673
673 
Содержание
Что такое чистилище запросов, зачем это в потоковой обработке данных, при чем здесь иерархические колеса времени и как эта структура данных помогает Apache Kafka выполнять сотни тысяч асинхронных операций в секунду.
Что такое чистилище запросов и зачем это в Kafka
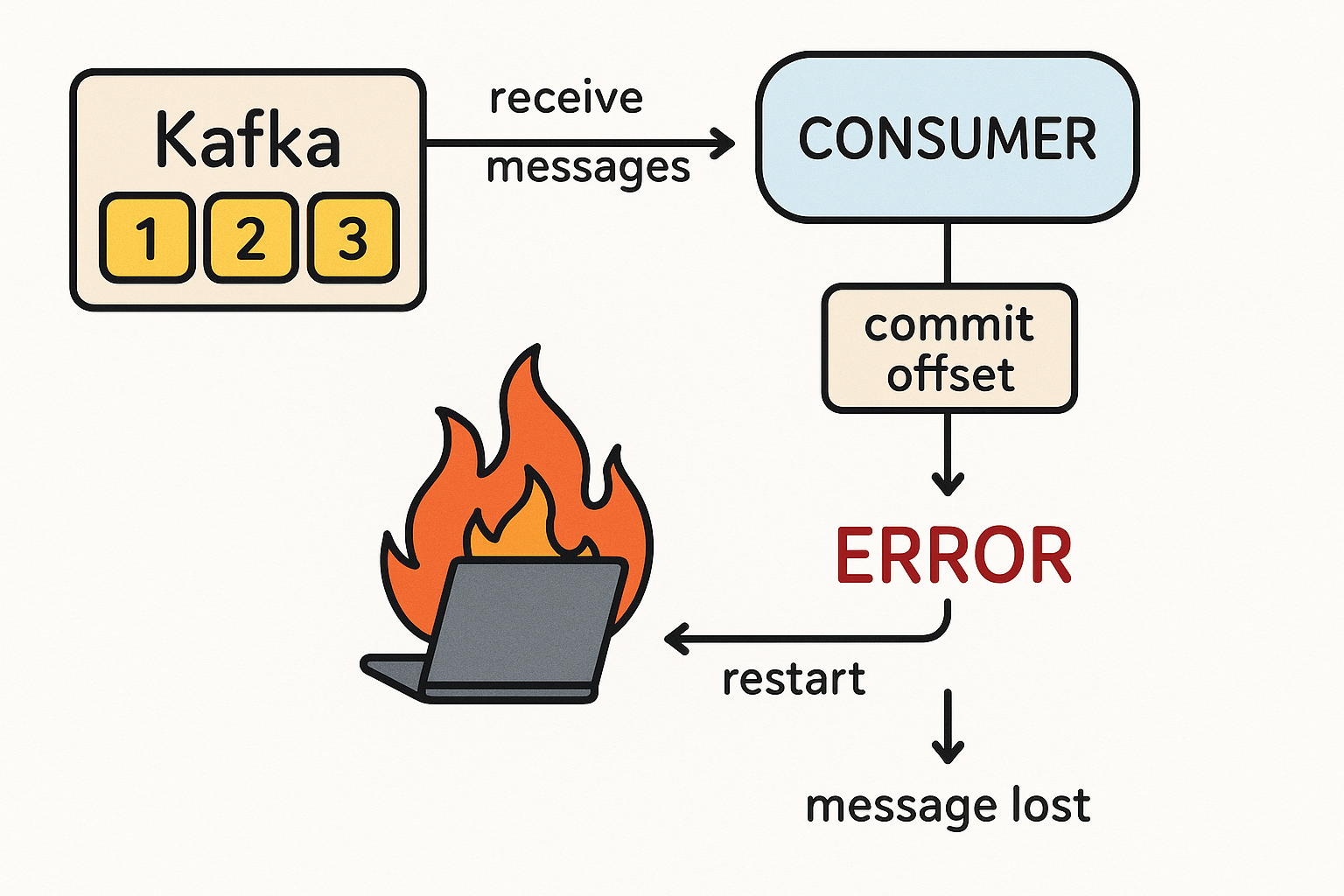
Будучи сложной распределенной системой, Apache Kafka реализует несколько типов запросов, которые не предполагают немедленного ответа. Например, публикация сообщения с подтверждением от всей брокеров-подписчиков (acks=all) не может считаться завершенным, пока все синхронизированные реплики не подтвердят запись, чтобы гарантировать сохранность сообщения при сбое лидера кластера. Fetch-запрос с настройкой min.bytes=1 не сработает, пока не появится хотя бы один новый байт данных для потребления. Это позволяет реализовать «длинный» опрос, чтобы потребителю не ждать, проверяя поступление новых данных. Такие запросы считаются завершенными, когда критерии их реализации выполнены или истекало время ожидания.
Количество этих асинхронных операций в любой момент времени увеличивается с ростом количества соединений, которое для Kafka часто составляет десятки тысяч. Чтобы работать с такими запросами, которые еще не завершились, в Kafka есть специальная структура данных, которая называет «чистилище запросов» (purgatory). Это можно рассматривать как некий буфер, который содержит любой еще не завершенный запрос, т.е. тот, что еще не соответствует критериям успешного выполнения, но и пока не привел к ошибке. В Kafka purgatory-механизм используется для управления отложенными операциями, такими как подтверждение записи или определение времени ожидания определенных условий при выполнении операций. Это позволяет Kafka эффективно управлять асинхронными процессами и сократить влияние задержек на производительность системы, что особенно с учетом сетевых задержек и сбоев отдельных узлов.
Чистилище запросов состоит из таймера тайм-аута и хэш-карты списков наблюдателей для обработки, управляемой событиями. Запрос помещается в чистилище, когда он не может быть немедленно выполнен из-за невыполненных условий. Запрос в чистилище завершается позже, когда выполняются условия, или истекает тайм-аут, когда он выходит за указанные пределы времени. Раньше, до 2015 года для реализации таймера использовался Java-класс DelayQueue — неограниченная блокирующая очередь отложенных элементов, откуда элемент может быть взят только после истечения его задержки. Головой очереди является тот элемент, задержка которого истекла раньше всего. Если задержка не истекла, то головы нет, и poll-вызов вернет null. Истечение срока происходит, когда метод getDelay(TimeUnit.NANOSECONDS) отложенного элемента возвращает значение, меньшее или равное нулю. Несмотря на то, что неистекшие элементы нельзя удалить с помощью методов take() или poll(), в остальном они обрабатываются как обычные элементы. Например, метод size() возвращает количество как просроченных, так и неистекших элементов. Очередь DelayQueue не допускает нулевых элементов.
Именно эта конструкция раньше использовалась в Kafka для таймеров, сопоставляя их местоположения с запросами через хэш-таблицу. Когда запрос завершался, он не сразу удалялся из таймера или списков наблюдателей. Удаление завершенных запросов происходило по мере их обнаружения во время проверки условий. Завершенные запросы (даже если они были успешны до истечения времени ожидания) удалялись только из хэш-таблицы, а очередь после их задержки истекала. Такая структура данных плохо масштабировалась с десятками тысяч невыполненных запросов. Это приводило к ошибке памяти вследствие исчерпания куча JVM. Чтобы исправить это, запускался отдельный поток, который очищал чистилище, удаляя завершенные запросы, когда их общее количество в чистилище превышало настроенный лимит. Операция очистки сканировала очередь таймера и все списки наблюдателей, чтобы найти выполненные запросы и удалить их. С низким значением этого параметра конфигурации можно избежать проблемы с памятью сервера, снизив его производительность из-за слишком частого сканирования очереди и списков.
Поэтому с 2015 года чистилище запросов Kafka было перепроектировано так, чтобы снизить нагрузку из-за дорогостоящего процесса очистки, разрешив немедленное удаление выполненного запроса. Для этого была разработана новая реализация на основе иерархических колес времени.
Иерархические колеса синхронизации и параметры настойки purgatory-механизма
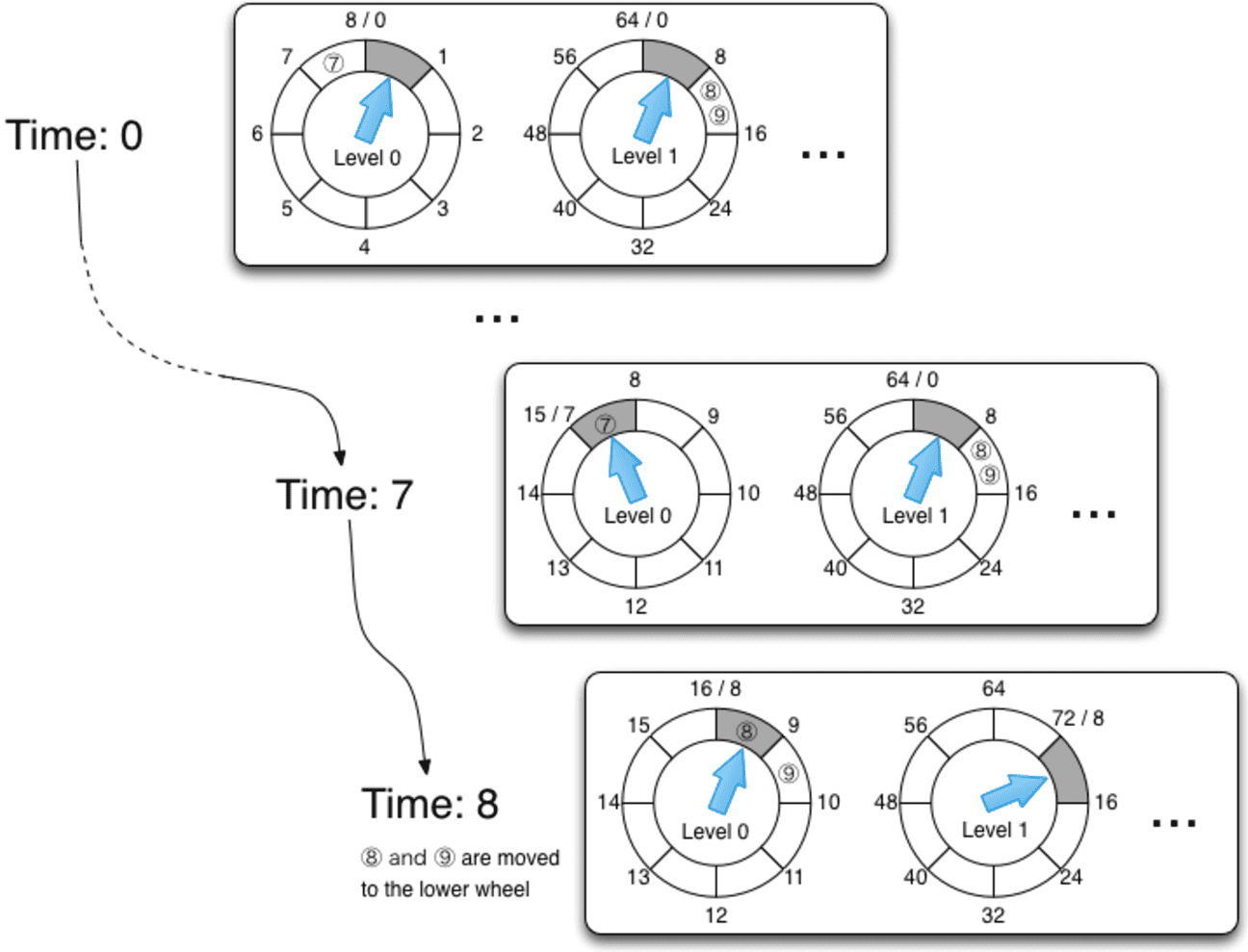
Иерархическое колесо времени (hierarchical timing wheel) — это структура данных для отслеживания и управления тайм-аутами операций, структурированное на несколько уровней, чтобы эффективно обрабатывать широкий диапазон временных интервалов с разной степенью точности. По сути, колесо времени — это способ организовать задачи таймера в виде кругового списка из какого-то количества ячеек. Каждая ячейка содержит задачи, которые должны выполниться в определённом интервале времени. Таймер каждый раз перескакивает на следующую ячейку и выполняет задачи, которые в ней находятся. В текущую ячейку новые задачи не добавляются, так как она уже прошла. Как только задачи выполнены, ячейка освобождается для следующего оборота времени.
Вставка и удаление задач в колесе времени происходит очень быстро и за постоянное время. Однако, в простом колесе времени задачи можно запланировать только на период, ограниченный количеством ячеек. Если задача выходит за эти пределы, возникает переполнение. Иерархическое колесо времени решает эту проблему, добавляя уровни с разными временными интервалами. Если задача не помещается в текущий уровень, она передаётся на вышестоящий уровень, при переполнении которого возвращается для исполнения на нижестоящий уровень.
Для реализации уровней в Kafka используется двусвязный список, что ускоряет вставку и удаление задач, позволяя делать это за постоянное и точно определенное время. Каждая задача хранит ссылку на своё положение в списке, которая позволяет обновить список при завершении или отмене задачи.
Для настройки чистилища в Kafka есть следующие конфигурации, которые определяются в количестве запросов:
- delete.records.purgatory.purge.interval.requests — интервал очистки чистилища запросов на удаление записей. Этот параметр определяет, как часто Kafka будет пытаться очистить чистилище запросов на удаление записей. По умолчанию он равен 1, т.е. попытка очистки будет происходить при каждом новом запросе. Если кластер обрабатывает много запросов на удаление записей из чистилища, можно увеличить это значение, чтобы снизить нагрузку на процессор, но это снизит скорость выполнения операций.
- fetch.purgatory.purge.interval.requests — интервал очистки чистилища запросов на выборку, по умолчанию равен 1000. Если кластер обрабатывает много запросов на выборку, т.е. потребители очень активно считывают данные, увеличение этого значения может снизить нагрузку на систему, но снизит скорость выполнения таких запросов.
- producer.purgatory.purge.interval.requests — интервал очистки чистилища запросов на публикацию данных. По умолчанию этот параметр тоже равен 1000. Для высоконагруженных систем с большим количеством запросов на публикацию увеличение этого значения сократит нагрузку на процессор, но увеличит задержку в подтверждении публикации сообщений.
Таким образом, настройка этих параметров чистилища Kafka зависит от объема данных, частоты запросов и толерантности к задержке потоковой обработки данных.
Освойте администрирование и эксплуатацию Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Apache Kafka в Kubernetes
Источники
- https://ferbncode.github.io/Apache-Kafka-and-Request-Purgatory/
- https://www.confluent.io/blog/apache-kafka-purgatory-hierarchical-timing-wheels/
- https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/DelayQueue/
- https://kafka.apache.org/documentation/
- https://www.confluent.io/blog/kafka-producer-and-consumer-internals-4-consumer-fetch-requests/