 580
580 Содержание
В последних версиях Apache HIVE пытается внедрить CBO (cost based optimizer) и оптимизация операций JOIN одна из главных его составляющих. Поэтому понимание сценариев оптимизации применения операций JOINs (объединений) является одним из ключевых факторов настройки производительности HiveQL.
Рассмотрим каждый вид объединений на практических примерах и определим их различия:
Shuffle Join (Common Join) – общее объединение или объединение в случайном порядке
Этот вид объединений используется по умолчанию и включает map и reduce этапы для пофазного выполнения обьединения таблиц.
Mapper: считывает таблицы и выводит пары ключ-значение соединения в промежуточный файл.
Shuffle: пары ключ-значение сортируются и объединяются для передачи на соответствующий узел где будет выполнятся фаза Reduce.
Reducer: получает отсортированные данные и выполняет объединение (JOIN).
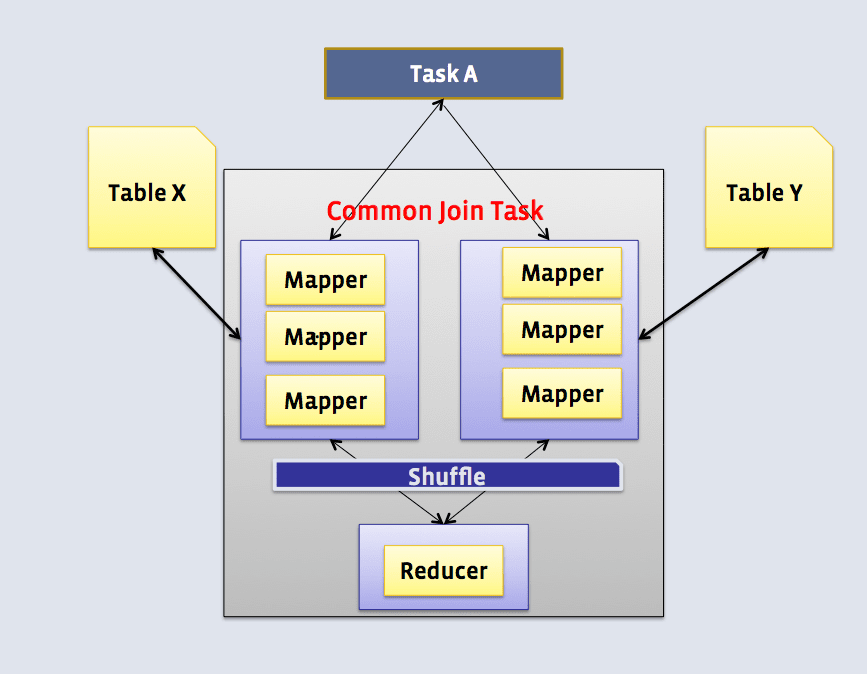
Варианты использования:
Работает для таблиц любого размера, особенно, когда другие типы объединений не могут быть использованы, например, полное внешнее объединение (FULL OUTER JOIN).
Недостатки:
Большая ресурсоемкость, так как shuffle – дорогостоящая операция. При выполнении операции Shuffle процесс mapper осуществляет сохранение промежуточных результатов на диск для последующей сортировки значений и передачи по сети на узел/узлы которые отвечают за финальное объединение данных таблиц.
Пример:
select a.* from passwords a, passwords2 b where a.col0=b.col1;
Подсказки:
Самая большая таблица должна быть поставлена справа, так как это должна быть потоковая таблица.
Однако вы можете использовать подсказку «STREAMTABLE», чтобы изменить таблицу потока на каждом этапе map-reduce.
select /*+ STREAMTABLE(a) */ a.* from passwords a, passwords2 b, passwords3 c where a.col0=b.col0 and b.col0=c.col0;
Map Join (Broardcast Join) в реализации Apache Hive
Если одна или несколько таблиц достаточно малы, чтобы поместиться в памяти, mapper просматривает большую таблицу и делает объединение. При этом может отсутствовать этап перемешивания (shuffle) и свертки (reduce).
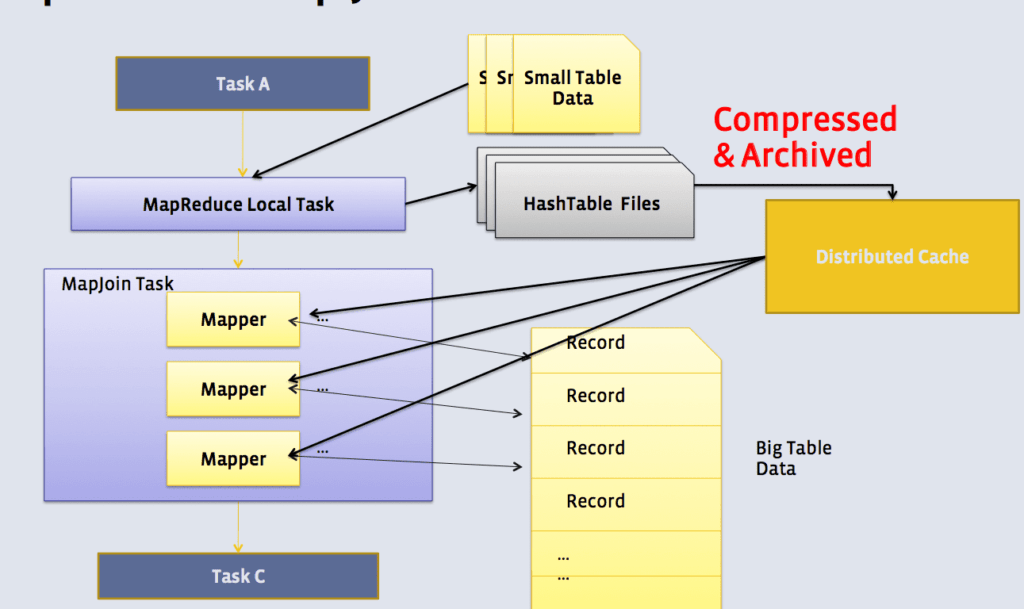
Варианты использования:
Существует маленькая таблица(справочник), которую необходимо объединить с большой. Как правило рамер маленькой таблицы определяется с помощью параметров Hive (25-30 МБ по умолчанию). Дополнительно можно увеличить фактор репликации для небольших по размеру таблиц в файловой системе HDFS для локального присутствия на всех узлах кластера Hadoop, что уменьшит необходимость копирования по сети данных.
Недостатки:
- Требуется чтобы по крайней мере одна таблица была достаточно мала.
- Правое/полное внешнее (RIGHT/FULL OUTER JOIN) объединение не работает.
Пример:
Здесь очень маленькой таблицей является — passwords, большой – passwords2.
select /*+ MAPJOIN(a) */ a.* from passwords a, passwords2 b where a.col0=b.col0 ;
Данная подсказка используется если параметр hive.ignore.mapjoin.hint = false (по умолчанию true в Apache Hive 0.13)
Подсказки:
- Автоматическое преобразование общего объединения common join в map join
- Необходимо настроить следующие конфигурационные параметры в hive-site.xml или непосредственно из оболочки Hive.
set hive.auto.convert.join=true; set hive.auto.convert.join.noconditionaltask=true;
- А также параметр в зависимости от размера данных
set hive.auto.convert.join.noconditionaltask.size
Bucket Map Join – соединение сегментами
Объединение выполняется только в mapper. Mapper обработки сегмента 1 для таблицы A будет получать только сегмент 1 из таблицы B.
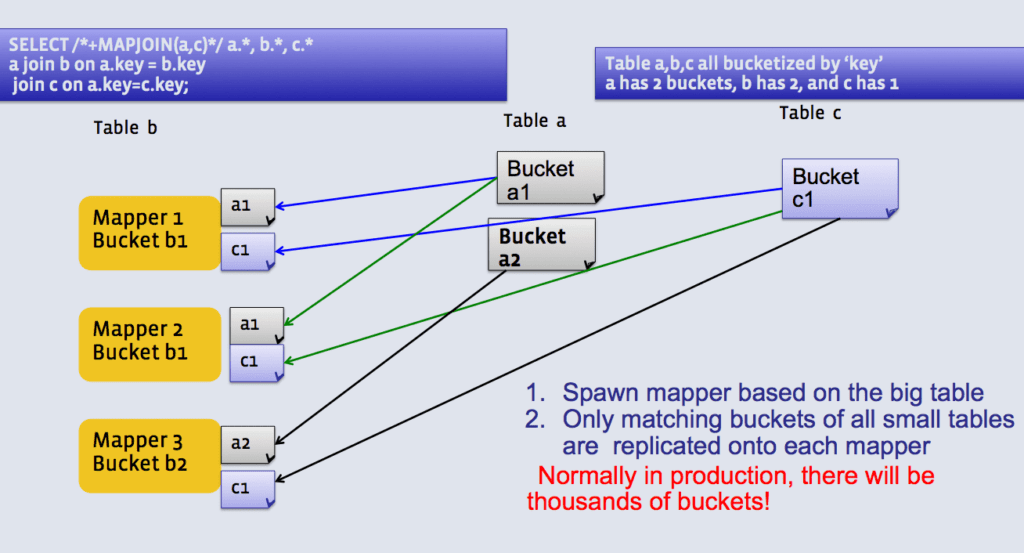
Варианты использования:
Когда все таблицы большие b количество сегментов в одной таблице должно быть кратно количеству сегментов в другой таблице.
Недостатки:
- Таблицы должны быть сегментированы по тем же полям, которые используются для соединения.
Пример:
create table b1(col0 string,col1 string,col2 string,col3 string,col4 string,col5 string,col6 string) clustered by (col0) into 32 buckets; create table b2(col0 string,col1 string,col2 string,col3 string,col4 string,col5 string,col6 string) clustered by (col0) into 8 buckets; set hive.enforce.bucketing = true; from passwords insert OVERWRITE table b1 select * limit 10000; from passwords insert OVERWRITE table b2 select * limit 10000; set hive.optimize.bucketmapjoin=true; select /*+ MAPJOIN(b2) */ b1.* from b1,b2 where b1.col0=b2.col0 ;
Skew Join — объединение таблиц в HiveQL для таблиц со смещением данных
Такой вид объединений используется если таблица A объединяется с таблицей B, но A содержит смещенные данные (Skew Data) (т.е. содержит значения, которые преобладают) в колонке объединения.
Необходимо:
- Прочитать таблицу B и сохранить строки с ключом в хэш-таблице в памяти
- Запустить mapper для чтения A и выполнить следующие действия:
- если ключ совпадает использовать хэшированную версию B для вычисления результата
- остальные ключи отправляются на reducer , который делает объединение. Этот reducer будет получать строки из B также из mapper.
Таким образом, мы считываем B дважды, ключи со смещением в A прочитаны и обработаны только mappers и не отправляются к reducer . Остальные ключи в A проходят через один этап map-reduce.
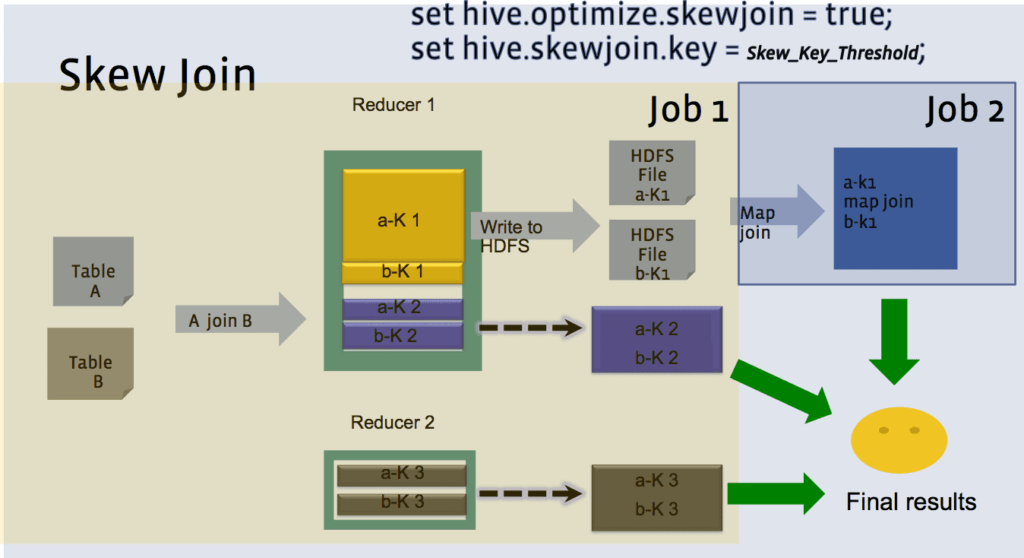
Варианты использования:
Одна таблица должна иметь смещенные значения в колонке по которой выполняется объединение.
Недостатки:
- Одна таблица читается дважды.
- Data Skew (Перекос в данных) должен быть определен заранее
Пример:
Должен быть установлен параметр для включения соединения со смещением,
set hive.optimize.skewjoin = true;
так же как и параметр с количеством строк, который показывает, что ключ является смещенным, если имеет значение больше указанного.
set hive.skewjoin.key=100000; select a.* from passwords a, passwords2 b where a.col0=b.col1;
Подсказки:
Начиная с Apache Hive 0.10.0, таблицы могут быть созданы как смещенные (Data Skew). Поэтому, определив ключи, которые имеют явное смещение, Apache Hive сможет автоматически разбить их на отдельные файлы и в последующем учитывает этот факт во время запросов, чтобы он мог пропустить или включить весь файл, если это возможно.
CREATE TABLE list_bucket_single (key STRING, value STRING) SKEWED BY (key) ON (1,5,6) [STORED AS DIRECTORIES];
В этом примере показан один столбец с тремя смещенными значениями. Используйте параметр STORED AS DIRECTORIES, который определяет сегментирование таблицы.
Приглашаем вас на курс по аналитике данных с использованием HiveQL на базе Apache Hive в нашем учебном центре «Школа Больших Данных», где вы сможете на практических примерах разобрать все используемые в статье примеры работы с различными видами объединений таблиц ( JOIN)

