 1101
1101 
Быстрая и простая обработка потоков сообщений в одном приложении с Quix Streams вместо Kafka Streams: практический пример на Python с обогащением и фильтрацией данных.
Практический пример потокового конвейера с Apache Kafka и Quix Streams
Сегодня я познакомилась с Quix Streams — очередной замечательной библиотекой для создания потоковых конвейеров обработки данных на Python. Она работает подобно Kafka Streams, но использует Python вместо Java. Quix Streams позволяет строить потоковые конвейеры обработки данных в реальном времени, используя знакомые каждому дата-инженеру датафреймы с гарантиями масштабируемости, отказоустойчивости и долговечности Kafka. Помимо API потоковых данных датафреймов, включая оконные и агрегатные функции, библиотека поддерживает API сериализаторов JSON, Avro, Protobuf и реестра схем, а также stateful-обработку со встроенным бэкендом RocksDB. Гарантии однократной обработки с помощью транзакций Kafka позволяют использовать Quix Streams для создания простых приложений продюсеров и потребителей, а также разрабатывать сложные потоковые системы, управляемые событиями.
Рассмотрим в качестве примера приложение, которое потребляет входные данные в потоковый датафрейм из одного топика Kafka (InputsTopic), обогащает их и записывает в другой топик (CorpAppsTopic). Таким образом, одно и то же приложение одновременно является и продюсером и потребителем Kafka.
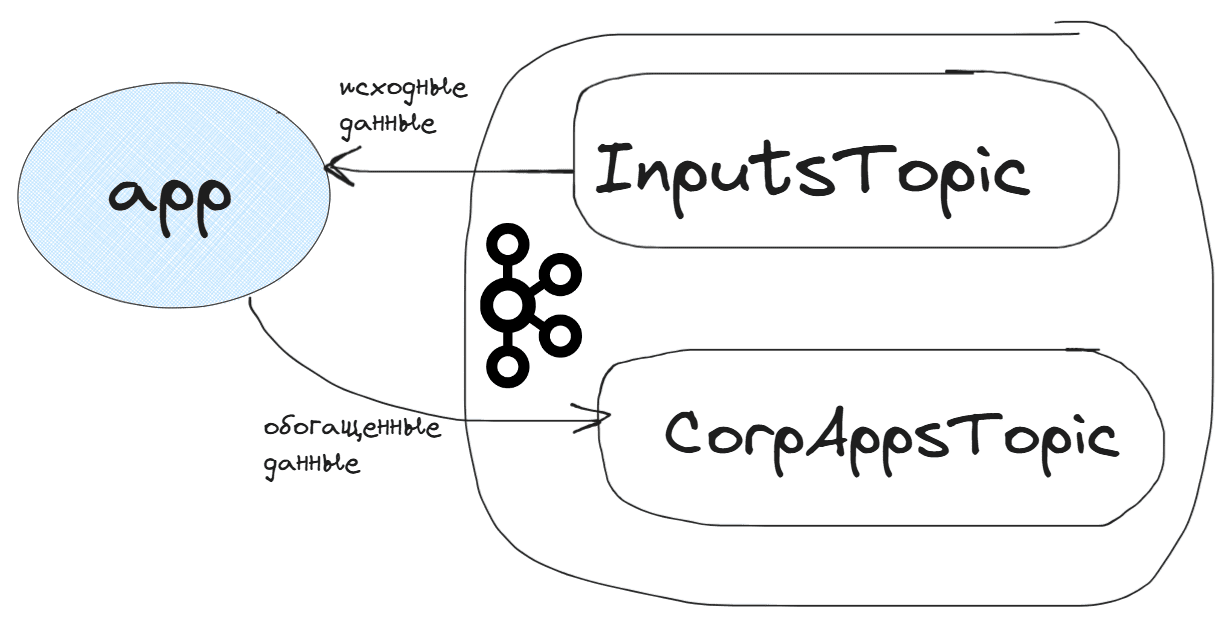
Основным интерфейсом для определения конвейеров потоковой обработки в Quix Streams является StreamingDataFrame. Он позволяет обрабатывать и преобразовывать данные из одного формата в другой, обновляя и фильтруя их прямо в потоке. Операции с потоковыми данными при этом похожи на работу с обычным датафреймом pandas. StreamingDataFrame поддерживает концепцию отложенных (ленивых) вычислений и является конвейером, который содержит все преобразования для входящих сообщений. При этом он не сохраняет фактически потребленные данные в памяти, а только объявляет, как они должны быть преобразованы. Все манипуляции с StreamingDataFrame могут быть добавлены как по отдельности, так и в виде цепочки. Также можно разветвить конвейер для создания нескольких путей выполнения. Все потоковые датафреймы, сгенерированные с помощью конструкций Applicationwith, Application.dataframe() будут автоматически обнаружены и запущены при запуске потокового приложения Application.run().
В моем примере внешнее приложение-продюсер публикует в топик InputsTopic с входящие события пользовательского поведения: заявки на покупку продуктов в интернет-магазине или вопросы покупателей. Приложение app подключается к брокеру Kafka, считывает эти данные в потоковый датафрейм sdf, и, если это заявка на покупку продукта, добавляет к ней номер, а потом записывает это дополненное сообщение в топик CorpAppsTopic.
Код потокового приложения с библиотекой Quix Streams выглядит так:
!pip install quixstreams
from quixstreams import Application
from quixstreams.kafka.configuration import ConnectionConfig
connection = ConnectionConfig(
bootstrap_servers=kafka_url,
security_protocol="SASL_SSL",
sasl_mechanism="SCRAM-SHA-256",
sasl_username=username,
sasl_password=password
)
# приложение для Kafka
app = Application(broker_address=connection)
# определение топиков
inputs_topic = app.topic("InputsTopic", value_deserializer="json")
outputs_topic = app.topic("CorpAppsTopic", value_serializer="json")
# потоковый датафрейм из входного топика Kafka
sdf = app.dataframe(topic=inputs_topic)
# Счётчик для нумерации заявок
app_counter = 0
# Функция для выявления заявок
def extract_apps(message):
global app_counter
try:
content_parts = message["content"].rsplit(' ', 1)
if len(content_parts) != 2:
raise ValueError("Это не заявка на покупку")
product, quantity_str = content_parts
quantity = int(quantity_str)
app_counter += 1 # Увеличиваем счётчик при успешной обработке
return {
"id": message["id"],
"name": message["name"],
"subject": message["subject"],
"product": product,
"quantity": quantity,
"app_number": app_counter # Добавляем номер заявки
}
except Exception as e:
# запись ошибок в лог-файл на Google Диске
error_str = f"Ошибка: {str(e)}, Сообщение: {message}\n"
with open("dlq.txt", "a") as f:
f.write(error_str)
print(f"Ошибка: {str(e)}")
return None # Возвращаем None, если произошла ошибка
# применяем функцию к датафрейму
sdf_apps = sdf.apply(extract_apps)
# Фильтруем только успешные преобразования
sdf_valid_apps = sdf_apps.filter(lambda x: x is not None)
sdf_valid_apps.print()
# Записываем преобразованные данные в выходной топик Kafka
sdf_valid_apps.to_topic(outputs_topic)
# Запускаем потоковое приложение
app.run()
При запуске потокового приложения сперва выполняется проверка подключения, затем валидация наличия указанных топиков и возможности работы с ними, а также инициализация хранилища состояний, о котором я расскажу в другой раз. После всех проверок, наконец, начинается потребление сообщений в потоковый датафрейм и его обработка. Для записи данных в другой топик создается новый потоковый датафрейм, каждая строка которого публикуется в Kafka методом to_topic().
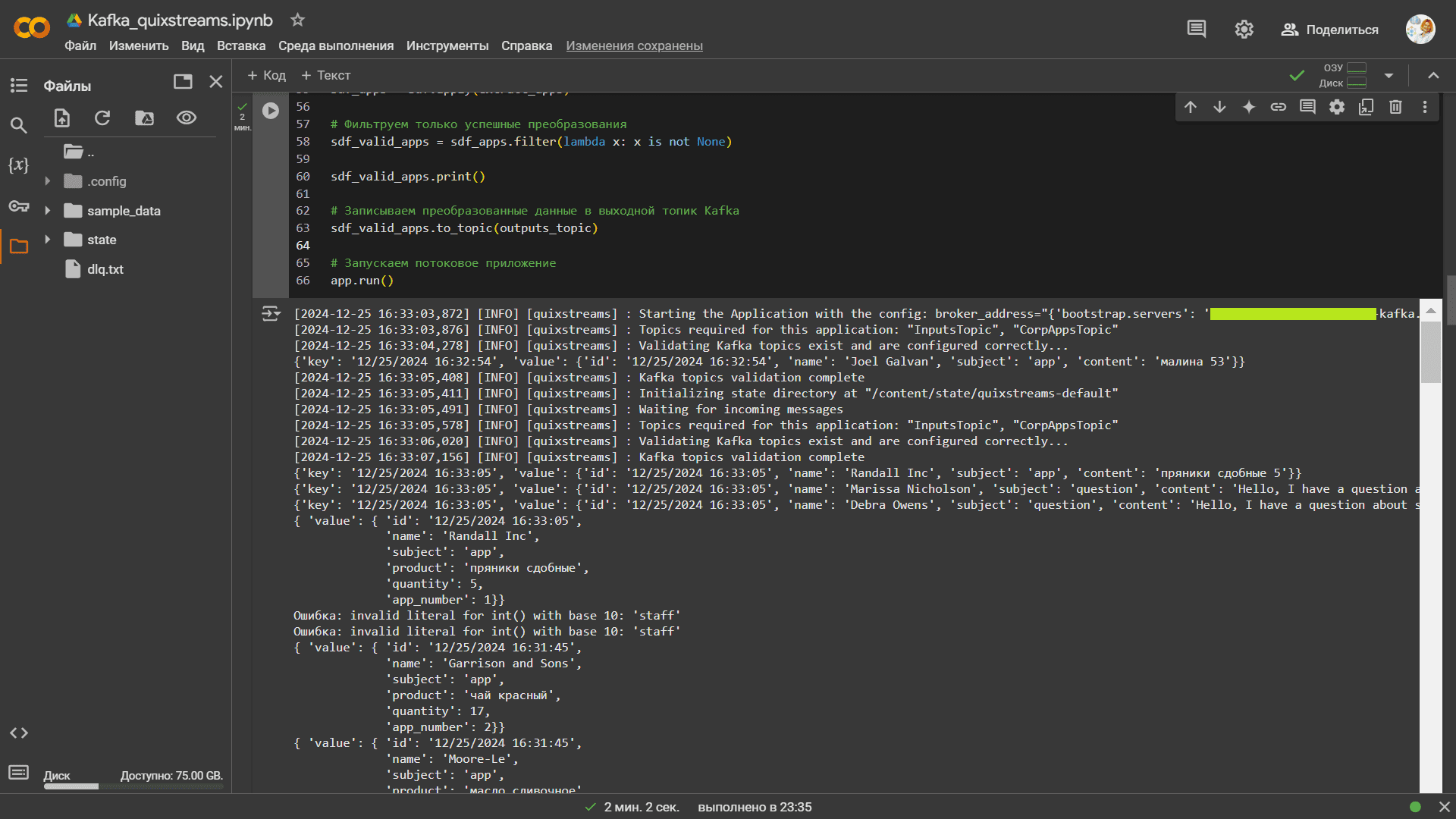
Таким образом, по сравнению с классическими клиентами Kafka, такими как kafka-python или confluent-kafka, Quix Streams предоставляет довольно удобный интерфейс для работы с потоками данных, скрывая сложность низкоуровневых настроек этой платформы потоковой передачи событий. Возможность работать с потоками данных как с обычным датафреймом упрощает разработку и позволяет быстрее создавать приложения. Из интересных и полезных функций этой библиотеки стоит особенно отметить stateful-обработку и обновление потоковых данных в реальном времени. Об этом я расскажу в следующих статьях.
Узнайте больше про построение сложных архитектур данных и использование Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

