Сегодня я на практическом примере покажу тонкости настройки конфигураций JDBC-коннектора источника, передающий новые записи из таблицы PostgreSQL в топик Apache Kafka. Настройка JDBC-коннектора и отправка в Kafka Connect Как я упоминала вчера, помимо CDC-коннектор Debezium, передать данные из реляционной базы данных PostgreSQL в Apache Kafka, также есть JDBC-коннектор от Confluent:...

Что общего между Kafka Connect JDBC Source и PostgreSQL CDC Source V2 (Debezium), чем отличаются эти коннекторы и как добавить JDBC-драйвер для передачи данных из PostgreSQL в Apache Kafka на Docker. Коннекторы Kafka к реляционным БД от Confluent О том, что CDC-коннектор Debezium позволяет организовать интеграцию Apache Kafka с реляционной...

6 ноября 2024 года опубликован очередной выпуск самой популярной платформы потоковой передачи событий. Что нового в Apache Kafka 3.9: динамические кворумы KRaft, улучшения многоуровневого хранилища, полезные фичи Kafka Streams и Kafka Connect. Динамические кворумы KRaft Релиз Apache Kafka 3.9 официально назван последним, который использует ZooKeeper в качестве службы синхронизации метаданных....

Какие задачи решают инженеры и администраторы кластера для организации многопользовательского доступа к платформе потоковой передачи событий, а также чем полезен фреймворк Strimzi для развертывания и сопровождения мультиарендной среды Apache Kafka на Kubernetes. Задачи управления мультипользовательским кластером Kafka Выступая в качестве средства интеграции информационных систем и микросервисов, в корпоративной среде Apache...
Чтобы сделать конвейеры обработки данных еще более эффективными, устраняя промежуточные хранилища для потоковых вычислений и сократить количество ETL-инструментов, немецкая компания Ververica разработала Fluss – потоковое хранилище для Apache Flink. Читайте далее, что это и чем полезно в непрерывной обработке потоков Big Data. Что не так с архитектурой конвейеров обработки данных...
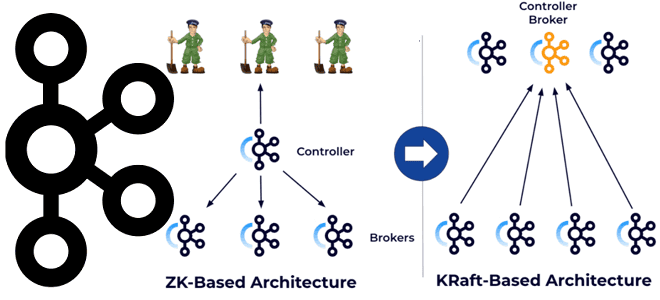
Как перевести кластер Kafka с ZooKeeper на KRaft, чтобы обеспечить управление метаданными с помощью этого протокола консенсуса: последовательность действий и настройки конфигураций. Зачем и как переводить Apache Kafka с Zookeeper на KRaft Напомним, протокол KRaft, который заменяет ZooKeeper для управления метаданными и консенсуса кластера Kafka, был введен еще в версии...
Как публиковать в топик Kafka сообщения в формате Protobuf, используя реестр схем и библиотеку confluent-kafka. Пример Python-продюсера, конфигурационного YAML-файла для Docker-развертывания Kafka Confluent и тунелирование портов локального компьютера. Подготовка инфраструктуры и определение схемы данных Чтобы публиковать в свое Docker-развертывание Kafka Confluent данные, используя реестр схем, нужно сперва внести изменения в...
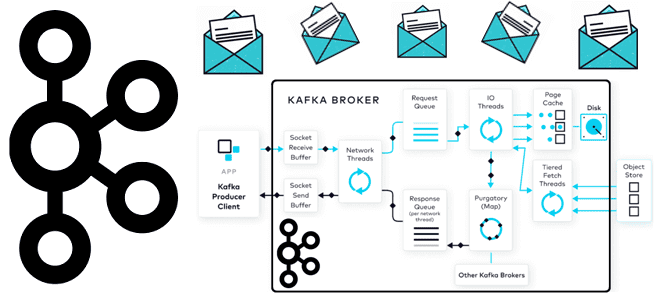
Как данные попадают в топик Kafka: полный путь пакета сообщений от буфера сокета приема до страничного кэша и отправки ответного подтверждения клиенту- продюсеру. Все шаги публикации данных в Apache Kafka Когда разработчик пишет код приложения-продюсера, публикующего данные в Apache Kafka, он использует существующие методы для отправки сообщений, которые есть в...
Аналитика данных из топиков Kafka с помощью SQL-запросов: обращение к ksqlDB в Docker через CLI-интерфейс и REST API в Postman с SSH-тунелированием сервера потоковой базы данных. Практическое руководство с примерами и иллюстрациями. CLI-интерфейс ksqldb Docker-образ Confluent Kafka включает дополнительные компоненты этой платформы: ksqlDB, Kafka Connect, REST Proxy, Schema Registry). Сегодня...
Как туннелировать порты Docker-контейнеров для доступа к Kafka на WSL в Windows с внешнего клиента: переадресация HTTP- и TCP-соединений с помощью SSH-сервера serveo. Поиск средства тунелирования и настройка портов Собственное развертывание платформы Kafka от Confluent в виде набора связанных Docker-контейнеров в WSL на Windows с GUI-интерфейсом AKHQ, о чем я...
Как настроить YAML-файл Docker Compose для доступа к Kafka на WSL в Windows: открытие портов в конфигурации развертывания с примерами (продолжение). Настройка конфигурационного YAML-файла для запуска Docker-контейнеров с компонентами Kafka на Windows в WSL Как я рассказывала вчера, для работы с компонентами платформы Kafka от Confluent, развернутой как набор связанных...

WSL и Docker для локального развертывания Apache Kafka с GUI и всеми компонентами в контейнере: моя реальная история поиска веб-интерфейса и настройки портов (начало). Развертывание Kafka на Windows с Docker в WSL В конце августа 2024 года команда serverless-платформы Upstash, на которой у меня есть рабочий инстанс Apache Kafka, разослала...
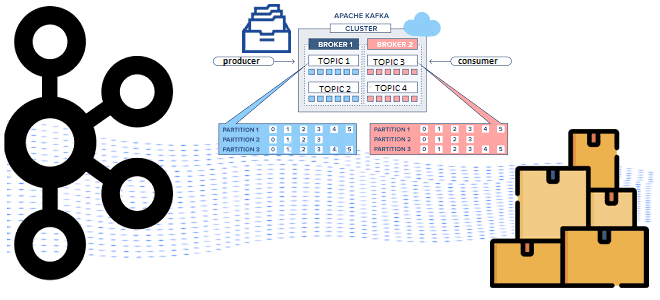
Какие конфигурации настроить на продюсере для эффективной публикации сообщений в Apache Kafka: упаковка записей в пакеты, взаимодействие с брокерами и метрики мониторинга этих процессов. Пакетирование сообщений при их публикации в Kafka и мониторинг этого процесса Хотя Apache Kafka поддерживает потоковую парадигму обработки информации, она активно использует пакетные технологии. В частности,...

Зачем хранить данные в Apache Kafka постоянно и как это сделать: варианты использования и пример архитектурного решения Infinite Storage от Confluent Cloud, который лег в основу Tiered Storage. Infinite Storage от Confluent Cloud для бесконечного хранения данных в Apache Kafka Изначально Apache Kafka, как и любой другой брокер сообщений, не...

Как расширить возможности ksqlDB, реализовав пользовательскую функцию обработки данных, хранящихся в топиках Kafka, с помощью SQL-запросов: ликбез по UDF и практический пример. Пользовательские функции в ksqlDB для работы с данными в топиках Apache Kafka Поскольку Apache Kafka – то не просто брокер сообщений, а целая экосистема потоковой передачи событий, вокруг...

29 июля 2024 года вышло очередное обновление Apache Kafka. Разбираемся с главными новинками релизе 3.8: поддержка JBOD в многоуровневом хранилище, детальная настройка уровня сжатия, улучшение безопасности и удаление неоднозначных конфигураций. ТОП-7 новинок Apache Kafka 3.8 Многоуровневое хранилище (Tiered Storage) для надежного долговременного хранения данных, опубликованных в Kafka, без ущерба высокой...
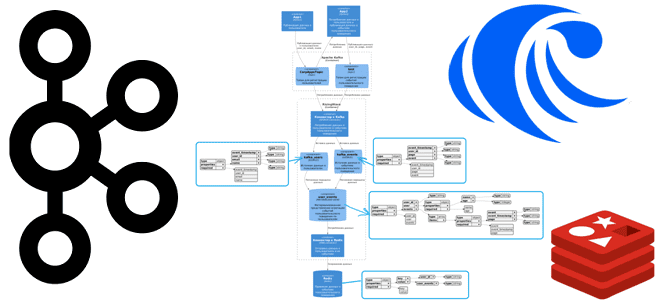
Как SQL-запросами соединить потоки из разных топиков Apache Kafka и отправить результаты в Redis: демонстрация ETL-конвейера на материализованных представлениях в RisingWave. Постановка задачи и проектирование потоковой системы Продолжая недавний пример потоковой агрегации данных из разных топиков Kafka с помощью SQL-запросов, сегодня расширим потоковый конвейер в RisingWave, добавив приемник данных –...
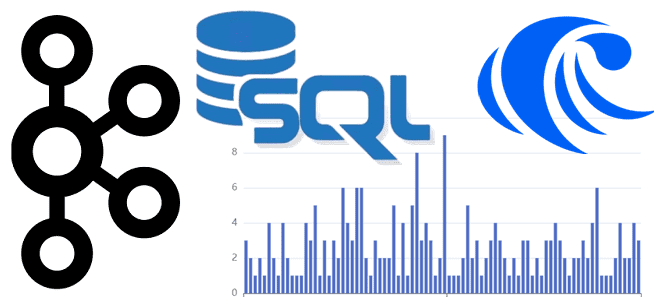
Как соединить данные из разных топиков Apache Kafka с помощью пары SQL-запросов: коннекторы, материализованные представления и потоковая база данных вместо полноценного потребителя. Подробная демонстрация запросов в RisingWave. Проектирование и реализация потоковой агрегации данных из Kafka в RisingWave Вчера я показывала пример потоковой агрегации данных из разных топиков Kafka с помощью...
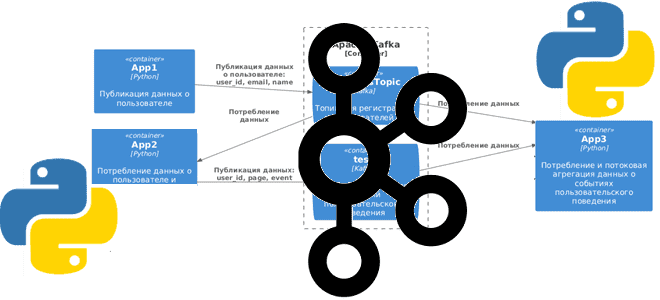
Сегодня я покажу простую демонстрацию потоковой агрегации данных из разных топиков Apache Kafka на примере Python-приложений для соединения событий пользовательского поведения с информацией о самом пользователе. Постановка задачи Рассмотрим примере кликстрима, т.е. потокового поступления данных о событиях пользовательского поведения на страницах сайта. Предположим, данные о самом пользователе: его идентификаторе, электронном...
Почему производительность confluent-kafka выше, чем у kafka-python, чем еще отличаются эти Python-библиотеки для разработки клиентов Apache Kafka, и что выбирать. Сравнение Python-библиотек для разработки клиентов Kafka Хотя Java считается более подходящей для создания высоконагруженных приложений, многие разработчики используют Python, который намного проще. Этот язык программирования подходит даже для написания продюсеров...