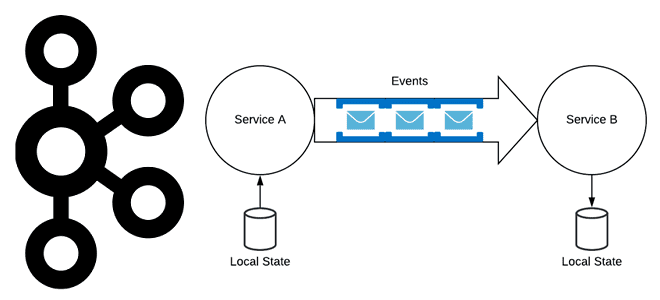
Хотя Apache Kafka часто используется в качестве шины обмена данными в микросервисной архитектуре, о чем мы писали здесь, не стоит воспринимать эту платформу как хранилище событий. В чем разница между событием и сообщением, а также другие тонкости построения микросервисной архитектуры, управляемой событиями. События vs сообщения Событие — это сообщение программной...

Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии. Почему не стоит использовать СУБД вместо очереди сообщений Dagster Cloud...
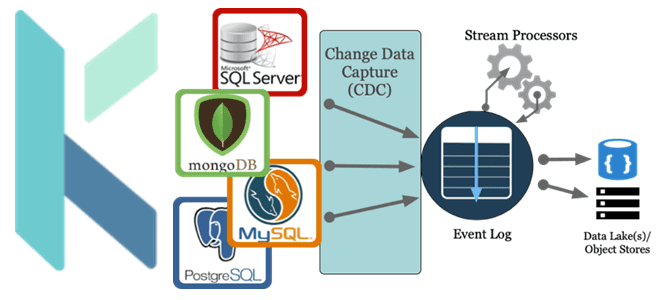
Как реализовать CDC-сценарий, используя платформу оркестрации Kestra вместо Debezium с Kafka Connect для планирования и управления конвейером обработки данных. За счет чего Kestra работает эффективнее Debezium с коннекторами Kafka Connect и при чем здесь Apache AirFlow с NiFi. Что не так с реализацией CDC на Debezium с Kafka Connect Мы...
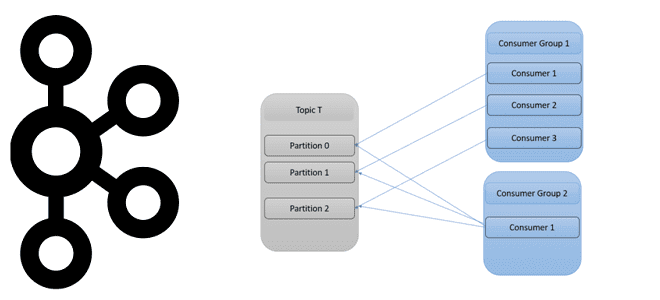
Как количество разделов топика Apache Kafka влияет на потребителей и продюсеров, зачем нужны группы потребителей и как этот механизм реализует идею микросервисной архитектуры Big Data систем. Как работают группы потребителей в Apache Kafka Будучи распределенной платформой потоковой передачи событий, Apache Kafka выполняет роль средства обмена сообщениями между приложениями-продюсерами и приложениями-потребителями...
Как использовать мощь Apache Kafka в ИТ-архитектуре корпоративных приложений и интеграции информационных систем: краткий ликбез по ключевым принципам работы этой платформы потоковой передачи событий и важность дата-контрактов для инженера данных, разработчика и архитектора. 9 лучших практик использования Apache Kafka в архитектуре приложений Чтобы успешно применять Apache Kafka в качестве основной...
Чтобы сделать наши курсы по Apache Kafka еще более полезными, сегодня рассмотрим, какие интерфейсы и протоколы для связи клиента с брокером использует эта платформа потоковой передачи событий. А также рассмотрим, что обеспечивает двунаправленную совместимость API. Протоколы и интерфейсы Apache Kafka для общения клиентов с брокерами Apache Kafka использует бинарный протокол...

В этой статье для обучения ИТ-архитекторов и дата-инженеров сравним 2 подхода к аналитике больших данных, чтобы решить, когда потоковые вычисления, например, средствами ksqlDB в рамках Apache Kafka лучше аналитических баз данных реального времени, таких как Rockset, и наоборот. 2 способа выполнения аналитики больших данных в реальном времени Современный бизнес и...

Сегодня заглянем под капот Apache Kafka и рассмотрим, как на программном уровне работает упаковка сообщений от приложения-продюсера в пакеты перед их отправкой в топик платформы. Что такое RecordAccumulator, какие конфигурации с ним связаны и почему такое пакетирование обеспечивает эффективность потоковой обработки данных. Как устроено пакетирование потоковой обработки в Apache Kafka...
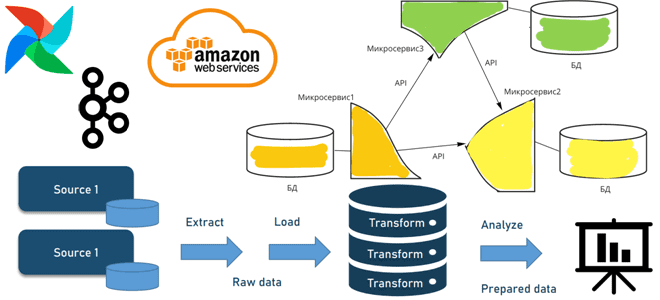
Когда и зачем переходить от пакетной парадигмы обработки к потоковой, как это сделать с помощью микросервисной архитектуры, какие проблемы могут при этом возникнуть и что за решения позволят их избежать. А в качестве примеров инструментальных средств рассмотрим сервисы AWS, Apache AirFlow и Kafka. От пакетов к потокам через микросервисы: архитектура...

Визуализация конвейеров обработки данных особенно важна в потоковой парадигме, поэтому мы часто рассматриваем полезные средства мониторинга для Apache Kafka. Сегодня разберем, что такое Streams Explorer от Bakdata и как это пригодится для дата-инженера. Проекты Bakdata для развертывания и мониторинга приложений Kafka Streams При работе с крупномасштабными потоковыми данными крайне важно...

В этой статье для обучения дата-инженеров и администраторов кластера Apache Kafka разберем, какие ошибки создают медленные потребители и как решить их, просто изменив значений конфигураций по умолчанию. А также познакомимся с Lighthouse - еще одним полезным инструментом мониторинга системных метрик, который позволит обнаружить эти и другие проблемы. Проблема медленных потребителей...
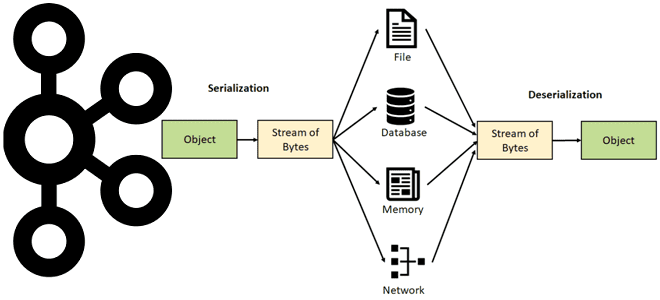
Недавно мы писали про сериализацию и десериализацию данных в Apache Kafka. Продолжая эту важную для обучения дата-инженеров и разработчиков распределенных приложений тему, рассмотрим особенности преобразования и валидации сообщений в JSON-формате, а также поговорим про автоматическую идентификацию формата сообщения. Сериализация и десериализация данных в Apache Kafka Выполняя роль интеграционной платформы, Apache...
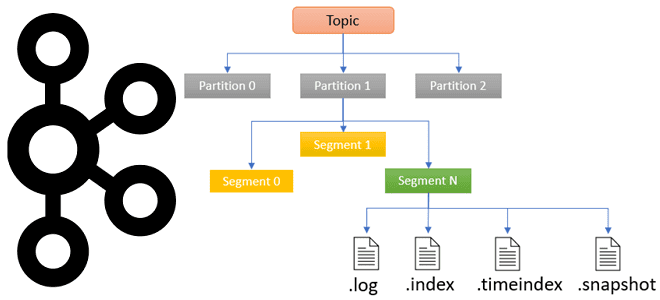
Чтобы сделать наши практические курсы по Apache Kafka еще более полезными, сегодня рассмотрим, в каких файлах хранятся сообщения, смещения и состояния продюсера, а также функции работы с ними для потоковой передачи событий. Средства обработки и хранения данных в Apache Kafka Прежде, чем погружаться в тонкости хранения данных в Apache Kafka,...

Сегодня рассмотрим, как дата-инженеры маркетплейса Whatnot масштабировали потоковую обработку данных с помощью Apache Kafka, изменив свои ETL-процессы и реализовав на этой распределенной платформе шину событий для анализа пользовательского поведения c ksqlDB и Rockset. Постановка задачи: события пользовательского поведения в Whatnot Whatnot – это маркетплейс, пользователи которого могут покупать и продавать...

Как турецкая e-commerce компания Trendyol повысила эффективность пакетных вычислений, используя распределенную платформу потоковой обработки событий Apache Kafka вместе с серверной утилитой сбора и фильтрации данных из разных источников Logstash. Пакетная обработка данных и конвейер на Logstash Хотя сегодня все больше организаций переходят на потоковую обработку событий в реальном времени, пакетная...

Чтобы добавить в наши курсы для администраторов кластера Apache Kafka и разработчиков распределенных приложений еще больше полезных обучающих материалов, сегодня рассмотрим новый инструмент мониторинга системных метрик этой платформы потоковой передачи событий. Что такое проект Iris и чем он отличается от других популярных средств мониторинга состояния Apache Kafka, о которых мы...
Мы уже писали о Python-клиентах Apache Kafka, которые позволяют разрабатывать приложения потоковой передачи события, используя популярный Python вместо сложных языков Java и Scala. Сегодня познакомимся с еще одной Python-библиотекой, которая представляет асинхронный клиент для Kafka. Что такое aiokafka и чем это отличается от kafka-python: краткий обзор для обучения инженеров данных...

В связи с активным переходом от локальной ИТ-инфраструктуры в облачные полностью управляемые сервисы многие ИТ-архитекторы и дата-инженеры задумываются о замене собственного кластера Apache Kafka ее Cloud-альтернативами. Читайте, что общего у Apache Kafka с AWS Kinesis, чем они отличаются и какую платформу выбрать для потоковой передачи событий. Потоковая обработка событий с...
Сегодня заглянем под капот ИТ-инфраструктуры самой знаменитой франшизы быстрого питания. Как устроена унифицированная платформа потоковой обработки событий в McDonald’s на базе облачного полностью управляемого сервиса Apache Kafka в AWS и что гарантирует высокую доступность и надежность решения. Архитектурный дизайн Архитектуры, основанные на событиях, обеспечивают гибкость интеграции, масштабируемость и некоторые возможности...

Сегодня рассмотрим пример построения гибридной архитектуры LakeHouse c Apache Kafka и Snowflake, которая гарантирует высокую масштабируемость и обеспечивает безопасность данных от несанкционированного доступа с помощью маскирования. От пакетного озера данных на AWS S3 к потоковому LakeHouse Будучи высоконадежной распределенной платформой потоковой передачи событий, Apache Kafka часто используется для обработки потока...