985
985 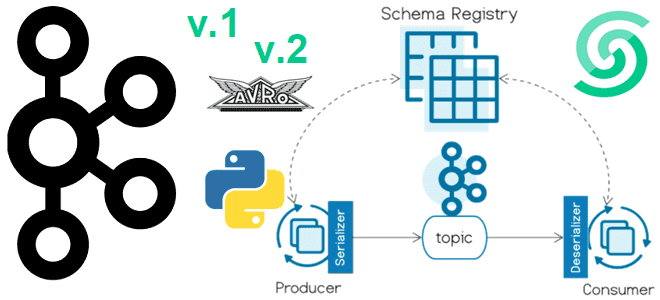
Содержание
Версионирование схемы сообщений в формате AVRO с использованием реестра схем Apache Kafka и библиотеки confluent_kafka: практический пример на Python в Google Colab.
Публикация сообщений в Kafka с использованием реестра схем
Недавно я показывала пример использования реестра схем (Schema Registry) Apache Kafka при публикации сообщений. Сегодня рассмотрим версионирование схемы данных в формате AVRO, а также потребление сообщений. Реестр схем – это модуль Confluent для Apache Kafka, который позволяет централизовано управлять схемами данных полезной нагрузки сообщений в топиках. Определив схемы данных для полезной нагрузки и зарегистрировав ее в реестре, ее можно использовать повторно, облегчая код приложения-потребитель. Это обеспечивается благодаря отсутствию необходимости проверять структуру и формат потребленных данных. Также реестр схем снижает накладные расходы на сетевую передачу, передавая идентификатор схемы полезной нагрузки сообщения вместо ее полного определения. Подробный разбор того, как это работает, читайте в новой статье.
Как обычно, мой экземпляр Kafka развернут в облачной платформе Upstash, которая в начале 2024 года включила поддержку реестра схем. Чтобы работать с ним для Python-клиентов необходимо использовать библиотеки kafka-schema-registry и confluent_kafka. Для публикации необходимо указать сериализатор, а для потребления сообщений – десериализатор, соответствующий формату. Для публикации сообщений используем сериализатор AvroSerializer для формата AVRO – линейно-ориентированный (строчный) формат хранения файлов, который сохраняет схему в независимом от реализации текстовом формате JSON. Соответственно, для потребления сообщений нужен десериализатор AvroDeserializer.
Установим эти библиотеки и импортируем модули:
#установка библиотек !pip install confluent_kafka !pip install kafka-schema-registry !pip install faker #импорт модулей import random from datetime import datetime import time from time import sleep from confluent_kafka import Producer from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField from confluent_kafka.schema_registry import SchemaRegistryClient from confluent_kafka.schema_registry.avro import AvroSerializer # Импорт модуля faker from faker import Faker
Предположим, каждый 3 секунды приложение-продюсер может опубликовать сообщение с данными об имени и email клиента, а также id и отметкой времени согласно следующей схеме:
{
"type": "record",
"name": "application",
"namespace": "com.upstash",
"fields": [
{
"name": "id",
"type": "long"
},
{
"name": "event_time",
"type": "string"
},
{
"name": "client",
"type": "string"
},
{
"name": "email",
"type": "string"
}
]
}
Или сообщение также может содержать сведения о номере телефона клиента и иметь другую схему данных:
{
"type": "record",
"name": "application",
"namespace": "com.upstash",
"fields": [
{
"name": "id",
"type": "long"
},
{
"name": "event_time",
"type": "string"
},
{
"name": "client",
"type": "string"
},
{
"name": "email",
"type": "string"
},
{
"name": "phone",
"type": "string"
}
]
}
Код Python-приложения продюсера будет таким:
# Определение схемы данных
schema=''
schema_1 = """{
"type": "record",
"name": "application",
"namespace": "com.upstash",
"fields": [
{"name": "id", "type": "long"},
{"name": "event_time", "type": "string"},
{"name": "client", "type": "string"},
{"name": "email", "type": "string"}
]
}
"""
schema_2 = """{
"type": "record",
"name": "application",
"namespace": "com.upstash",
"fields": [
{"name": "id", "type": "long"},
{"name": "event_time", "type": "string"},
{"name": "client", "type": "string"},
{"name": "email", "type": "string"},
{"name": "phone", "type": "string"}
]
}
"""
topic='test'
fake=Faker('ru_RU')
#Создание продюсера
producer = Producer({
'bootstrap.servers': kafka_url,
'sasl.mechanism': 'SCRAM-SHA-256',
'security.protocol': 'SASL_SSL',
'sasl.username': username,
'sasl.password': password,
})
schema_registry_client = SchemaRegistryClient({
'url': schemaregistry_url,
'basic.auth.user.info': auths
})
string_serializer = StringSerializer('utf_8')
id=0
# Бесконечный цикл публикации данных.
while True:
schema=random.choice([schema_1, schema_2])
avro_serializer = AvroSerializer(schema_registry_client, schema)
start_time = time.time()
id=id+1
producer_publish_time = time.strftime("%m/%d/%Y %H:%M:%S", time.localtime(start_time))
if schema==schema_1:
application = {"id":id, "event_time":producer_publish_time, "client": fake.name(), "email": fake.free_email()}
else:
application = {"id":id, "event_time":producer_publish_time, "client": fake.name(), "email": fake.free_email(), "phone": fake.phone_number()}
value = avro_serializer(application, SerializationContext(topic, MessageField.VALUE))
future = producer.produce(topic=topic, value=value)
print("Message sent successfully")
print(f' [x] Payload {application }')
# Повтор через 3 секунды.
time.sleep(3)
После запуска этого скрипта в Google Colab в реестре схем Kafka создается соответствующая схема значения, т.е. полезной нагрузки сообщения. Поскольку приложение-продюсер публикует данные с разными версиями схемы, в самом реестре схем сгенерируется новая версия схемы, что отобразится в GUI платформы Upstash. Чтобы потребители, использующие все ранее зарегистрированные схемы, могут читать данные, опубликованные продюсерами с использованием новой схемы, я изменила тип совместимости схемы на FORWARD_TRANSITIVE. Подробнее про типы совместимости схем данных читайте в прошлой статье.
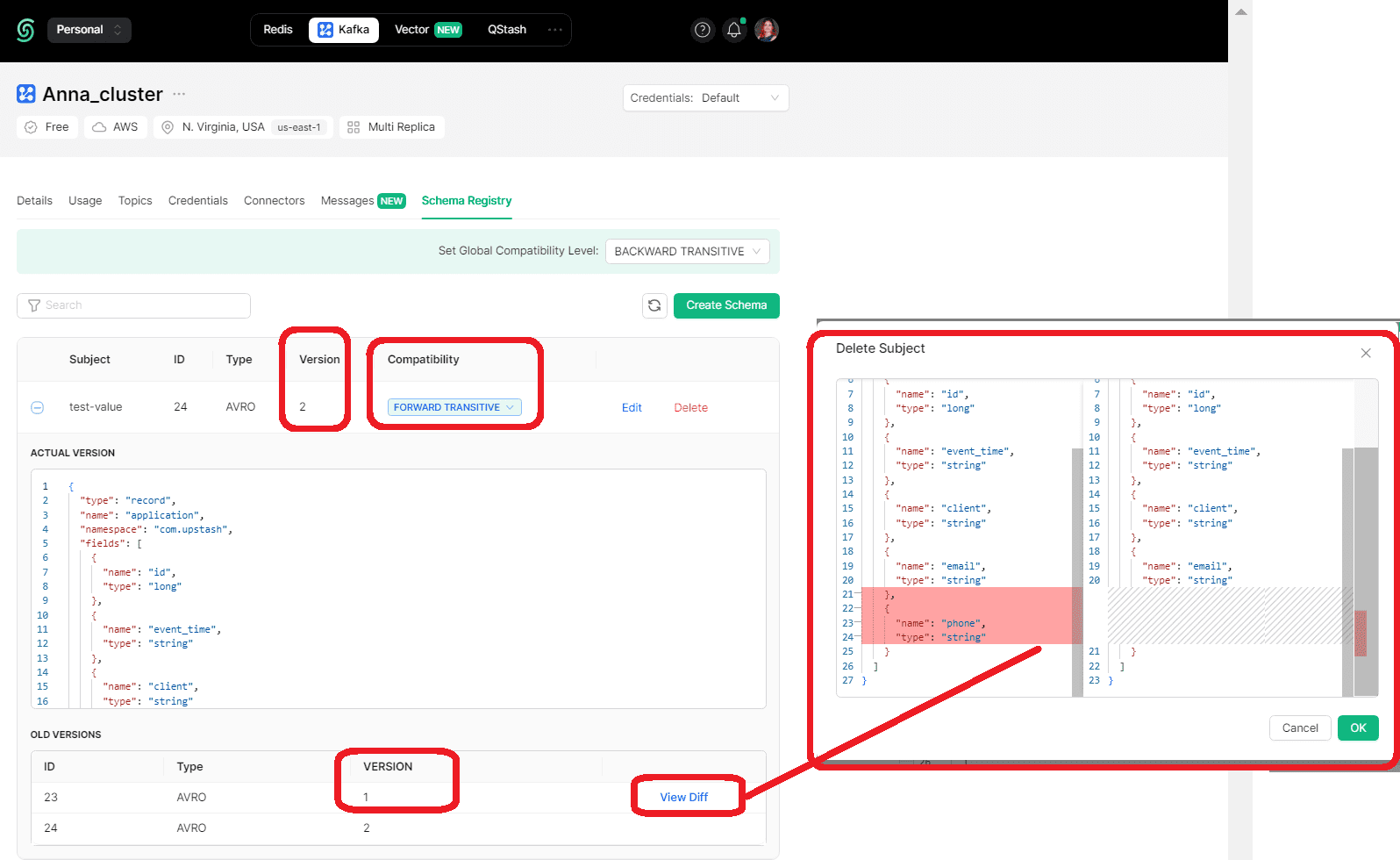
Теперь посмотрим, как работает потребитель сообщений с использованием реестра схемы.
Потребление сообщений из топика Kafka с реестром схем
Чтобы понять, как работают вышеперечисленные пакеты, рассмотрим простой пример потребления AVRO-сообщений из Kafka, их парсинг и запись в столбцы Google-таблицы. Сперва необходимо установить библиотеки и импортировать модули. В интерактивной среде Google Colab это будет выглядеть так:
#Установка библиотек и импорт модулей !pip install confluent_kafka !pip install kafka-schema-registry from confluent_kafka import Consumer from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField from confluent_kafka.schema_registry import SchemaRegistryClient from confluent_kafka.schema_registry.avro import AvroDeserializer #импорт модулей import json from google.colab import auth auth.authenticate_user() import gspread from google.auth import default creds, _ = default()
Далее следует настроить десериализатор:
#потребление AVRO с реестром схем
avro_deserializer = AvroDeserializer(SchemaRegistryClient(
{
'url': schemaregistry_url,
'basic.auth.user.info': auth_info
}))
Затем надо объявить потребитель Kafka и подписать его на топик:
#объявление потребителя Kafka
consumer = Consumer({
'bootstrap.servers': kafka_url,
'sasl.mechanism': 'SCRAM-SHA-256',
'security.protocol': 'SASL_SSL',
'sasl.username': username,
'sasl.password': password,
'group.id': 'gr_3',
'auto.offset.reset': 'latest'
})
topic='test'
consumer.subscribe([topic])
Определим таблицу и лист Google Sheets для записи потребленных данных:
#Google Sheets Autentificate
gc = gspread.authorize(creds)
#Открытие заранее созданного файла Гугл-таблицы по идентификатору
sh = gc.open_by_key(идентификатор гугл-таблицы')
wks = sh.worksheet("test") #в какой лист гугл-таблиц будем записывать
#начальный номер строки для записи данных
x=1
Наконец, запускаем бесконечный цикл потребления данных:
try:
while True:
message = consumer.poll(1.0)
if message is None:
continue
if message.error():
print(message.error())
continue
# Создание контекста десериализации
context = SerializationContext(message.topic(), MessageField.VALUE)
try:
# Десериализация сообщения
deserialized_value = avro_deserializer(message.value(), context)
if deserialized_value is not None:
print(f"Key: {message.key()}, Value: {deserialized_value} \n")
# Парсинг сообщения
fields = list(deserialized_value.keys()) # Получение ключей из словаря и преобразование их в список
# обновление данных в Google Sheets
x += 1
a=0
for i in range(len(fields)): #range() для создания итерируемого диапазона индексов
a=i+1
value = deserialized_value[str(fields[i])] #использование квадратных скобок для доступа к значениям словаря
wks.update_cell(x, a, value)
except Exception as e:
# логика обработки ошибок
print(f"Error: {str(e)}")
finally:
consumer.close()
В этом коде потребитель с помощью метода poll() ожидает новые сообщения из Kafka. При получении сообщения проверяет наличие ошибок и десериализует сообщение с помощью десериализатора AvroDeserializer и парсит десериализованное сообщение, извлекая из него все поля. Извлеченные данные записываются в Google Sheets, начиная с первой строки и увеличивая номер строки после каждой записи.
Если в процессе возникают ошибки, они отлавливаются блоком except и показываются в области вывода. После завершения работы или при возникновении исключения, потребитель закрывается с помощью метода close().
Результаты потребления записываются в Google-таблицу:
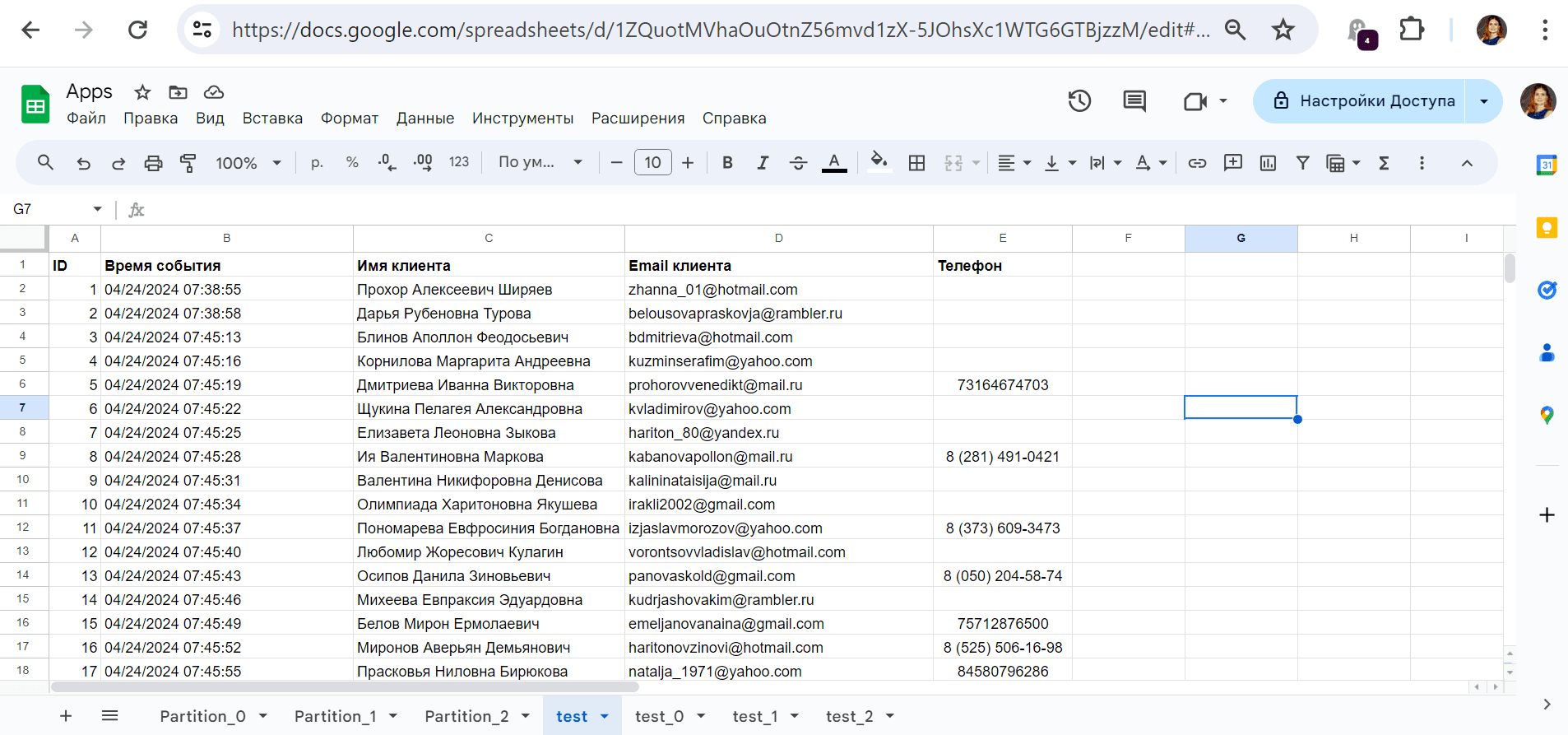
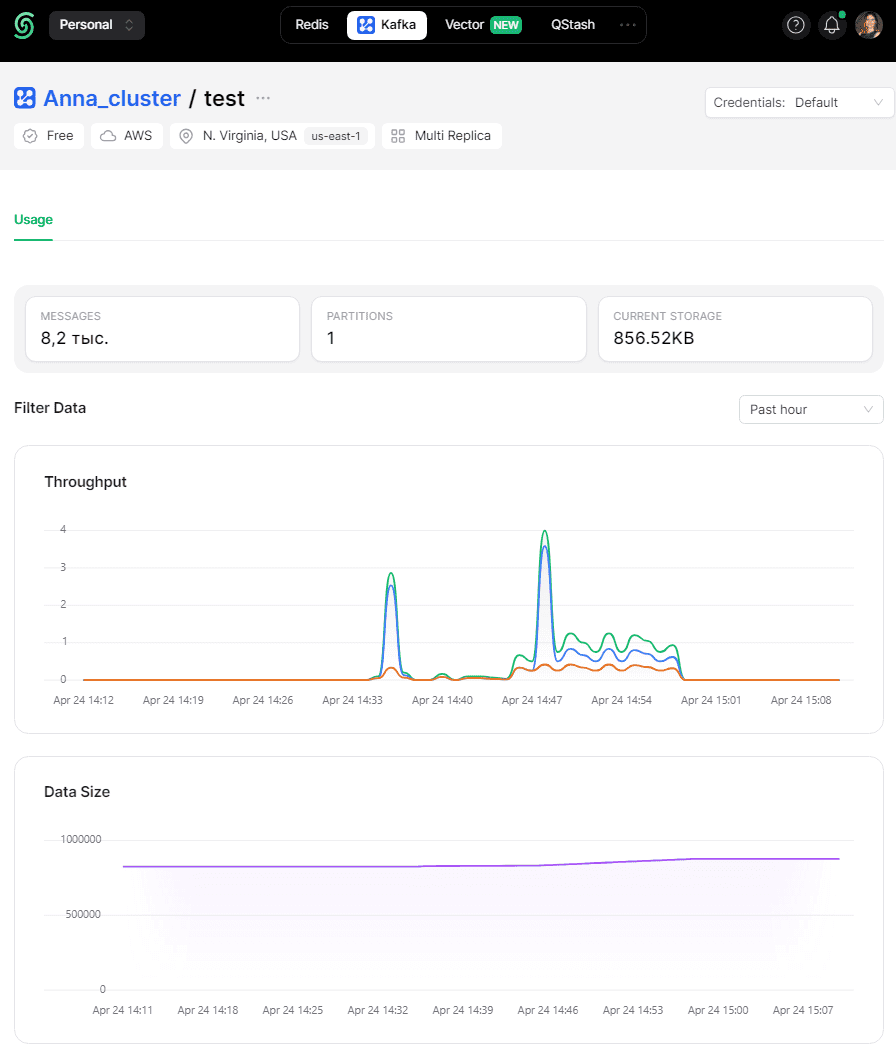
В GUI Upstash отображается график публикации и потребления сообщений.
Узнайте больше про администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве: