 1621
1621 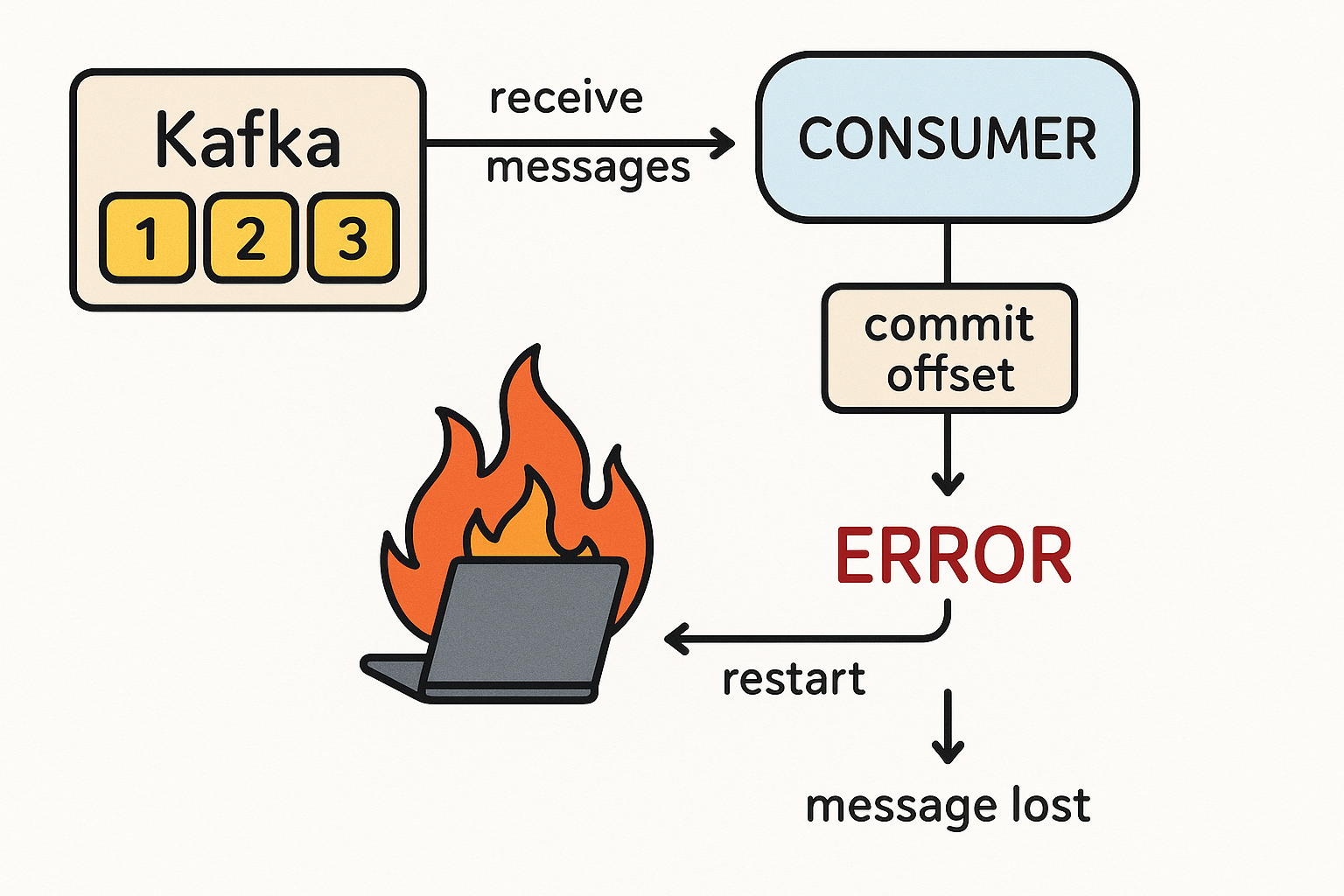
В мире распределенных систем, гарантии доставки сообщений, при передаче данных между сервисами — это фундаментальная задача. Но что происходит, когда мы отправляем сообщение из точки А в точку Б через сеть, которая по своей природе ненадежна? Сетевые задержки, сбои серверов, перезапуски приложений — все это может привести к потере или дублированию данных. Представьте, что вы отправляете важное письмо по обычной почте. В идеальном мире оно дойдет до адресата ровно один раз. Но в реальности письмо может потеряться в пути. Если вы не получите уведомление о вручении и отправите второе такое же письмо для подстраховки, адресат может в итоге получить два одинаковых письма. Эта простая аналогия отлично иллюстрирует ключевую проблему в асинхронном обмене сообщениями.
Чтобы управлять этими рисками, системы обмена сообщениями, такие как Apache Kafka, предоставляют различные гарантии доставки. По сути, это контракт между системой и разработчиком, который определяет, как система будет вести себя в случае сбоев. Существует три основных уровня этих гарантий:
At-Most-Once (не более одного раза) — сообщение либо доставляется один раз, либо не доставляется вовсе.
At-Least-Once (как минимум один раз) — система гарантирует доставку, но допускает появление дубликатов.
Exactly-Once (ровно один раз) — «святой грааль» доставки, гарантирующий, что каждое сообщение будет обработано ровно один раз.
В этой статье мы подробно разберем первые два уровня — At-Most-Once и At-Least-Once. Мы рассмотрим, как они реализуются в Apache Kafka, какие компромиссы предлагают и в каких сценариях их использование наиболее оправданно.
At-Most-Once (Не более одного раза): Скорость превыше всего
Концепция At-Most-Once — это классический принцип «выстрелил и забыл» (Fire & Forget). Система отправляет сообщение и не предпринимает повторных попыток, даже если произошла ошибка и сообщение не достигло цели. Это самая «слабая» гарантия с точки зрения надежности, но самая быстрая с точки зрения производительности.
Техническая реализация в Kafka
Для достижения семантики At-Most-Once необходимо настроить как продюсера (отправителя), так и консьюмера (получателя) определенным образом.
На стороне продюсера:
acks=0 или acks=1: Этот параметр контролирует, сколько подтверждений продюсер должен получить от брокеров Kafka перед тем, как считать отправку успешной.
acks=0: Продюсер не ждет вообще никакого подтверждения от брокера. Он просто отправляет сообщение в сетевой буфер и немедленно считает его доставленным. Если у брокера в этот момент возникнут проблемы, сообщение будет утеряно.
acks=1: Продюсер ждет подтверждения только от лидера партиции. Если лидер успешно записал сообщение, но не успел реплицировать его на другие брокеры и вышел из строя, сообщение также может быть потеряно.
retries=0: Необходимо отключить повторные отправки. Если продюсер не получил подтверждение (например, при acks=1), он не будет пытаться отправить сообщение снова, что исключает появление дубликатов, но увеличивает риск потери.
На стороне консьюмера:
Ключевой аспект — это момент фиксации смещения (офсета), который указывает на последнее обработанное сообщение. Для At-Most-Once консьюмер должен фиксировать офсет до фактической обработки сообщения.
Пример сценария потери:
- Консьюмер получает пачку сообщений из Kafka.
- Он немедленно фиксирует новый офсет в Kafka, сообщая системе: «я успешно обработал эти сообщения».
- Сразу после этого консьюмер падает из-за ошибки, не успев выполнить бизнес-логику (например, сохранить данные в базу).
- После перезапуска консьюмер начнет чтение со следующего, уже зафиксированного офсета, а предыдущее, необработанное сообщение будет навсегда утеряно.
Кейсы и примеры использования:
Сбор метрик и телеметрии: При сборе данных с тысяч IoT-устройств или сенсоров потеря нескольких отдельных показаний обычно не является критичной. Здесь гораздо важнее высокая пропускная способность и минимальные задержки.
Логирование: В системах агрегации логов потеря нескольких некритичных записей редко приводит к серьезным последствиям.
Стриминг неключевых событий: Например, отслеживание движения курсора мыши на сайте. Потеря нескольких событий не повлияет на общую картину анализа.
К плюсам можно отнести максимальную производительность, минимальные задержки и низкую нагрузка на систему, а к минусам высокий риск потери данных при любых сбоях.
At-Least-Once (Как минимум один раз): Золотой стандарт надежности
At-Least-Once — это, пожалуй, самая распространенная гарантия доставки сообщений в мире обработки данных. Система гарантирует, что каждое сообщение в конечном итоге будет доставлено и обработано, но ценой этого является возможный побочный эффект — дубликаты. Для многих бизнес-задач обработать одно и то же событие дважды менее страшно, чем не обработать его совсем.
Техническая реализация в Kafka на стороне продюсера:
acks=all (или acks=-1): Это самая надежная настройка. Продюсер будет считать отправку успешной только после того, как лидер партиции получит подтверждение о записи сообщения от всех синхронизированных реплик. Это гарантирует, что сообщение не будет потеряно даже в случае выхода из строя лидера.

retries > 0: Продюсер будет автоматически пытаться повторно отправить сообщение в случае временных ошибок (например, сбой сети). Именно эта комбинация настроек (acks=all и retries) может порождать дубликаты на стороне брокера.
На стороне консьюмера для реализации At-Least-Once консьюмер должен фиксировать офсет после успешной обработки сообщения. Это гарантирует, что если сбой произойдет во время обработки, офсет не будет зафиксирован, и после перезапуска консьюмер снова прочтет то же самое сообщение.
Пример возникновения дубликата рассмотрим детальный сценарий:
- Консьюмер получает сообщение из Kafka.
- Он успешно выполняет свою бизнес-логику: обрабатывает данные и сохраняет результат во внешнюю систему (например, в базу данных).
- Сразу после этого, но до того, как он успевает зафиксировать новый офсет в Kafka, консьюмер падает.
- Kafka не знает, что сообщение было успешно обработано.
- После перезапуска консьюмер обращается к Kafka и получает то же самое сообщение, поскольку офсет остался прежним.
- Он повторно обрабатывает сообщение, что приводит к созданию дубликата во внешней системе.
Кейсы и примеры использования:
Обработка заказов в e-commerce: Лучше дважды обработать один и тот же заказ и затем выявить дубль на уровне бизнес-логики, чем полностью его потерять.
Системы нотификаций (Email/SMS): Отправка пользователю двух одинаковых SMS-уведомлений менее критична, чем полная потеря важного уведомления.
Задачи с идемпотентной обработкой: At-Least-Once идеально подходит, когда операция обработки по своей природе идемпотентна.
Определение: Идемпотентность — это свойство операции, при котором ее многократное применение к одному и тому же объекту дает тот же результат, что и однократное. Например, операция UPDATE users SET status = ‘active’ WHERE user_id = 123 является идемпотентной. Неважно, сколько раз вы ее выполните, итоговый статус пользователя будет ‘active’. Разработчики часто проектируют потребителей таким образом, чтобы они были идемпотентными, например, используя в базах данных операции INSERT ON CONFLICT… или UPSERT.
Заключение
Выбор между At-Most-Once и At-Least-Once — это классический компромисс в распределенных системах. At-Most-Once предлагает максимальную скорость ценой риска потери данных, в то время как At-Least-Once обеспечивает надежность, но требует готовности к обработке дубликатов.
Давайте сведем ключевые различия в таблицу для наглядности.
| Характеристика | At-Most-Once (Не более одного раза) | At-Least-Once (Как минимум один раз) |
| Гарантия доставки сообщений | Сообщение доставлено 0 или 1 раз | Сообщение доставлено 1 или более раз |
| Производительность | Максимальная, минимальные задержки | Высокая, но с накладными расходами |
| Основной риск | Потеря данных | Дублирование данных |
| Настройки продюсера | acks=0 или acks=1, retries=0 | acks=all, retries > 0 |
| Логика консьюмера | Коммит офсета до обработки | Коммит офсета после обработки |
| Типичный сценарий | Некритичные метрики, логи | Обработка заказов, уведомления |
Хотя At-Least-Once с идемпотентными потребителями является мощным и широко используемым паттерном, для некоторых систем, особенно в финансовой сфере, дубликаты недопустимы в принципе. Как убедиться, что операция списания средств со счета произойдет ровно один раз? Эту сложную проблему решает третья, самая строгая гарантия — Exactly-Once. О том, как Apache Kafka достигает этого «святого грааля» с помощью идемпотентных продюсеров и транзакций, мы подробно поговорим в следующей статье.
Использованные референсы и материалы:
- Официальная документация Apache Kafka ( https://kafka.apache.org/documentation/ )
- Статья «Exactly-once Semantics are Possible» от Confluent ( https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/ )
- Гайд по надежной доставке сообщений в RabbitMQ (для сравнения подходов) ( https://www.rabbitmq.com/confirms/ )

