 884
884 
Как передать JSON-документы из топика Kafka в Elasticsearch, используя OpenSearch Sink Connector. Подробная демонстрация с настройкой и регистрацией коннектора в Kafka Connect.
Настройка sink-коннектора и отправка в Kafka Connect
Как передать данные из Kafka в Elasticsearch, я уже показывала здесь, развернув экземпляр Kafka в облаке на платформе Upstash. Однако, с 1 октября 2024 года Upstash перестала поддерживать коннекторы, а также с марта 2025 года вообще отключает инстансы этой платформы потоковой передачи событий. Поэтому мне пришлось развернуть образ от Confluent со всеми сопутствующими сервисами (GUI на AKHQ, Connect, Schema Registry) в Docker на своем локальном компьютере. На этом локальном развертывании, получив данные из PostgreSQL с помощью JDBC-коннектора источника, я решила передать их в облачный Elasticsearch 7.10.2, экземпляр которого у меня развернут в сервисе Bonsai.
Скачав с хаба Confluent архив Self-Hosted ElasticSearch Sink Connector confluentinc-kafka-connect-elasticsearch-14.1.2, его надо развернуть в папке jars, которая находится в директории с конфигурационным YAML-файлом контейнеров docker-compose. После этого можно настраивать конфигурацию коннектора и отправлять его в Connect, передав JSON-файл конфигурации с помощью POST-запроса.
Конфигурация моего коннектора к Elasticsearch 7.10.2, описанная в файле elastic-sink-connector.json, выглядела так:
{
"name": "elastic-sink-connector",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "ishop-product-product",
"connection.url": "https://my-host:my-port",
"type.name": "kafka-connect",
"key.ignore": "true",
"schema.ignore": "true",
"batch.size": "2000",
"max.retries": "5",
"retry.backoff.ms": "1000",
"max.buffered.records": "20000",
"flush.timeout.ms": "10000",
"linger.ms": "1000",
"max.in.flight.requests": "5",
"index.auto.create": "true",
"behavior.on.malformed.documents": "warn",
"connection.username": "my-user",
"connection.password": "my-password"
}
}
Но попытка отправить коннектор с этой конфигурацией в Kafka Connect с помощью инструкции
curl -X POST -H "Content-Type: application/json" --data @elastic-sink-connector.json http://localhost:8083/connectors
выдала ошибку
org.sourcelab.kafka.connect.apiclient.rest.exceptions.InvalidRequestException: Connector configuration is invalid and contains the following 4 error(s): Could not connect to Elasticsearch. Error message: Invalid or missing build flavor [oss] Failed to create client to verify connection. Invalid or missing build flavor [oss] Could not authenticate the user. Check the 'connection.username' and 'connection.password'. Error message: Invalid or missing build flavor [oss] Could not authenticate the user. Check the 'connection.username' and 'connection.password'. Error message: Invalid or missing build flavor [oss]
Эта ошибка связана с несовместимостью между используемой версией Elasticsearch и ожидаемой версией от коннектора. В частности, Confluent Elasticsearch Sink Connector требует коммерческую, а не OSS-версию Elasticsearch, которая поддерживает определённые функции. Поэтому вместо sink-коннектора к Elasticsearch пришлось использовать его открытую альтернативу: Opensearch. OpenSearch представляет собой вариацию Elasticsearch и Kibana, созданную после изменения лицензии Elasticsearch. Он предоставляет аналогичные функции для поиска и аналитики данных. Sink-коннектор OpenSearch работает аналогично Confluent Elasticsearch Sink Connector, позволяя передавать данные из топика в документо-ориентированную БД для индексации и поиска.
Скачав с Github архив opensearch-connector-for-apache-kafka-3.1.1 и распаковав его в папку jars, я настроила следующую конфигурацию коннектора:
{
"name": "opensearch-sink-connector",
"config": {
"connector.class": "io.aiven.kafka.connect.opensearch.OpensearchSinkConnector",
"tasks.max": "1",
"topics": "ishop-product-product",
"connection.url": "https://my-host:my-port",
"type.name": "kafka-connect",
"key.ignore": "true",
"schema.ignore": "true",
"batch.size": "2000",
"max.retries": "5",
"retry.backoff.ms": "1000",
"max.buffered.records": "20000",
"flush.timeout.ms": "10000",
"linger.ms": "1000",
"max.in.flight.requests": "5",
"index.auto.create": "true",
"behavior.on.malformed.documents": "warn",
"connection.username": "my-user",
"connection.password": "my-password"
}
}
Отправка коннектора с этой конфигурацией в Kafka Connect уже не выдает ошибок, а регистрирует коннектор и успешно запускает коннектор, что сразу видно в GUI.
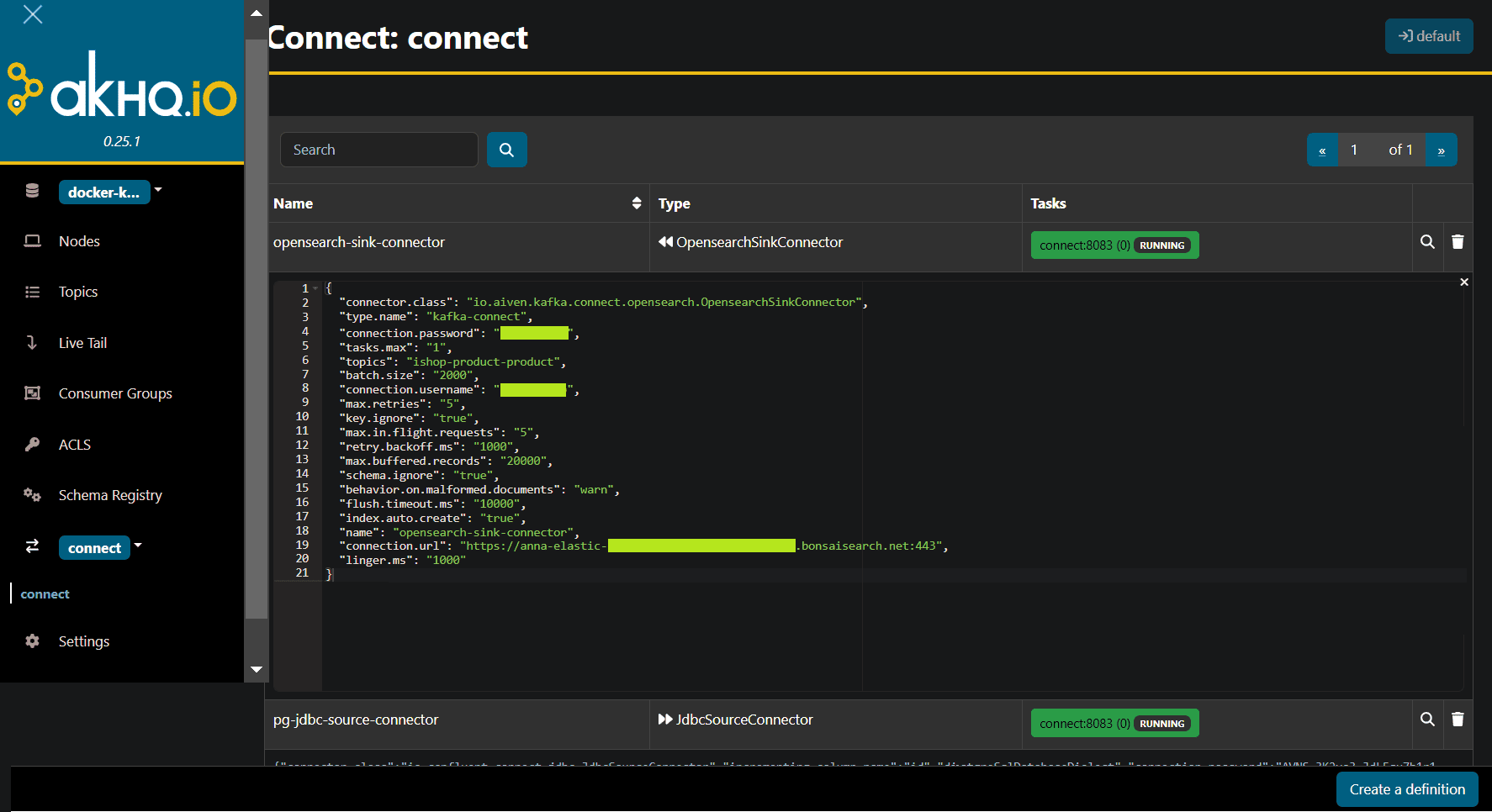
Поскольку в топике ishop-product-product уже есть данные в виде JSON-документов, полученные с помощью JDBC-коннектора из PostgreSQL, они сразу же передаются в Elasticsearch. Посмотреть это можно в интерфейсе сервиса Bonsai, отправив POST-запрос к автоматически созданному индексу в API поиска Elasticsearch:
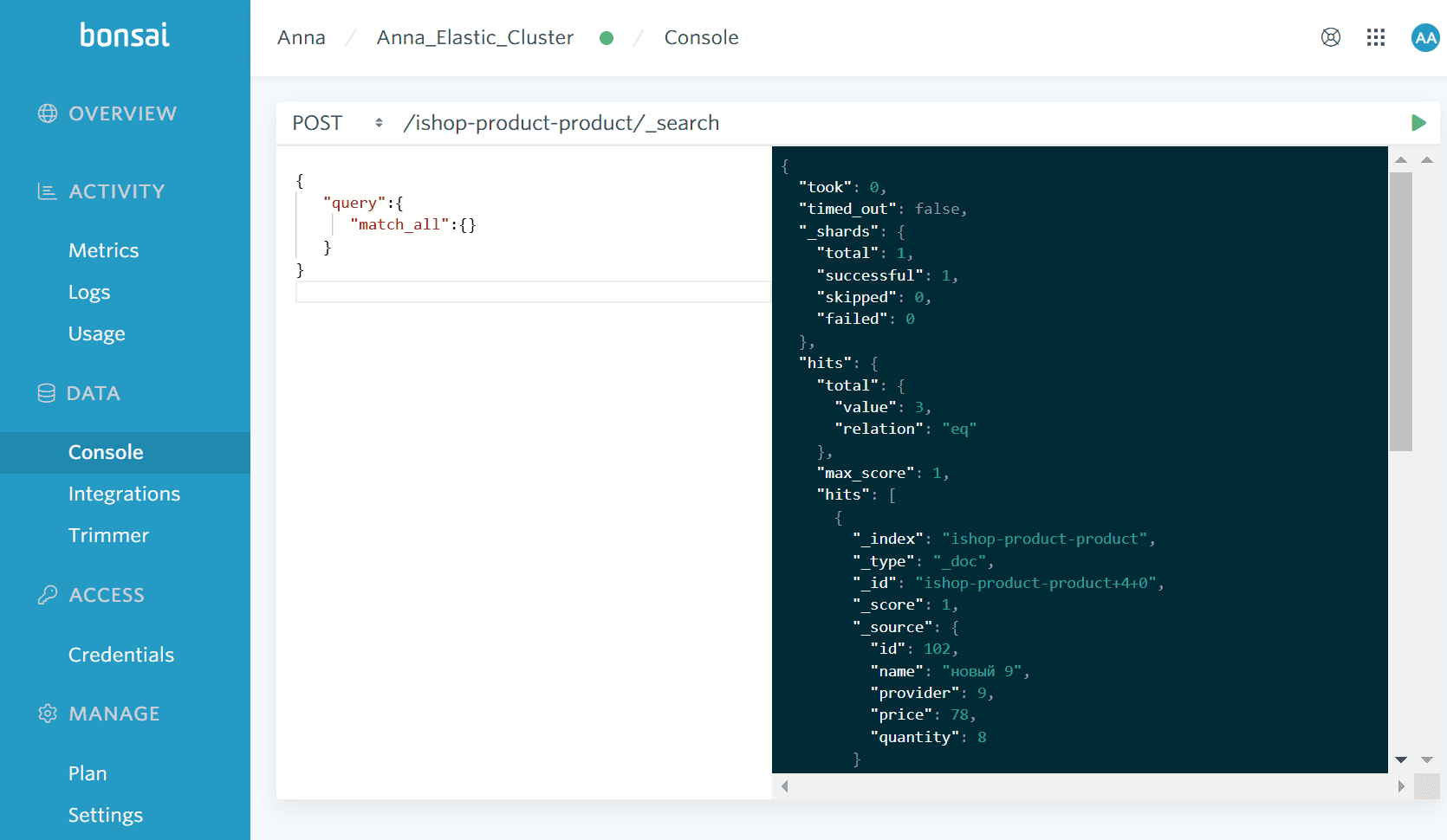
Таким образом, при использовании собственного развертывания Kafka Connect, надо очень тщательно обращать внимание на варианты коннекторов и их совместимость с разными версиями систем-источников и приемников.
Освойте администрирование и эксплуатацию Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

