с наборов на потоки данных в Apache Flink и как это сделать: эквивалентные и неподдерживаемые методы преобразования данных. Разница между DataStream и DataSet API Исторически в Apache Flink было 3 высокоуровневых API: DataStream/DataSet, Table и SQL. О возможностях и ограничениях каждого из...
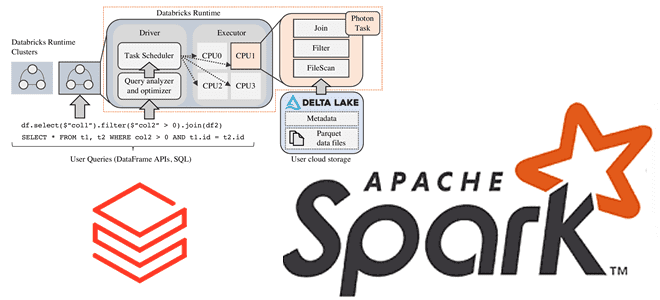
Зачем Databricks выпустила новый движок выполнения запросов Spark SQL для ML-приложений, как он работает и где его настроить: возможности и ограничения Photon Engine. Преимущества Photon Engine для ML-нагрузок Spark-приложений Чтобы сделать Apache Apark еще быстрее, разработчики Databricks выпустили новый движок выполнения запросов - Photon Engine. Это высокопроизводительный механизм запросов, который...
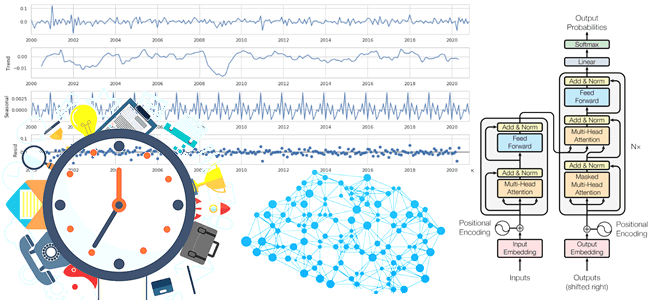
Почему генеративный ИИ хорошо подходит для прогнозирования временных рядов, как архитектура трансформеров учитывает влияние внешних переменных и сезонных факторов на измерения, и какие нейросетевые модели можно попробовать для этих задач. Проблемы прогнозирования временных рядов и их нейросетевые решения Прогнозирование временных рядов всегда было востребованной задачей в различных отраслях бизнеса. Временной...

24 августа вышел новый релиз Apache AirFlow. Знакомимся с новинками версии 2.10: гибкая настройка исполнителей для всей среды, конкретного DAG и отдельных задач, а также динамическое планирование набора данных и улучшения GUI. Гибкая настройка исполнителей Одной из самых главных новинок Apache AirFlow 2.10 стала конфигурация гибридного исполнения, позволяющая использовать несколько...

Зачем хранить данные в Apache Kafka постоянно и как это сделать: варианты использования и пример архитектурного решения Infinite Storage от Confluent Cloud, который лег в основу Tiered Storage. Infinite Storage от Confluent Cloud для бесконечного хранения данных в Apache Kafka Изначально Apache Kafka, как и любой другой брокер сообщений, не...

Разработчики ClickHouse с завидной регулярностью радуют новыми релизами. Не прошло и месяца, как опубликован очередной выпуск этой колоночной СУБД, версия 24.8 LTS от 20 августа 2024. О ее главных новинках читайте далее. Несовместимые изменения Начнем с самых важных и несовместимых изменений. В релизе ClickHouse 24.8 LTS для clickhouse-client и clickhouse-local...
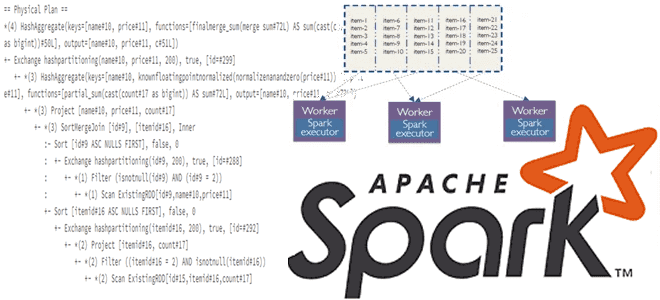
Что такое Dynamic Partition Pruning в Spark SQL, как работает этот метод оптимизации пакетных запросов, зачем его использовать в задачах аналитики больших данных, и каким образом повысить эффективность его практического применения. Что такое Dynamic Partition Pruning и зачем это нужно в Spark SQL Параллельная обработка данных в Apache Spark обеспечивается...
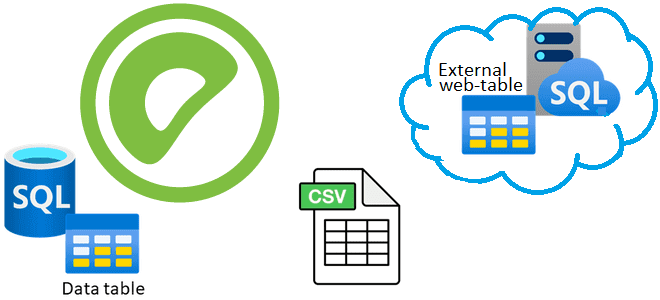
Что такое внешние веб-таблицы, зачем они нужны, чем отличаются от обычных external tables и как создать такую таблицу в Greenplum на основе команд и на основе URL. Зачем нужны внешние веб-таблицы в Greenplum О том, что в Greenplum есть внешние (external) и сторонние (foreign) таблицы, которые обеспечивают доступ к данным,...
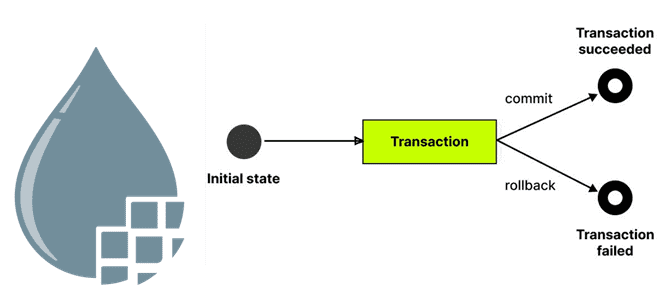
Зачем в Stateless-движке настраивать порт отказа, почему этот механизм в Apache NiFi подходит для надежных и транзакционных источников, но не для всех протоколов передачи данных, а также чем классический режим выполнения эффективнее в эксплуатации. Транзакционность операций с FlowFile в Apache NiFi О том, что Apache NiFi поддерживает два механизма выполнения:...

2 августа 2024 года вышел свежий релиз Apache Flink. Знакомимся с главными новинками выпуска 1.20 для упрощения потоковой обработки данных в мощных управляемых конвейерах: новые материализованные таблицы, единый механизм слияния файлов для контрольных точек, улучшения DataStream API и пакетных операций. Улучшения Flink SQL Начнем с новинок Flink SQL, одной из...

Как оповестить дата-инженера о задержке и результате выполнения задачи или всего DAG пакетного конвейера обработки данных: варианты отправки уведомлений в Apache AirFlow и особенности их применения. Варианты отправки уведомлений в Apache AirFlow Даже когда конвейер обработки данных разработан и успешно протестирован, в ходе его эксплуатации в рабочей среде неизбежно возникают...
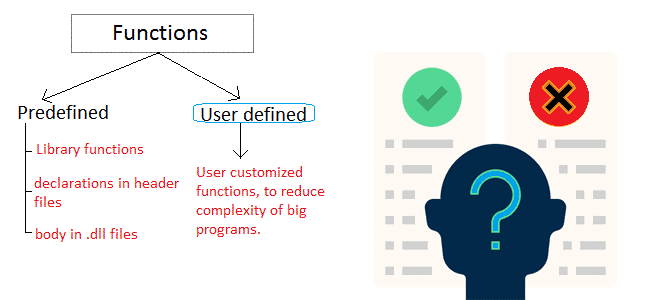
Почему пользовательские функции лучше применять как можно реже, каковы их возможности и ограничения: краткий обзор особенностей разработки и эксплуатации UDF в Apache Spark SQL, ksqlDB, Flink SQL, Greenplum и ClickHouse. Чем полезны и опасны пользовательские функции в обработке больших данных? Пользовательские функции (User-Defined Functions, UDF) позволяют разработчику расширить возможности фреймворка,...

Как расширить возможности ksqlDB, реализовав пользовательскую функцию обработки данных, хранящихся в топиках Kafka, с помощью SQL-запросов: ликбез по UDF и практический пример. Пользовательские функции в ksqlDB для работы с данными в топиках Apache Kafka Поскольку Apache Kafka – то не просто брокер сообщений, а целая экосистема потоковой передачи событий, вокруг...

Новая логика дедупликации данных, ограничения работы с матпредставлениями, дополнительные SQL-функции и улучшения производительности ClickHouse 24.7: краткий обзор ключевых особенностей июльского выпуска. Несовместимые изменения и новые фичи 30 июля 2024 года вышел очередной релиз ClickHouse, в котором довольно много изменений, несовместимых с прошлыми версиями. В частности, в реплицированных базах данных теперь...

29 июля 2024 года вышло очередное обновление Apache Kafka. Разбираемся с главными новинками релизе 3.8: поддержка JBOD в многоуровневом хранилище, детальная настройка уровня сжатия, улучшение безопасности и удаление неоднозначных конфигураций. ТОП-7 новинок Apache Kafka 3.8 Многоуровневое хранилище (Tiered Storage) для надежного долговременного хранения данных, опубликованных в Kafka, без ущерба высокой...

Какие процессоры Apache NiFi позволяют принимать и обрабатывать данные из различных источников по разным протоколам, и как избежать сбоев при их использовании с удержанием открытых соединений и порты. Listen-процессоры Apache NiFi В Apache NiFi есть целый набор процессов-слушателей, которые принимают и обрабатывают входящие данные из различных источников по разным протоколам....
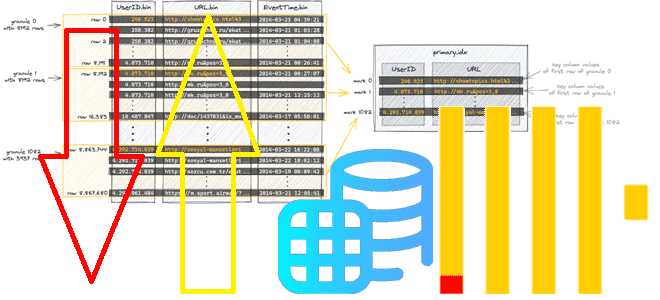
Зачем в ClickHouse 24.6 добавлена настройка optimize_row_order для оптимизации порядка строк MergeTree-таблиц, как она работает и где ее применять. Как связаны индексация и сортировка таблиц в ClickHouse Даже не будучи классической реляционной СУБД, ClickHouse поддерживает индексацию, насколько это возможно в его колоночной природе, индексируя первичным ключом целую группу строк (гранулу)...
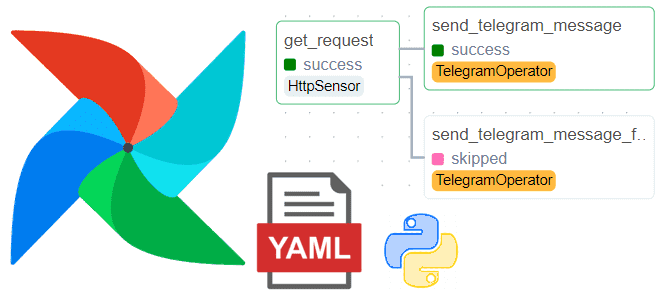
Как написать DAG в Apache AirFlow без программирования, определив его конфигурацию в YAML-файле, и автоматически получить пакетный конвейер обработки данных с помощью Python-библиотеки DAG Factory. Демократизация разработки ETL-конвейеров или что такое DAG Factory в Apache AirFlow Хотя Apache AirFlow и так считается довольно простым фреймворком для оркестрации пакетных процессов и...