 867
867 
Что такое rich-функции в Apache Flink, зачем они нужны, чем отличаются от обыкновенных UDF и как с ними работать: простой пример на PyFlink с запуском в Google Colab.
Rich-функции в Apache Flink
Будучи очень мощным фреймворком для разработки распределенных потоковых приложений, Apache Flink не только предоставляет широкий набор stateful-функций, но позволяет создавать собственные. Поскольку в stateful-функциях нужен доступ к состоянию, т.е. сохраненных результатах предыдущего оператора, для этого нужны соответствующие механизмы. В Apache Flink доступ к состоянию осуществляется с помощью RuntimeContext, обратиться к которому можно через публичный интерфейс расширенных пользовательских функций (RichFunction). Этот класс определяет методы жизненного цикла функций, а также методы доступа к контексту, в котором выполняются функции.
Можно сказать, что rich-функции в Apache Flink — это интерфейсы, которые позволяют пользователю более гибко контролировать жизненный цикл функций и предоставляют дополнительные методы для инициализации и завершения работы. Они расширяют базовые функции, такие как MapFunction, FlatMapFunction, FilterFunction и пр., добавляя методы для управления состоянием и доступом к контексту выполнения.
Rich-функции предоставляют методы open() и close(), которые можно использовать для выполнения кода инициализации и завершения. Это полезно, например, для открытия и закрытия соединений с базой данных. С помощью метода getRuntimeContext() можно получить доступ к контексту выполнения, который предоставляет информацию о параллелизме, индексах подзадач и позволяет работать с распределенным состоянием в Apache Flink. Наконец, Rich-функции позволяют работать с состояниями, что критично для управления состоянием в потоковых приложениях.
Для демонстрации возможностей rich-функции рассмотрим небольшой пример на Python, который генерирует случайные имена, преобразует их в адреса электронной почты и выводит результат на консоль. Для инициализации и завершения используются методы open() и close(). Сперва установим библиотеки, необходимые для запуска программы PyFlink в интерактивной среде Google Colab.
!apt-get install openjdk-8-jdk-headless -qq > /dev/null !pip install apache-flink !pip install pyflink !pip install faker import os from pyflink.common import Types from pyflink.datastream import StreamExecutionEnvironment from pyflink.datastream.functions import MapFunction, RuntimeContext from faker import Faker from faker.providers.person.ru_RU import Provider import random
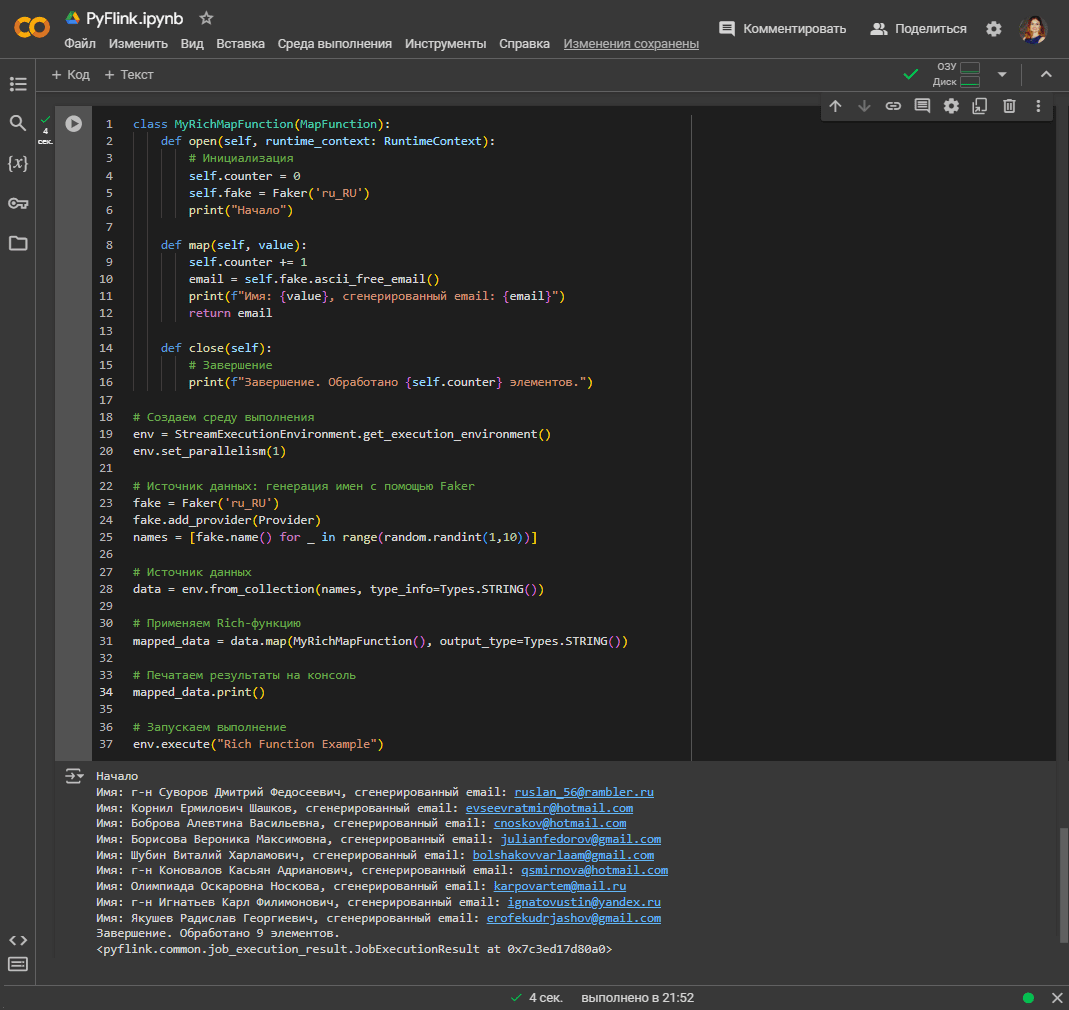
Далее напишем класс MyRichMapFunction с методами open(), map() и close(). Метод open() вызывается один раз перед началом обработки данных. Здесь происходит инициализация счетчика self.counter и генератора фейковых данных self.fake, а также выводится сообщение о начале обработки. Метод map() отвечает за преобразование и вызывается для каждого элемента в потоке данных. Он увеличивает счетчик, генерирует фейковый адрес электронной почты, выводит его вместе с именем и возвращает сгенерированный email. Метод close() вызывается один раз после завершения обработки данных и выводит сообщение с количеством обработанных элементов.
class MyRichMapFunction(MapFunction):
def open(self, runtime_context: RuntimeContext):
# Инициализация
self.counter = 0
self.fake = Faker('ru_RU')
print("Начало")
def map(self, value):
self.counter += 1
email = self.fake.ascii_free_email()
print(f"Имя: {value}, сгенерированный email: {email}")
return email
def close(self):
# Завершение
print(f"Завершение. Обработано {self.counter} элементов.")
# Создаем среду выполнения
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
# Источник данных: генерация имен с помощью Faker
fake = Faker('ru_RU')
fake.add_provider(Provider)
names = [fake.name() for _ in range(random.randint(1,10))]
# Источник данных
data = env.from_collection(names, type_info=Types.STRING())
# Применяем Rich-функцию
mapped_data = data.map(MyRichMapFunction(), output_type=Types.STRING())
# Печатаем результаты на консоль
mapped_data.print()
# Запускаем выполнение
env.execute("Rich Function Example")
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
31 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Сравнение с обычными UDF
Разумеется, можно обойтись без использования Rich-функций и использовать обычные функции преобразования данных, например, простые MapFunction. В этом случае код будет выглядеть так:
class SimpleMapFunction(MapFunction):
def __init__(self):
self.fake = Faker('ru_RU')
self.counter = 0
def map(self, value):
self.counter += 1
email = self.fake.ascii_free_email()
print(f"Имя: {value}, сгенерированный email: {email}")
return email
# Создаем среду выполнения
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
# Источник данных: генерация имен с помощью Faker
fake = Faker('ru_RU')
names = [fake.name() for _ in range(random.randint(1,10))]
# Источник данных
data = env.from_collection(names, type_info=Types.STRING())
# Применяем простую Map-функцию
mapped_data = data.map(SimpleMapFunction(), output_type=Types.STRING())
# Печатаем результаты на консоль
mapped_data.print()
# Запускаем выполнение
env.execute("Simple Function Example")
Он выдает ровно такие же результаты и, казалось бы, на первый взгляд, разницы нет. Однако, Rich-функции предоставляют методы open() и close(), которые позволяют выполнять инициализацию и освобождение ресурсов. В обычных функциях таких возможностей нет, что может затруднить работу с внешними ресурсами, например, подключение к базе данных, открытие файлов и пр. В обычных функциях нет методов open() и close(), что затрудняет выполнение инициализации и завершения ресурсов. В частности, инициализация генератора Faker происходит в конструкторе, но нет возможности явно освободить ресурсы после завершения обработки, например, закрыть файл источника или подключение к внешней базе данных.
Также в обычных функциях нет доступа к RuntimeContext, без которого невозможно получить информацию о контексте выполнения задачи, что ограничивает возможности мониторинга и адаптации логики на основе этой информации. Rich-функции имеют доступ к RuntimeContext, который предоставляет информацию о задаче, в которой выполняется функция, например, номер параллельного экземпляра, общее количество параллельных экземпляров и т.д.
Наконец, в обычных функциях нет встроенной поддержки метрик и счетчиков, что усложняет мониторинг и отладку производительности кода. А в расширенных функциях можно использовать встроенные счетчики и метрики для мониторинга выполнения, что упрощает отслеживание производительности и отладку.
Таким образом, при разработке Flink-приложений можно обойтись и без Rich-функций, что сделает код немного проще, но усложнит управление ресурсами и мониторинг выполнения потоковой программы.
Научитесь использовать Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.waitingforcode.com/apache-flink/data-enrichment-strategies-apache-flink/read
- https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/dev/datastream/fault-tolerance/state/
- https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/dev/datastream/user_defined_functions/
- https://nightlies.apache.org/flink/flink-docs-master/api/java/org/apache/flink/api/common/functions/AbstractRichFunction/

