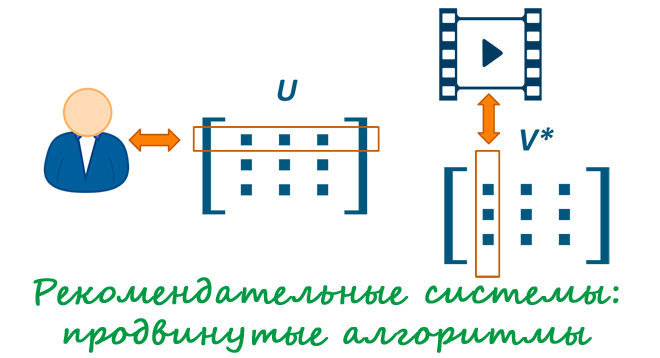
В прошлой статье мы разобрали методы построения рекомендательных систем: коллаборативная фильтрация; фильтрация на контенте; фильтрация на знаниях; гибридный подход. Мы намеренно не упомянули об одном важном подходе построения рекомендаций: об использовании матричных разложений. Описание данного метода заслуживает отдельной статьи! Будем эксплуатировать традиционный для рекомендательных систем кейс рекомендации фильмов пользователям. Напомним,...
Что такое непрерывное машинное обучение, как оно работает и при чем здесь MLOps. Почему сложно вести разработку ML-моделей в стиле CI/CD и как CML помогает обойти эти ограничения. Автоматизация процессов непрерывной интеграции и доставки с помощью open-source CLI-инструмента от Iterative.ai. Трудности CI/CD в Machine Learning и MLOps Поддерживаемые DevOps-концепцией идеи...

Как быстро и эффективно с помощью Neo4j выявить преступников, незаконно ввозящих в страну контрафактные товары. Почему графовая СУБД Neo4j обошла документо-ориентированную MongoDB, из чего состоит алгоритм поиска рецидивистов средствами технологий аналитики больших данных и как это может пригодиться в других бизнес-приложениях. Постановка задачи: сложности отслеживания контрафакта Каждый день практически в...
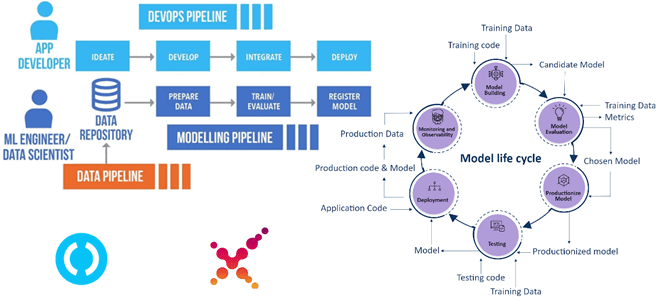
Чтобы сделать наши курсы для специалистов в области Data Science и ML-инженеров еще более полезными, сегодня рассмотрим, как организовать сквозной CI/CD-конвейер разработки и развертывания системы машинного обучения в соответствии с MLOps-концепцией на 4-х популярных Python-инструментах: MLflow, DVC, Airflow, ClearML. А в качестве примера практической реализации этой идеи разберем кейс банка...

Практически на каждом маркетплейсе есть раздел с рекомендованными товарами, фильмами, объявлениями и т.д. Сервисы аудиокниг предлагают пользователям обратить внимание на определенные аудиокниги, которые выбираются исходя из предпочтений пользователя. Площадки с объявлениями стремятся показать наиболее интересные для пользователя объявления в разделе рекомендаций. Примеры есть практически на каждом интернет ресурсе. Давайте разберемся...
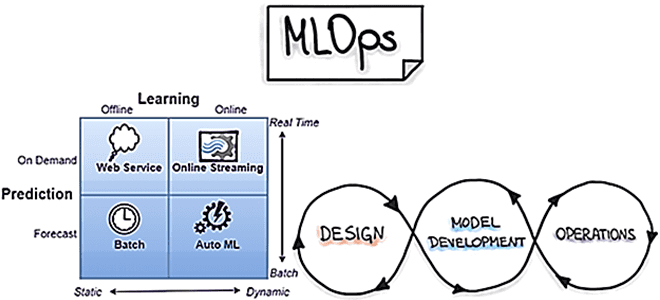
Сегодня рассмотрим наиболее распространенные в MLOps стратегии развертывания, т.е. подходы к внедрению моделей машинного обучения в производство. Выбор стратегии зависит от бизнес-требований и от контекста применения результатов ML-моделирования. Какие бывают стратегии и как они реализуются: краткий ликбез с примерами для ML-инженеров и MLOps-специалистов. Пакетное прогнозирование и веб-сервисы для MLOps Это...
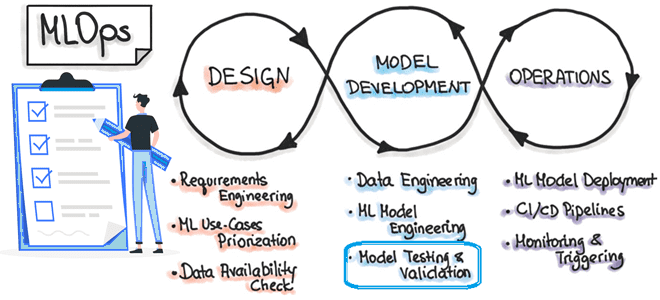
Поскольку разработка и развертывание ML-систем отличаются от традиционного ПО, о чем мы писали здесь и здесь, процесс тестирования модели машинного обучения тоже имеет свою специфику, которую учитывает концепция MLOps. Читайте далее, что и как тестировать при разработке систем Machine Learning, а также при чем здесь подход Arrange-Act-Assert. MLOps и тестирование...

Недавно мы писали про сложности разработки и развертывания ML-систем и способы их решения с помощью концепции MLOps. Продолжая эту тему, важную для обучения специалистов по Data Science, аналитиков и инженеров данных, сегодня рассмотрим основные некоторые преимущества фреймворка MLFlow для создания надежных конвейеров CI/CD в системах машинного обучения. CI/CD в MLOps...

Постоянно добавляя в наши курсы по Apache Spark и машинному обучению практические примеры для эффективного повышения квалификации Data Scientist’ов и инженеров данных, сегодня рассмотрим задачу пакетного прогнозирования и планирование ее запуска по расписанию без применения масштабных MLOps-решений. Apache Spark для пакетного прогнозирования Есть много готовых решений и инструментов для пакетного...
Обучая специалистов по Data Science, аналитиков и инженеров данных лучшим практикам MLOps, сегодня поговорим про переносимость моделей машинного обучения между разными этапами жизненного цикла ML-систем, от разработки до развертывания в production. А в качестве примера разберем, как использовать обученную ML-модель из Apache Spark за пределами кластера, упаковав ее в ONNX...
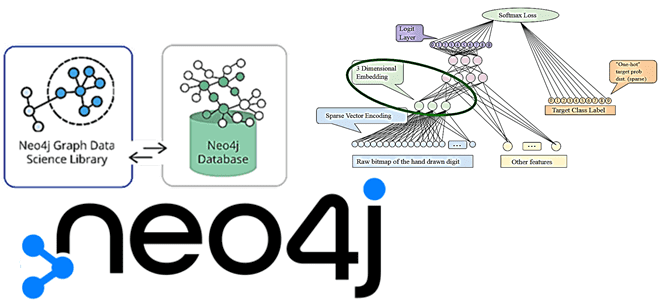
В рамках нашего нового курса графовым алгоритмам в бизнес-приложениях, сегодня разберем эмбеддинг-алгоритмы в библиотеке Graph Data Science СУБД Neo4j: их особенности и возможности практического использования для задач обработки естественного языка (NLP). Также рассмотрим, чем FastRP отличается от GraphSAGE с Node2Vec. NLP, эмбеддинги и Graph Data Science В обработке естественного языка...

В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза. MLOps с AirFlow и MLFlow в облаке AWS Ранее...
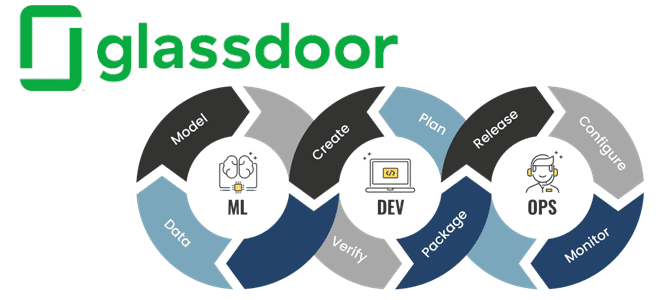
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana. Предыстория: зачем MLOps в Glassdoor Glassdoor с 2008 года помогает соискателям по всему миру...
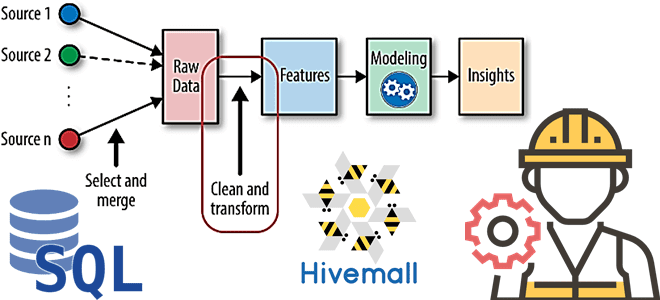
В рамках наших курсов для дата-инженеров и специалистов в области Data Science, сегодня рассмотрим, как реализовать один из важнейших этапов машинного обучения – Feature Engineering. Читайте далее, как генерировать признаки для ML-модели с помощью SQL, напрямую обращаясь к источникам данных и хранилищам фич, а также что такое Apache Hivemall и...

Недавно мы рассказывали про оптимизацию SQL-запросов в PXF – интеграционном фреймворке Greenplum. Сегодня рассмотрим, как этот способ обращения к внешним источникам данных можно применить к задачам машинного обучения на примере распознавания изображений. Platform Extension Framework как инструмент извлечения и преобразования изображений из облачных объектных хранилищ для обучений глубоких нейросетей с...

MLOps и построение конвейеров машинного обучения – одни из самых актуальных задач современной Data Science. Сегодня рассмотрим, чем совместное использование Apache Airflow и Ray полезно для дата-инженера и ML-разработчика. Читайте далее про кластерное развертывание Python-кода ML-моделей и упрощение ETL-процессов с Apache Airflow и Ray. Apache AirFlow для ML: возможности и...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...

Сегодня рассмотрим Apache Spark с точки зрения Data Science специалиста: поговорим про сходства и отличия библиотек машинного обучения в этом фреймворке. Также ответим на вопрос «Spark ML vs MLLib», разберем, зачем Data Scientist’у и аналитику больших данных нужны курсы по Apache Spark, а в заключение отметим наиболее важные улучшения библиотеки...

В рамках обучения аналитиков Big Data и разработчиков Apache Spark и Kafka, сегодня рассмотрим кейс ИТ-компании Southworks по онлайн-обработке потокового видео как наглядный пример эффективного сочетания этих потоковых фреймворков с пакетными задачами. Читайте далее, как реализовать лямбда-архитектуру масштабируемой Big Data системы на базе Apache Kafka, Spark Structured Streaming и NoSQL-СУБД...

Продвигая наши курсы для разработчиков Spark с примерами реальных систем аналитики больших данных, сегодня рассмотрим библиотеку для чтения файлов формата DICOM от индийской компании Abzooba. Читайте далее, как автоматизировать поиск по миллиардам медицинских изображений с помощью машинного обучения и технологий Big Data: Apache Spark, Hadoop, Kafka, Elasticsearch и Kibana. Что...