
Специально для обучения дата-инженеров и администраторов кластера Apache Kafka, сегодня разберем, как обеспечить безопасность клиента этой распределенной платформы потоковой передачи событий по REST API с помощью возможностей открытого ПО. Что такое PEM-файлы и при чем здесь SSL-сертификаты, а также другие криптографические средства защиты данных: кейс инженеров Expedia Group. Инструменты обеспечения...

Как найти компромисс между задержкой, пропускной способностью, долговечностью и доступностью в Apache Kafka: проблемы CAP-теоремы и поиски оптимальной стороны PACELC-ромба. Архитектурные ограничения распределенных систем и лучшие практики для настройки конфигурационных параметров для администратора кластера Apache Kafka и дата-инженера потоковых приложений аналитики больших данных. CAP-теорема и распределенные системы На производительность Apache...

Сегодня рассмотрим опыт международной компании Emumba, которая специализируется на инженерии и аналитике больших данных. Читайте далее, как выгодно масштабировать конвейер потоковой передачи данных от миллионов устройств интернета вещей, используя Apache Kafka, KStream и Druid в облачной инфраструктуре AWS. Архитектура PoC для потоковой передачи событий от миллионов IoT-устройств Миллионы устройств интернета...
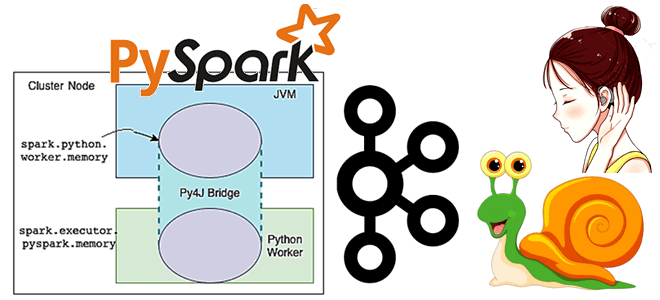
Чтобы добавить в наши курсы для дата-инженеров и разработчиков распределенных приложений еще больше практических примеров, сегодня рассмотрим, как написать Python-код для вычисления задержки потребителя Apache Kafka, расширив типовой слушатель StreamingQueryListener, который есть в Java и Scala API библиотеки Spark Structured Streaming, но недоступен в PySpark. Проблема отставания потребителя Apache Kafka...
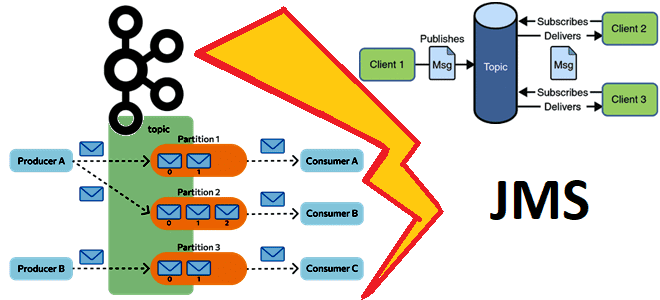
В этой статье для обучения дата-инженеров и разработчиков распределенных систем сравним Apache Kafka с популярными реализациями Java-стандартов обмена сообщениями, к которым относится Apache ActiveMQ, IBM MQ, Rabbit MQ и другие JMS-брокеры. Чем распределенная платформа потоковой передачи событий отличается от JMS-брокеров и что между ними общего. Что такое JMS-брокер Прежде чем...

Недавно мы сравнивали разные форматы сериализации данных, поддерживаемые Apache Kafka. Однако, AVRO и JSON не могут похвастаться таким высоким коэффициентом сжатия, как колоночный бинарный формат Parquet. Читайте далее, как хранить больше потоковых данных на тех же ресурсах с помощью движка Deephaven и других open-source решений. Apache Kafka и Parquet Apache...

Хотя распределенные системы с микросервисной архитектурой дают множество преимуществ, процесс их проектирования достаточно сложен. В частности, нужно учитывать возможность возникновения неопределенности параллелизма или состояния гонки, и заранее предусмотреть способы решения этих проблем. Одним из них является Apache Kafka, которая гарантирует упорядоченность событий. Рассмотрим на практическом примере, как это работает. Что...
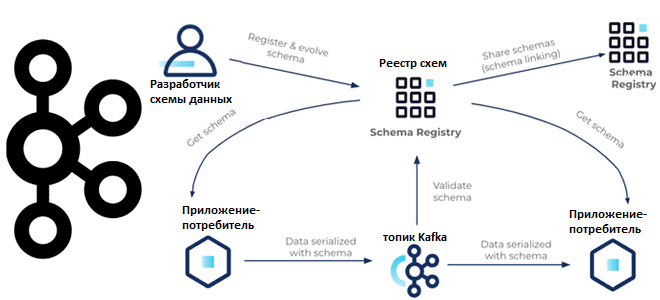
С какими проблемами качества данных сталкивается дата-инженер при работе с Apache Kafka и как реестр схем поможет их решить. Чем формат сериализации Apache AVRO отличается от JSON и Protobuf, как использовать Schema Registry и обеспечить совместимость данных: краткое пошаговое руководство для дата-инженера. Качество данных и реестр схем Apache Kafka Низкое...

В этой статье для обучения дата-инженеров и архитекторов распределенных систем рассмотрим, что такое наблюдаемость, как ее измерить и при чем здесь стандарт OpenTelemetry. А в качестве примера разберем, как французский маркетплейс Cdiscount управляет почти 1000 микросервисов в кластере Kubernetes с Apache Kafka, Jaeger, Elasticsearch и OpenTelemetry. Наблюдаемость распределенной системы: стандарт...

Сегодня рассмотрим пример программы лояльности турецкого интернет-магазина Trendyol, где Apache Kafka и документо-ориентированная NoSQL-СУБД Couchbase используются для генерации купонов на скидки. Почему при большом объеме данных случаются проблемы тайм-аутов в Couchbase, как их решить и при чем здесь коннекторы к Apache Kafka. Архитектура системы управления купонами Trendyol – это популярный...
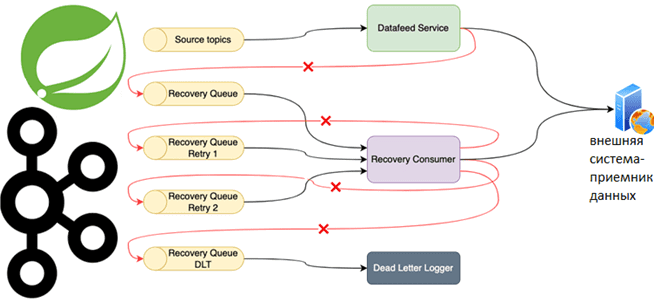
Специально для обучения разработчиков распределенных приложений и дата-инженеров, рассмотрим практический пример использования возможностей фреймворка Spring для управления повторными попытками отправки сообщений потребителям из топика Apache Kafka. Повторные попытки отправки сообщений и Spring для Apache Kafka Довольно часто Kafka-приложения требуют высокой надежности обработки сообщений. Например, в финтех- или медтех-проектах, а также...

В свежем релизе Apache Kafka 3.2.0, который вышел 17 мая 2022 года, о чем мы писали здесь, есть много интересных улучшений для повышения устойчивости потоковых приложений. Почему важна новая фича назначения резервных задач с учетом стоек и как разработчик с дата-инженером могут использовать в помощь администратору кластера: разбор rack awareness...

17 мая 2022 года вышел очередной релиз главной платформы потоковой передачи событий. Смотрим самые важные обновления свежей Apache Kafka 3.2.0 с точки зрения разработчика распределенных приложений, дата-инженера и администратора кластера. ТОП-5 новинок свежей версии Apache Kafka для администратора кластера Apache Kafka 3.2.0 включает 2 новые фичи, 36 улучшений и 65...

Сегодня рассмотрим, кому и зачем нужно связывать Apache Hive с Kafka, каким образом реализуется эта интеграция, как получить доступ к данным из платформы потоковой передачи событий средствами SQL-on-Hadoop, при чем здесь режимы Kerberos и механизмы безопасности Ranger. Зачем нужна интеграция Apache Hive с Kafka Необходимость связать Apache Hive с Kafka...
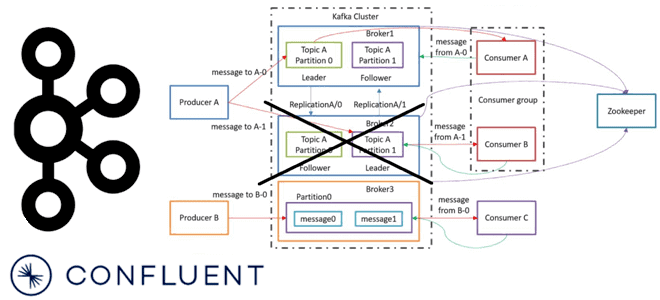
Сегодня рассмотрим важную для обучения администраторов кластера Apache Kafka тему про удаление брокеров. Что происходит, когда администратор удаляет брокер Kafka из кластера, какие сложности при этом могут возникнуть и как с ними справляется решение на базе платформы Confluent. Как вручную удалить брокер Kafka из кластера: краткий guide администратора На первый...

В этой статье для дата-инженеров рассмотрим пример конвейера анализа потокового видео с Youtube-каналов на Kafka, Spark Streaming и Elasticsearch c Kibana, связанных через процессоры Apache NiFi. Постановка задачи: ETL-конвейер анализа потоковых данных с Youtube Потоковые данные непрерывно генерируются тысячами источников, которые отправляют записи одновременно и в небольших размерах (порядка килобайт)....

Проблема своевременного пополнения товарных запасов актуальна для любого ритейлера. Разбираемся, как торговый гигант США Walmart построил свою платформу планирования и пополнения продукции в реальном времени на базе Apache Kafka: ключевые требования к системе, архитектура и принципы работы, настройка конфигураций продюсеров и потребителей. Постановка задачи: пополнение товарного запаса в реальном времени...
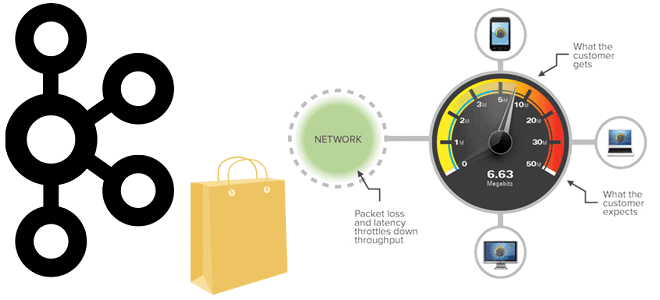
Пропускная способность информационной системы на базе Apache Kafka говорит о том, сколько данных могут быть обработаны за определенный период времени. Несмотря на потоковую передачу событий, здесь работает классический закон обратной зависимости скорости обработки данных от их объема. Разбираемся, как найти баланс между производительностью и задержкой. Еще раз о пропускной способности...

Пример выявления финансового мошенничества при скимминге банковских карт в банкоматах с помощью технологий Big Data. Как Apache Kafka, Flink и HBase помогут обнаружить злоумышленников в режиме реального времени. Что такое скимминг, как это работает и чем опасно Скимминг является одним из частых видов мошенничества с банковскими картами, представляющий собой считывание...
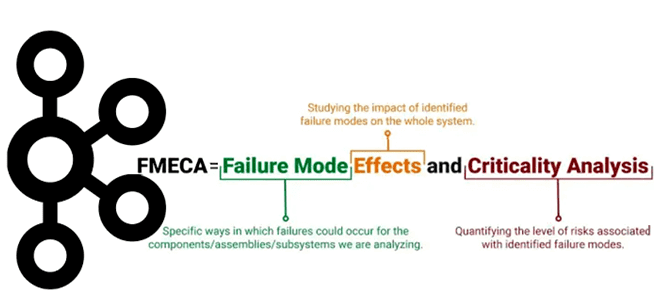
Хотя Apache Kafka является надежной платформой потоковой обработки событий, что особенно важно для распределенных приложений, отказы случаются и в ней. Сегодня разберем важную для обучения разработчиков и дата-инженеров тему про идентификацию и обработку отказов в Kafka-приложениях с помощью простого, но эффективного метода теории надежности. Что такое FMECA-анализ, как его проводить...