
Мы уже рассказывали про интеграцию Tarantool с Apache Kafka на примере Arenadata Grid. Сегодня рассмотрим, как интегрировать Кафка с MPP-СУБД Greenplum и каковы ограничения каждого из существующих способов. Читайте в сегодняшнем материале, что такое GPSS, PXF и при чем тут Docker-контейнер с коннектором Кафка для Arenadata DB. IoT и не...
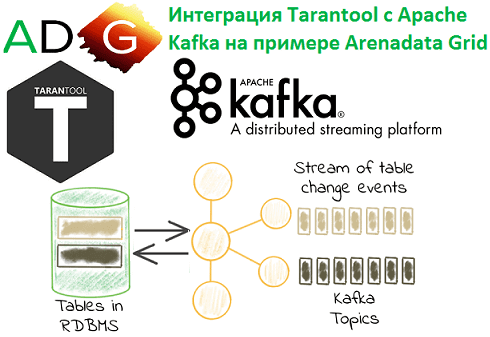
Продолжая разбираться с In-Memory СУБД Tarantool и Arenadata Grid, сегодня рассмотрим, как эти резидентные базы данных интегрируются с Apache Kafka. Читайте в нашей статье, что такое коннекторы и процессоры, а также как записать в топик Кафка сообщение, SQL-запрос или часть таблицы. Arenadata Grid и Apache Kafka: коннектор + процессоры Напомним,...
Вчера мы затрагивали тему управления поставками в ритейле с помощью технологий Big Data и Machine Learning. Теперь разберем подробнее, как большие данные, машинное обучение и интернет вещей меняют складскую логистику и насколько это выгодно бизнесу. Сегодня мы собрали для вас 7 практических примеров: кейсы от отечественных и зарубежных транспортных компаний,...

В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном...
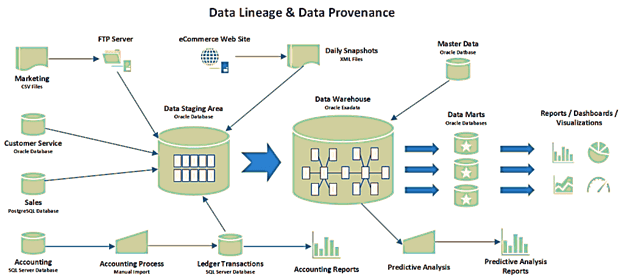
В этой статье мы продолжим разговор про основы управления данными и рассмотрим, что такое data provenance и data lineage, чем похожи и чем отличаются эти понятия. Также разберем, почему эти термины особенно важны для Big Data, какие инструменты помогают работать с ними, а также при чем здесь GDPR. Что такое...
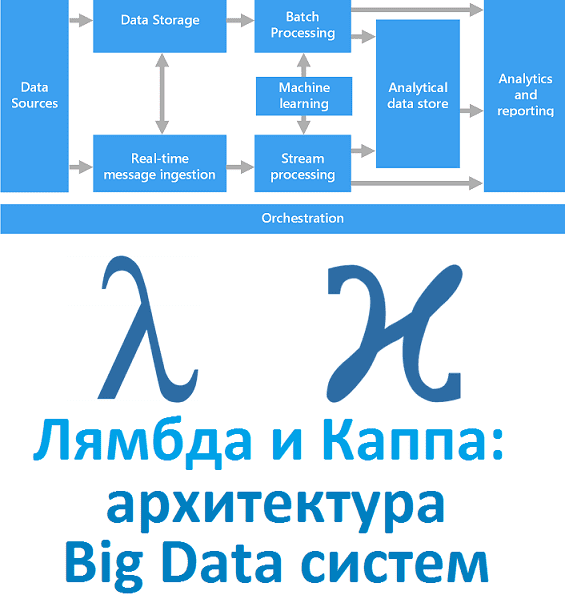
Вчера мы рассказали, что такое лямбда-архитектура. Сегодня рассмотрим Каппа - альтернативный подход к проектированию Big Data систем. Читайте в нашей статье, зачем нужна эта концепция, каковы ее достоинства и недостатки, чем Каппа отличается от Лямбда, где это используется на практике и при чем тут Apache Kafka с Machine Learning. Зачем...
Не претендуя на лавры Мэри и Тома Поппендиков, которые впервые освятили применение Lean в разработке ПО, сегодня мы расскажем, как идеи бережливого производства реализуются в области Big Data. Читайте в нашей статье про принцип вытягивания в Apache Kafka, концепцию «точно вовремя» в Apache Spark, SMED в Kubernetes и облачных кластерах...

Выбирая курсы по Spark, Hadoop, Kafka и другим технологиям больших данных, легко запутаться во многочисленных предложениях от различных учебных центров и платформах онлайн-обучения. Сегодня мы расскажем, что должна включать программа курса по Big Data, чтобы результат обучения оправдал ваши ожидания и даже превзошел их. 4 главных свойства эффективного курса по...

Однажды мы уже рассматривали, зачем Apache Kafka, Hadoop, HBase и другие Big Data системы используют Zookeeper, почему он необходим в распределенных проектах и чем можно заменить его заменить. Сегодня поговорим о том, как работает этот популярный централизованный сервис для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления...

Рассматривать обучение Кафка интереснее на практических примерах. Сегодня мы расскажем, как Apache Kafka применяется в одной из крупнейших промышленных компаний России - ПАО «Северсталь». Эта статья написана на основе выступления Доната Фетисова, главного архитектора «Северсталь Диджитал». Доклад был представлен 7 декабря 2019 года на очередном ИТ-митапе компании Авито по Big...

Вчера мы рассказывали, от чего зависит скорость работы Apache Kafka и как можно повысить. Сегодня рассмотрим подробнее, как именно конфигурация отправителей (производителей, producers) сообщений влияет на общую производительность этой распределенной Big Data системы потоковой агрегации событий. Что такое конфигурация производителей Apache Kafka Напомним, общая производительность Кафка зависит от следующих факторов:...

Продолжая практическое обучение Kafka, сейчас мы рассмотрим, от чего зависит производительность этой распределенной Big Data системы потоковой агрегации событий. Частично эту тему мы уже рассматривали в статье про применение Кафка в высоконагруженных проектах. Читайте в сегодняшнем материале, какие параметры влияют на скорость работы Кафка и как можно ее повысить. Как...
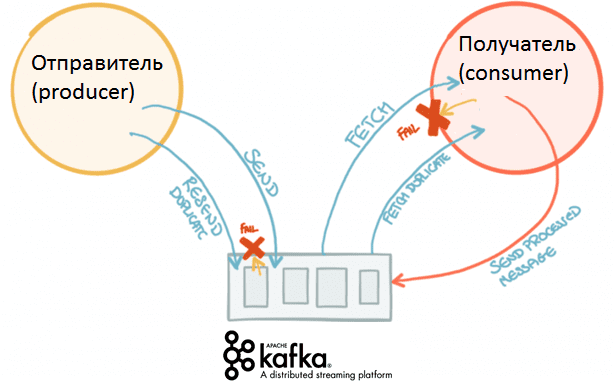
Вчера мы говорили про концепцию QaaS, очереди сообщений в Apache Kafka и другие проблемы производительности высоконагруженных систем с использованием этой Big Data платформы. Сегодня рассмотрим сложности многопоточной обработки событий в разном порядке: когда возникают подобные ситуации и как их решить. Для этого еще раз сравним Кафку с ее вечным конкурентом,...

При всех достоинствах Apache Kafka, для этого популярного Big Data средства управления сообщениями характерны определенные трудности в обеспечении производительности. Сегодня мы поговорим про некоторые проблемы использования этого распределенного брокера сообщений в высоконагруженных системах. В качестве реального примера рассмотрим особенности практического использования Кафка в отечественном сервисе объявлений Авито. Что такое высоконагруженная...
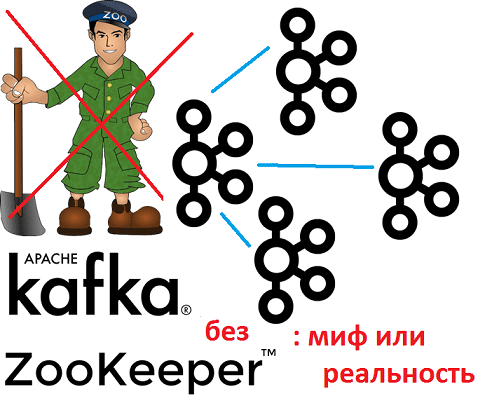
Рассматривая практическое обучение Kafka, сегодня мы поговорим, зачем нужен Zookeeper и можно ли использовать Кафка без этой централизованной службы синхронизации распределенных сервисов. Читайте в нашей статье о роли Zoo в системах обработки больших данных (Big Data) и о том, может ли Apache Kafka эффективно работать без Zookeeper, а также как...

Продолжая разговор о том, как выбрать курсы по Kafka и другим технологиям больших данных (Big Data), сегодня рассмотрим, кому и в каких случаях нужно такое повышение квалификации. В этой статье мы собрали для вас 5 прикладных кейсов по Кафка для ИТ-профессионалов разных специальностей, от системного администратора до Data Engineer’а. А...

В этой статье мы рассмотрим наиболее значимые факторы по выбору образовательных курсов по Apache Kafka и другим технологиям больших данных (Big Data). А также расскажем, как эти условия реализуются в нашем учебном центре, чтобы сделать повышение квалификации ИТ-специалистов и руководителей максимально эффективным. Что важно при выборе курсов по Кафка Проанализировав...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

Благодаря быстроте, надежности и другим достоинствам Apache Cassandra, эта распределенная NoSQL-СУБД широко применяется во многих Big Data проектах по всему миру. В этой статье мы собрали для вас несколько интересных примеров реального использования Кассандры в 5 ключевых направлениях современного ИТ. Где используется Apache Cassandra: 5 главных приложений c примерами Промышленные...

Завершая разговор про ETL-инструменты Big Data и цикл статей об Apache NiFi (ANF), сегодня мы сравним его со StreamSets Data Collector (SDC): чем похожи и чем отличаются эти системы маршрутизации данных. Также рассмотрим, в каких случаях следует выбирать ту или иную платформу и почему. Что общего между Apache NiFi и...