
В этой статье для дата-инженеров и разработчиков распределенных приложений разберем кейс американской ИТ-компании FiscalNote, которая использует Apache Flink в качестве движка потоковой обработки информации со сторонних веб-сайтов. Трудности сериализации сообщений из очередей RabbitMQ с разной скоростью поступления Big Data и способы их обхода. Постановка задачи: требования для Flink-приложения FiscalNote специализируется...

Разбираемся с механизмами отказоустойчивости Flink-приложений. Что такое контрольные точки (Checkpoint), чем они отличаются от точек сохранения (Savepoint) и что между ними общего. А также при чем здесь snapshot, что выбирать в разных случаях и как это использовать для отказоустойчивости stateful-приложений Apache Flink. Snapshot как механизм обеспечения отказоустойчивости приложений Apache Flink...
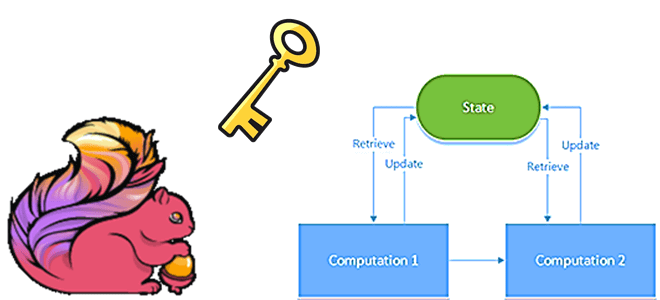
Что такое состояния в приложениях Apache Flink, каких видов они бывают, как ими управлять и зачем это нужно: основы разработки stateful-заданий и API DataStream. Чем состояние с ключом отличается от оператора состояния и почему первый чаще используется на практике. Состояния в Apache Flink Apache Flink поддерживает как stateful-, так и...
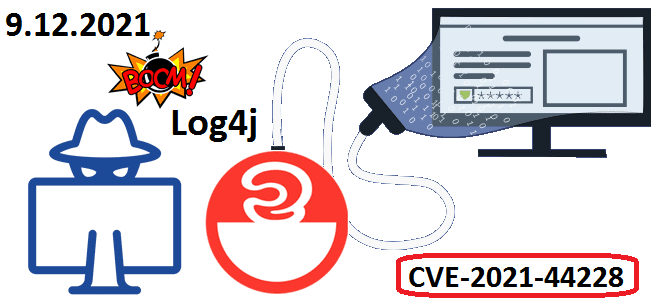
В начале декабря 2021 года мир ИТ взволновала новость о критической уязвимости CVE-2021-44228 в библиотеке Apache Log4j. Разбираемся, что это такое и чем опасно для систем хранения и аналитики больших данных на Apache Hadoop, Kafka, Spark, Elasticsearch и Neo4j. Критическая уязвимость в библиотеке Apache Log4j: чем опасна CVE-2021-44228 9 декабря...

Ранее мы писали о том, как фотохостинг Pinterest с помощью новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, объединяет пакетную и потоковую аналитику больших данных, чтобы еще лучше обслуживать более 475 миллионов своих пользователей. Сегодня поговорим про контроль сетевого трафика и синхронизацию источников данных через генерацию...

Сегодня рассмотрим, как индийская ИТ-компания Razorpay с помощью Apache Flink и Kafka свела к минимуму время простоя своего главного продукта - платежного шлюза для интернет-магазинов. Как всего 2 задания Flink могут быстро обнаруживать простои более 50 когорт событий на уровне платежного шлюза и 200+ когорт разных интернет-магазинов. Работать нельзя остановиться:...

Недавно мы писали, что в новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, сделаны попытки объединения потоковой и пакетной парадигм обработки данных. Сегодня рассмотрим, как подобное стремление к унификации реализуется на практике дата-инженерами фотохостинга Pinterest, которые используют Apache Flink как универсальный инструмент аналитики больших данных в...

29 сентября 2021 года вышла новая версия популярного Big Data фреймворка Apache Flink. Мы сделали краткий обзор главных улучшений свежего релиза 1.14 общедоступного дистрибутива, а также его коммерциализации в Ververica Platform 2.6. Узнайте, как потоковая обработка и аналитики больших данных с Apache Flink станет еще проще и эффективнее. Исправление ошибок...

Продолжая недавний разговор про потоковую передачу событий и соответствующие Big Data инструменты, сегодня рассмотрим не отдельные фреймворки обработки данных в режиме реального времени, а комплексные платформы, которые объединяют сразу несколько технологий для интерактивной аналитики больших данных. Вас ждет краткий обзор Cloudera Streaming Analytics, Materialize и Rockset: что это такое, как...

В продолжение недавней статьи для дата-инженеров про альтернативные платформы потоковой передачи событий вместо Apache Kafka, сегодня рассмотрим пример аналитики больших данных средствами Flink SQL, записи результатов в Elasticsearch и их визуализации в Kibana. Читайте далее, чем Redpanda отличается от Kafka, а Flink – от Apache Spark с точки зрения потоковой...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...

Сегодня рассмотрим пару кейсов по использованию Apache Flink в качестве основного фреймворка пакетной и потоковой аналитики больших данных. Читайте далее, как фото-хостинг Pinterest построил вокруг Flink собственную инфраструктуру работы с изображениями в реальном времени, а китайский ритейл-гигант Alibaba Group успешно обрабатывал 7 ТБ в секунду во время глобального дня шопинга....

Реклама является одним из наиболее крупных сегментов практического применения технологий Big Data. Поэтому сегодня рассмотрим, как Flink SQL реализует потоковую аналитику больших данных в AdTech-кейсах. Разбираем пример JOIN-соединения двух потоков событий - показов и кликов, чтобы вычислить конверсию рекламной кампании средствами Apache Flink или Spark. Потоки Big Data за фасадом...

Сегодня рассмотрим, как построить конвейер потоковой обработки событий на Apache Kafka, Flink и SQL Stream Builder с визуализацией результатов в Grafana. Далее вас ждет практический кейс применения технологий Big Data в реальном производстве на примере телеметрии процессов ферментации продуктов в небольшой частной пивоварне. Постановка задачи: бизнес-контекст и используемые технологии В...

В рамках обучения разработчиков распределенных приложений, сегодня рассмотрим, как упростить тестирование и отладку заданий Apache Flink с помощью Byteman. Читайте далее, как внедрить Java-код в JVM, чтобы извлечь нужные сведения о выполнении Flink-приложения на платформе Veverica и ускорить разработку. Разработка и отладка приложений Apache Flink: ежедневные сложности В рассматриваемом примере...

Продолжая разбирать особенности разработки потоковых приложений Apache Flink, сегодня рассмотрим проблему падения пропускной способности задания из-за встроенного хранилища состояний RocksDB и ее зависимость от производительности дисков. Вас ждет настоящая детективная история о том, как важно заглядывать под капот облачных кластеров и настраивать конфигурации своих stateful-приложений потоковой аналитики больших данных с...

Мы уже рассказывали, что приложения Kafka Streams используют RocksDB в качестве хранилища состояний. Сегодня рассмотрим, как это key-value NoSQL-СУБД используется для разработки stateful-приложений Apache Flink. Читайте далее о преимуществах и особенностях применения RocksDB для управления состоянием Flink-приложения, а также заблуждениях, связанных с этими фреймворками. 3 бэкенда Apache Flink для хранения...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...

Проанализировав сходства и различия пяти самых популярных Big Data фреймворков для распределенных потоковых вычислений (Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza), в этой статье мы сравним их по 10 критериям и отметим, какие именно факторы являются наиболее значимыми для объективного выбора. Сравнительный анализ самых популярных фреймворков потоковой обработки...

В этой статье мы рассмотрим, чем похожи и чем отличаются 5 самых популярных инструментов распределенной обработки потоков Big Data: Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza, а также поговорим про наиболее значимые факторы выбора между этими программными средствами. 5 общих характеристик распределенных Big Data фреймворков потоковой обработки Прежде...