 959
959 
Как Quix Streams реализует отказоустойчивую stateful-обработку потоковых датафреймов из топиков Kafka с помощью встроенного key-value хранилища состояний RocksDB: практический пример.
Потоковый stateful-конвейер на Apache Kafka и Quix Streams
Продолжая знакомиться с библиотекой Quix Streams, которая позволяет получить потоковые датафреймы из данных в топиках Kafka, сегодня разберем, как здесь организована работа с сохранением состояния. Quix Streams поддерживает stateful-обработку со встроенным бэкендом RocksDB. Это key-value хранилище позволяет сохранять данные о состоянии и использовать их во время потоковой обработки.
В качестве практического примера возьмем приложение из вчерашней статьи, которое потребляет входные данные в потоковый датафрейм из топика InputsTopic, обогащает их и записывает в топик CorpAppsTopic. Это приложение одновременно является и продюсером и потребителем Kafka. В топик InputsTopic постоянно публикуются входящие события пользовательского поведения: заявки на покупку продуктов в интернет-магазине или вопросы покупателей. Приложение app подключается к брокеру Kafka, считывает эти данные в потоковый датафрейм sdf, и, если это заявка на покупку продукта, добавляет к ней номер, а потом записывает это дополненное сообщение в топик CorpAppsTopic. В топике входящих данных InputsTopic 3 раздела, в каждом из которых сообщения хронологически упорядочены. Предположим, необходимо поддерживать сквозную нумерацию заявок, продолжая ее при перезапуске приложения. Для этого надо записывать во встроенное хранилище состояний RocksDB счетчик количества заявок app_counter и использовать это значение при перезапуске приложения, не рассчитывая количество заявок с 0, а продолжая предыдущий счетчик.
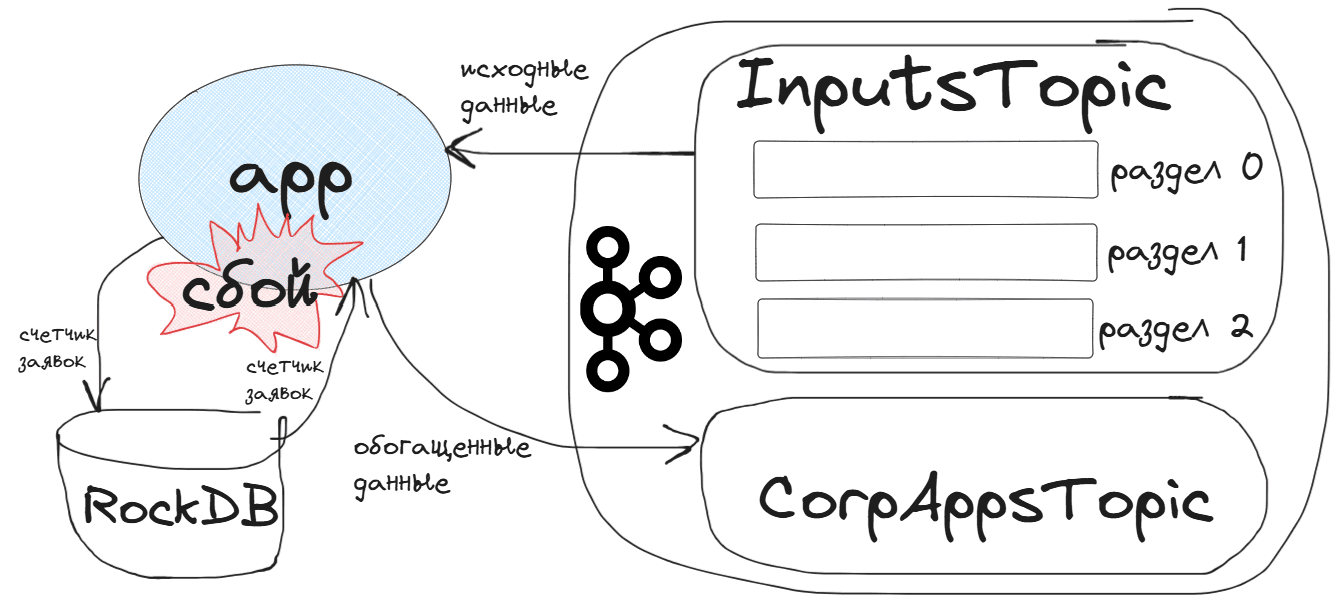
Библиотека Quix Streams не позволяет подписать приложение на определенный раздел топика Kafka, только сразу на весь топик, т.е. все разделы. Однако, в Quix Streams состояние зависит от ключа сообщения из-за разделения топика Kafka на разделы. Состояние каждого ключа сообщения Kafka независимо и недоступно для всех остальных, кроме текущего активного ключа сообщения. Каждый ключ может принадлежать к разным разделам топика Kafka, а разделы автоматически назначаются и переназначаются брокером Kafka приложениям-потребителям в одной группе. Это означает, что хранилище состояний в Quix Streams хранит данные по разделам топиков и автоматически реагирует на изменения в назначении разделов. Каждый раздел имеет свой собственный экземпляр RocksDB, поэтому данные из разных разделов хранятся отдельно, что позволяет выполнять параллельную обработку разделов. Данные о состоянии также хранятся для каждого ключа, поэтому обновления для сообщений с определенным ключом видны только для сообщений с тем же самым ключом.
Состояние доступно в функциях потокового датафрейма StreamingDataFrame: apply(),update() и filter()с параметром stateful=True. Вот как это выглядит в коде:
!pip install quixstreams
from quixstreams import Application,State
from quixstreams.kafka.configuration import ConnectionConfig
# Подключение к Kafka
connection = ConnectionConfig(
bootstrap_servers=kafka_url,
security_protocol="SASL_SSL",
sasl_mechanism="SCRAM-SHA-256",
sasl_username=username,
sasl_password=password
)
# Приложение для Kafka
app = Application(broker_address=connection, state_dir='/content/state')
# Определение топиков
inputs_topic = app.topic("InputsTopic", value_deserializer="json")
outputs_topic = app.topic("CorpAppsTopic", value_serializer="json")
# Потоковый датафрейм из входного топика Kafka
sdf = app.dataframe(topic=inputs_topic)
# Функция для нумерации заявок с использованием состояния
def count_apps(value: dict, state: State):
if value is None:
return None
# Получаем текущее значение счетчика из хранилища состояний
app_counter = state.get('app_counter', default=0)
app_counter += 1
state.set('app_counter', app_counter)
print('app_counter = ', app_counter)
# Возвращаем обновленное значение с добавленным номером заявки
return {**value, 'app_counter': app_counter}
# Обновлённая функция для выявления заявок
def extract_apps(message):
try:
content_parts = message["content"].rsplit(' ', 1)
if len(content_parts) != 2:
raise ValueError("Это не заявка на покупку")
product, quantity_str = content_parts
quantity = int(quantity_str)
return {
"id": message["id"],
"name": message["name"],
"subject": message["subject"],
"product": product,
"quantity": quantity
}
except Exception as e:
error_str = f"Ошибка: {str(e)}, Сообщение: {message}\n"
with open("dlq.txt", "a") as f:
f.write(error_str)
print(f"Ошибка: {str(e)}")
return None
# вывести метаданные сообещения
sdf = sdf.update(lambda _: print('Текущее смещение = ', message_context().offset, 'Раздел = ', message_context().partition))
# Применяем функцию к датафрейму
sdf_apps = sdf.apply(extract_apps)
# Используем stateful=True, чтобы включить использование встроенного состояния
sdf_apps = sdf_apps.apply(count_apps, stateful=True)
# Фильтруем только успешные преобразования
sdf_valid_apps = sdf_apps.filter(lambda x: x is not None)
sdf_valid_apps.print()
# Записываем преобразованные данные в выходной топик Kafka
sdf_valid_apps.to_topic(outputs_topic)
# Запускаем потоковое приложение
app.run()
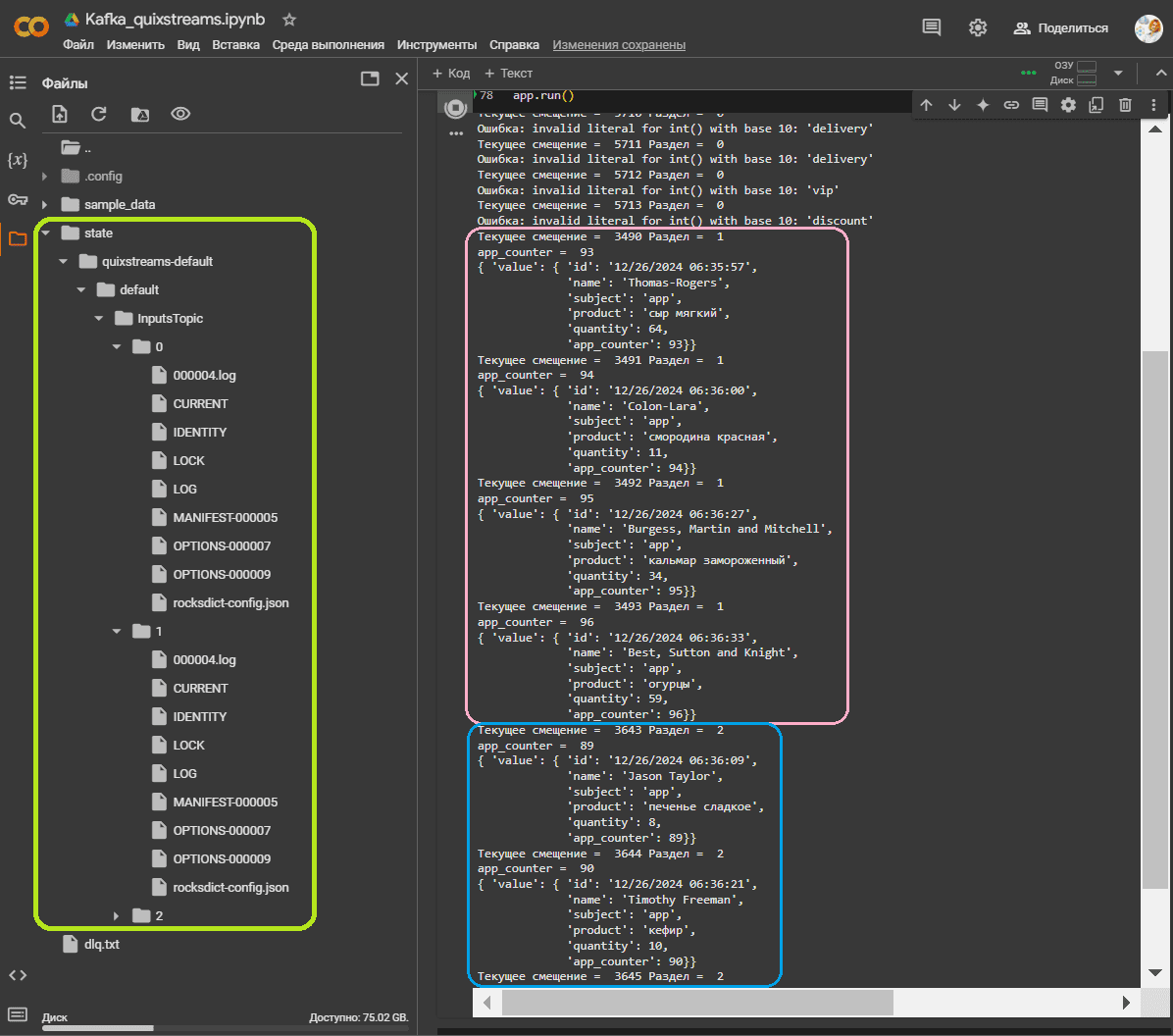
Этот код обрабатывает поток сообщений, извлекая и нумеруя заявки на покупку, а затем отправляет их в другой топик для дальнейшей обработки. Stateful-функция count_apps() нумерует каждую заявку, используя состояние для хранения и обновления счетчика заявок. В качестве хранилища состояний используется встроенная key-value база данных RocksDB, причем в 3-х экземплярах – для каждого раздела топика с входящими данными. Функция extract_apps обрабатывает каждое сообщение, извлекая информацию о заявке на покупку. Если сообщение не соответствует ожидаемому формату, исключение записывается в файл с ошибками dlq.txt.
Для того, что показать, что нумерация сообщения сквозная по каждому разделу, но не по всему топику, я дополнительно вывожу в консоль текущие метаданные потребленного сообщения: смещение и раздел. Обработанные и отфильтрованные данные о заявках из InputsTopic выводятся на экран и отправляются в выходной топик CorpAppsTopic.
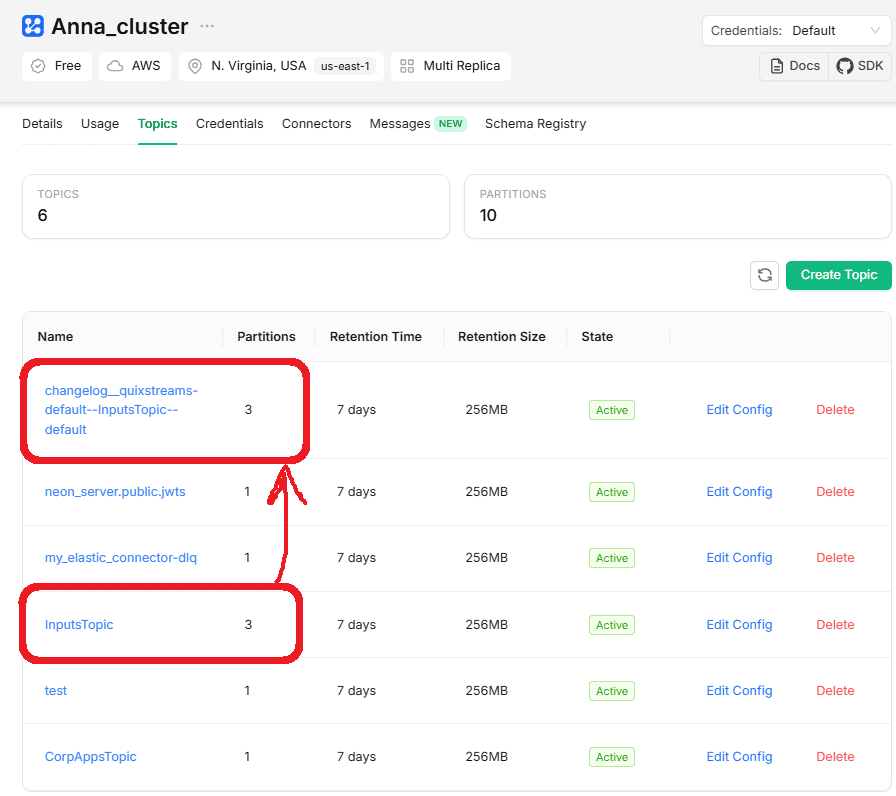
Чтобы предотвратить потерю данных о состоянии в случае сбоев, все локальные хранилища состояний в Quix Streams поддерживаются топиком журнала изменений в Kafka. Это скрытый топик, внутренний топик Kafka, который Quix Streams использует для учета изменений состояния хранилища состояний. Топики журнала изменений используют те же механизмы репликации Kafka, что делает данные о состоянии высокодоступными и долговечными. Это включено по умолчанию. Класс Application автоматически создает и управляет ими для каждого используемого хранилища состояний. Топик журнала изменений имеет то же количество разделов, что и исходный, чтобы гарантировать возможность переназначения разделов между потребителями. Они также сжимаются, чтобы предотвратить их неограниченный рост.
При запуске приложения оно автоматически проверяет, какие хранилища состояний необходимо создать. Оно гарантирует, что топики журнала изменений существуют для этих хранилищ. Если во время обработки ключ обновляется в хранилище состояний, обновление будет отправлено как в топик журнала изменений, так и в локальное хранилище состояний. Когда приложение перезапускается или к группе присоединяется новый потребитель, оно проверяет, обновлены ли хранилища состояний с топиками журнала изменений. Если нет, приложение сначала обновит локальные хранилища, и только потом продолжит обработку сообщений.
Например, в моем случае был создан топик changelog__quixstreams-default—InputsTopic—default, который тоже имеет 3 раздела, как и исходный InputsTopic.
Узнайте больше про построение сложных архитектур данных и использование Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

