
Как не запутаться в многообразии коннекторов к Kafka, доступных во Flink Table API, и выбрать наиболее подходящий для своего сценария применения. Разница между Append Mode и Upsert-режимом коннектора Flink SQL к Kafka. 2 режима работы коннектора Kafka в Apache Flink Apache Flink поставляется с универсальным соединителем Kafka, который поддерживает последнюю...

23 марта 2023 года вышел очередной релиз Apache Flink. Разбираемся с главными новинками выпуска 1.17.0: полезные фичи, исправленные ошибки и улучшения для дата-инженера и разработчика распределенных приложений. Новинки пакетной обработки В Apache Flink 1.17 внесено множество изменений в области пакетной и потоковой обработки. В частности, добавлен новый пакетный Streaming Warehouse...

Мы уже писали, как можно развернуть контейнерные приложения Apache Flink для обработки больших объемов данных в реальном времени. В продолжение этой темы сегодня сравним развертывание Flink-заданий в Kubernetes и в кластере AWS EMR. Flink-приложение в Kubernetes: преимущества и недостатки Apache Flink — это мощный фреймворк с открытым исходным кодом для...

Недавно мы писали про использование AirFlow для оркестрации dbt-конвейеров. Сегодня познакомимся с адаптером dbt-flink, который позволяет запускать SQL-конвейеры в проекте dbt на Apache Flink. Зачем нужен адаптер dbt к Apache Flink и как он работает В аналитике данных огромную роль играет эффективный, стабильный и надежный ETL-процесс, реализовать который можно с...
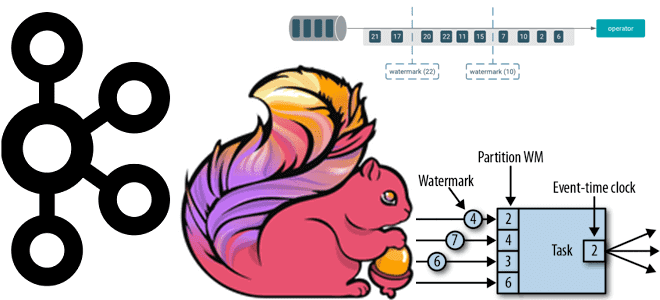
Почему вместо автоматической фиксации топиков Kafka приложению-потребителю Apache Flink лучше использовать контрольные точки, как создаются и обрабатываются водяные знаки и при чем тут оконные операторы потоковой обработки данных. Смещение в топиках Kafka для потоковых приложений Apache Flink Благодаря мощному API пакетной и потоковой обработки, Apache Flink часто используется для разработки...
Как протестировать работу приложения Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Разбираем особенности ручного и автоматизированного тестирования Flink SQL на уровне отдельных функций, модулей и их интеграционного взаимодействия. Модульное и интеграционное тестирование приложений Apache Flink SQL Тестирование является неотъемлемой частью любого процесса разработки ПО,...
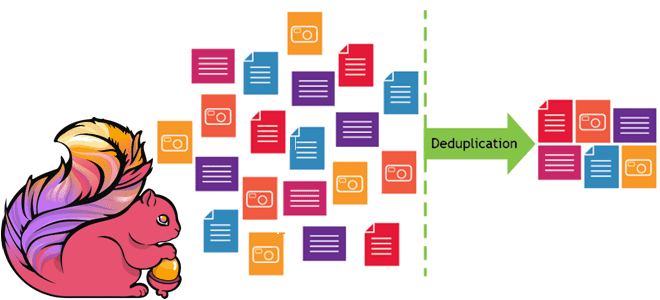
Чем опасны дубли данных при их потоковой обработке и как реализовать дедупликацию в Apache Flink SQL. Смотрим на практическом примере для обучения дата-инженеров и разработчиков распределенных приложений. Потоковая дедупликация данных в Apache Flink SQL Apache Flink можно назвать уникальный фреймворком для разработки распределенных приложений в области Big Data, который унифицирует...

28 октября 2022 года вышел мажорный релиз Apache Flink. Что нового в выпуске 1.16.0, который сегодня имеет официальный статус стабильного: зачем нужен SQL Gateway, как улучшен Changelog State Backend, какие DDL-выражения добавлены и зачем внесена поддержка кэширования результата преобразования в PyFlink. Главные обновления Apache Flink 1.16 В версии 1.16 Flink...

Сегодня рассмотрим, как оптимизировать потребление памяти в приложениях Apache Flink, разобрав основные принципы работы и конфигурации настройки памяти этого вычислительного фреймворка. А также перечислим типовые ошибки, с которыми дата-инженер может столкнуться при разработке и эксплуатации Flink-приложений Компоненты памяти в Apache Flink Apache Flink обеспечивает эффективные рабочие нагрузки поверх JVM, строго...

Зачем корпорации Confluent, которая продвигает Apache Kafka, понадобился Flink-стартап, чего ожидать от очередного слияния поглощения крупным игроком более мелкого предприятия, и какую пользу это принесет экосистеме потоковой передачи событий. Что Immerok и зачем это Confluent Год только начался, а в мире Big Data уже появились интересные новости. 6 января в...

Мы уже рассказывали, что Apache Flink использует Calcite для оптимизации SQL-запросов. Продолжая разбирать эту тему, важную для обучения разработчиков Flink-приложений и дата-инженеров, сегодня рассмотрим, как отследить происхождение отношения на уровне поля, используя методы класса RelMetadataQuery в Calcite. Что такое Apache Calcite и при чем здесь Flink SQL Напомним, Apache Flink...

Как оптимизатор Calcite в Apache Flink переводит SQL-команды в задания потоковой и пакетной обработки и какие приемы могут ускорить их выполнение. Разбираемся, чем полезны интерфейсы пользовательских коннекторов источника и подсказки запросов. Flink SQL в пакетной и потоковой обработке данных Apache Flink позволяет разрабатывать распределенные приложения потоковой обработки больших данных, предоставляя...
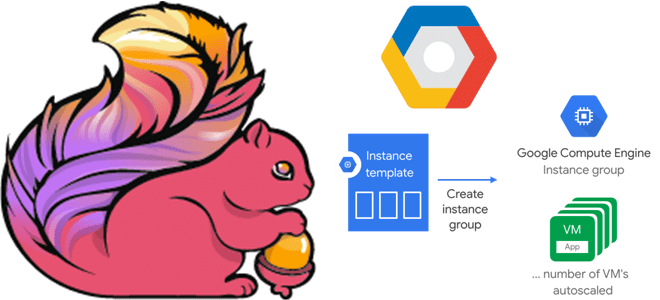
В этой статье для дата-инженеров и разработчиков Flink-приложений рассмотрим, как связаны диспетчеры задач и заданий, зачем настраивать автоматическое масштабирование кластера и как это сделать с помощью Google Auto Scaler в облачной инфраструктуре этого провайдера. Роль диспетчера заданий в Apache Flink и механизмы отказоустойчивости Apache Flink — отличный фреймворк создания приложений...

Чтобы добавить в наши курсы по аналитики больших данных еще больше практически примеров, сегодня рассмотрим, как современные технологий Big Data помогают в реальном времени выявлять телекоммуникационные мошенничества. Почему для антифрод-задач особенно подходит Apache Flink с его потоковом движком обработки данных и за счет чего этот фреймворк такой быстрый. Антифрод в...

Мы уже разбирали некоторые советы оптимизации Flink-приложений, связанные с неравномерным распределением данных по вычислительным узлам. Сегодня рассмотрим, как при этом пригодится паттерн MapReduce Combiner, который часто используется в экосистеме Apache Hadoop и вместо него лучше применить Bundle оператор, доступный с версии Flink 1.15. Проблема неравномерного распределения в Big Data вообще...

Чтобы сделать наши курсы по Apache Flink еще более полезными для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных, сегодня разберем, как работают источники данных потоковой обработки на примере топиков Kafka. Источники данных в Apache Flink Наряду с Apache Spark, Flink также является популярным фреймворком пакетной и потоковой обработки...

В этой статье для обучения дата-инженеров и разработчиков приложений потоковой аналитики больших данных рассмотрим, на что следует обратить внимание при развертывании Apache Flink в реальных проектах. Обработка опоздавших данных, тонкости сериализации, проблемы неравномерного распределения и большие состояния заданий. Обработка опоздавших данных в Apache Flink В потоковой обработке данных, которую поддерживает...
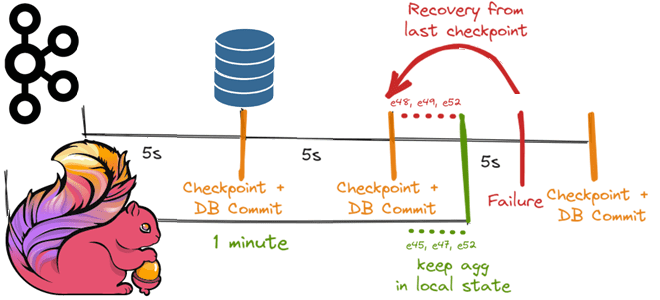
Как Apache Flink реализует строго однократную доставку событий в потовой обработке данных с помощью контрольных точек для записи данных в реляционную базу, используя функцию TwoPhasedCommitSink(), основанную на механизме согласованных snapshot’ов 35-летней давности и Kafka Transaction API. Трудности строго однократной доставки в потоковой обработке данных Распределенная обработка потоков с отслеживанием состояния...
Сегодня рассмотрим, как реализовать MLOps-идеи при разработке приложений Apache Flink с использованием MLeap, библиотеки сериализации для моделей машинного обучения. Зачем инженеры GetInData разрабатывали для этого свой коннектор и как его использовать на практике. Что такое MLeap и при чем здесь MLOps Будучи популярным вычислительным движком для потоковой аналитики больших данных,...
Мы уже писали про поиск сложных событий при их потоковой обработке средствами Apache Flink. Продолжая эту важную для обучения дата-инженеров тему, сегодня рассмотрим, как CDC-коннектор от GetIndata упрощает запуск распознавание шаблонов на потоках данных из многих источников. Проблемы захвата измененных данных из реляционной базы с помощью JDBC-драйвера и способы их...