 1640
1640 
Содержание
- Миссия: обрабатывать огромные объемы данных с максимальной скоростью
- В чем секрет скорости? Колоночное хранение против строкового
- В чем преимущество колоночного хранения ClickHouse для аналитики?
- Дополнительные преимущества колоночной СУБД:
- Ключевые преимущества ClickHouse: Почему его выбирают?
- Где используется ClickHouse? Примеры из реального мира
- Начинаем работу: локальная установка через Docker
- Альтернатива: быстрый старт с ClickHouse Cloud
- Подключитесь к ClickHouse Cloud
- Создаем первую таблицу и работаем с данными
- SQL-блокнот к Уроку 1 бесплатного курса доступен в нашем репозитории на GitHub
Данной статьей мы начинаем Бесплатный курс по «Основам ClickHouse для аналитиков и дата инженеров», который будет состоять из 10 уроков с практическими занятиями код которых будет доступен для скачивания на нашем GitHub аккаунте.
Если ваша работа связана с данными, вы наверняка слышали название ClickHouse. Это не просто очередная база данных, а мощный инструмент, который стремительно меняет подходы к аналитике в IT-компаниях по всему миру. В этой статье мы подробно разберемся, что же такое ClickHouse, почему он феноменально быстр в аналитических задачах и, самое главное, как вы можете начать с ним работать уже сегодня — как локально на своем компьютере, так и в облаке.
Миссия: обрабатывать огромные объемы данных с максимальной скоростью
История ClickHouse началась в 2009 году в стенах компании Яндекс, где он был создан для обслуживания системы веб-аналитики Яндекс.Метрика. Представьте себе задачу: обрабатывать триллионы событий ежедневно. Традиционные реляционные базы данных, такие как PostgreSQL или MySQL, просто не справлялись с такими колоссальными нагрузками. Стало очевидно, что нужен принципиально новый подход.
Именно так и родилась главная миссия ClickHouse ( далее CH): максимально быстро выполнять аналитические запросы (агрегацию, фильтрацию, группировку) на гигантских массивах данных. Важно понимать, что CH — это не замена базам данных для транзакционных операций, вроде банковских переводов или оформления заказов в интернет-магазине. Его стихия — это аналитика. В 2016 году Яндекс сделал ClickHouse проектом с открытым исходным кодом, что стало мощным толчком к его развитию и популярности в мировом IT-сообществе.
В чем секрет скорости? Колоночное хранение против строкового
Чтобы понять, почему CH так быстр, необходимо разобраться в его фундаментальном отличии от большинства привычных баз данных: он является колоночной СУБД (Column-Oriented Database Management System), в то время как PostgreSQL, MySQL, SQL Server и Oracle– строковые (Row-Oriented).
Давайте представим таблицу с данными:
| ID | Имя | Возраст | Город |
| 1 | Анна | 30 | Москва |
| 2 | Борис | 25 | Санкт-Петербург |
| 3 | Мария | 35 | Казань |
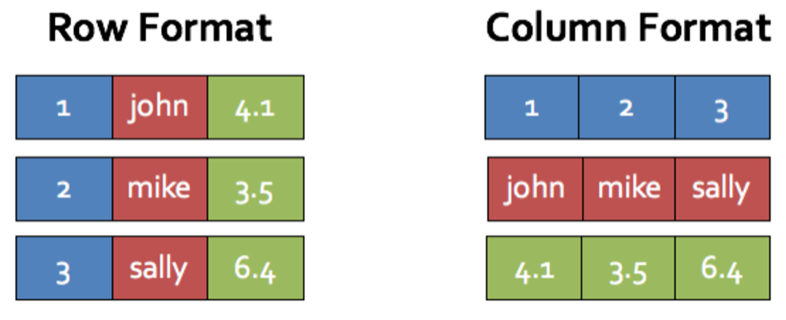
Как хранят данные строковые СУБД (например, PostgreSQL)? Они хранят данные по строкам. То есть, когда вы записываете строку, она сохраняется целиком:
[1, Анна, 30, Москва], [2, Борис, 25, Санкт-Петербург], [3, Мария, 35, Казань]
Это отлично подходит для транзакционных систем, где часто нужно получить или изменить всю информацию об одной сущности (например, все данные о конкретном пользователе).
Как хранят данные колоночные СУБД? CH хранит данные по столбцам. Это значит, что он группирует все значения одного столбца вместе:
[1, 2, 3] (столбец ID)
[Анна, Борис, Мария] (столбец Имя)
[30, 25, 35] (столбец Возраст)
[Москва, Санкт-Петербург, Казань] (столбец Город)
В чем преимущество колоночного хранения ClickHouse для аналитики?
Представьте, что вам нужно посчитать средний возраст пользователей: SELECT AVG(Возраст) FROM Таблица;
- В строковой СУБД: Базе данных придется прочитать все строки, чтобы добраться до значения «Возраст» в каждой из них. Это означает чтение большого объема ненужных данных (Имя, Город).
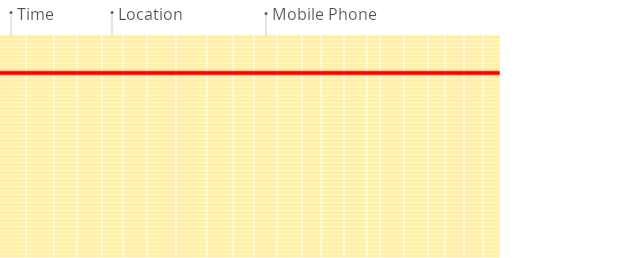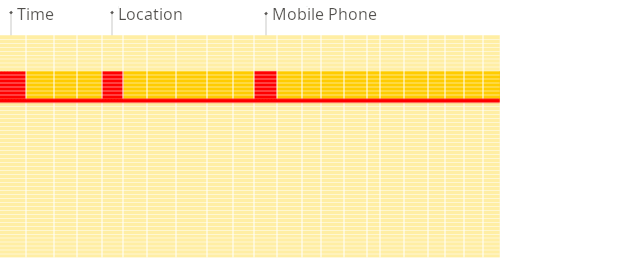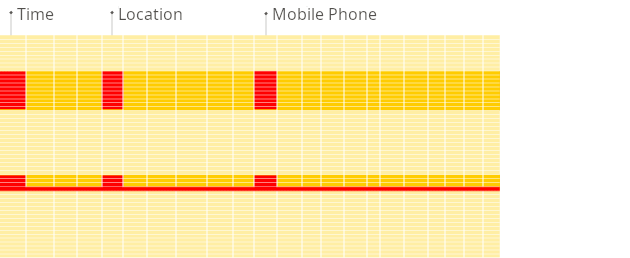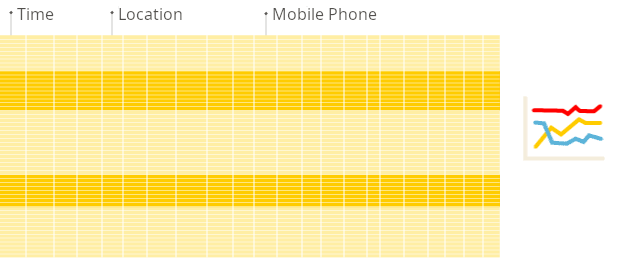
- В колоночной СУБД: ClickHouse просто считывает столбец «Возраст» целиком. Ему не нужно читать столбцы «Имя» и «Город». Это dramatically сокращает объем данных, которые нужно считать с диска, и значительно ускоряет выполнение запроса.

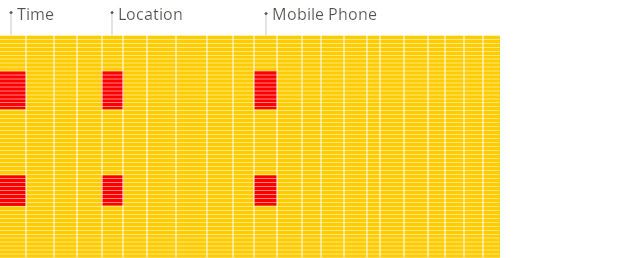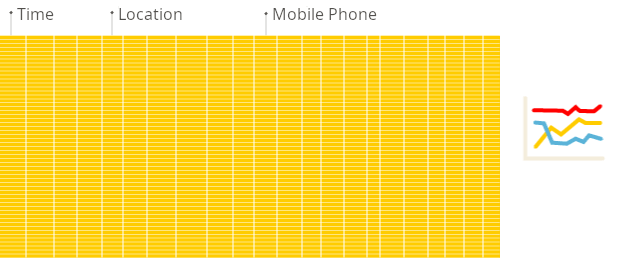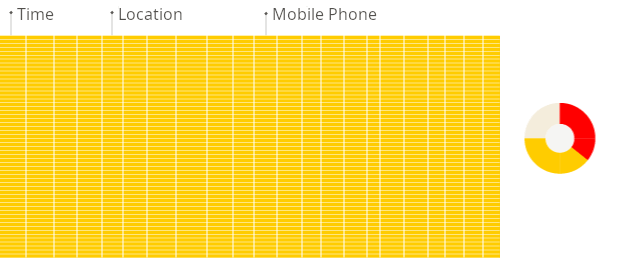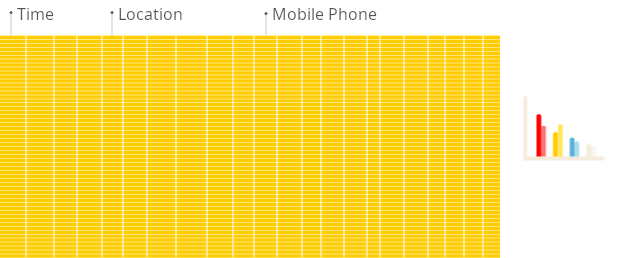
Дополнительные преимущества колоночной СУБД:
Высокая степень сжатия данных: Данные в одном столбце имеют один и тот же тип и часто схожие значения, что позволяет применять более эффективные алгоритмы сжатия. Например, столбец с boolean-значениями (true/false) или с ограниченным набором категорий (например, «мужской/женский») будет сжат намного лучше, чем случайный набор данных разных типов в строке. Это экономит место на диске и еще больше ускоряет чтение.
Эффективное использование CPU: ClickHouse спроектирован так, чтобы максимально загружать CPU за счет векторизованных вычислений. Это означает, что он обрабатывает данные пачками (векторами), а не по одному значению, что позволяет лучше использовать возможности современных процессоров.
Построение DWH на ClickHouse
Код курса
CLICH
Ближайшая дата курса
16 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Ключевые преимущества ClickHouse: Почему его выбирают?
Помимо колоночного хранения, CH обладает рядом других уникальных особенностей, которые делают его идеальным выбором для аналитики:
Феноменальная скорость: Это, пожалуй, главная причина. ClickHouse способен обрабатывать миллиарды строк за секунды. Он не просто быстр – он ультрабыстр. Вы почувствуете это на больших наборах данных.
Масштабируемость: CH легко масштабируется как вертикально (добавляя больше ресурсов одному серверу), так и горизонтально (добавляя новые серверы в кластер). Вы можете начать с одного сервера и по мере роста данных добавлять новые, распределяя нагрузку.
Поддержка SQL: CH использует расширенный диалект SQL, который интуитивно понятен всем, кто уже работал с реляционными базами данных. Это снижает порог входа для разработчиков и аналитиков.
Разнообразие движков таблиц: ClickHouse предлагает множество движков таблиц (Table Engines), каждый из которых оптимизирован для своих задач (например, MergeTree для обычной аналитики, ReplacingMergeTree для обработки дубликатов, Kafka для чтения из Kafka-топиков). Это дает огромную гибкость.
Расширенные аналитические функции: CH предоставляет богатый набор агрегатных функций, оконных функций, функций для работы с массивами и строками, что позволяет выполнять сложные аналитические запросы прямо в базе данных.
Открытый исходный код и активное сообщество: Будучи open-source проектом, CH активно развивается, имеет огромное сообщество пользователей и разработчиков, что обеспечивает быструю поддержку и появление новых функций.
Надежность и отказоустойчивость: Встроенные механизмы репликации и распределения данных обеспечивают высокую доступность и сохранность данных даже в случае сбоев отдельных узлов.
Где используется ClickHouse? Примеры из реального мира
Веб-аналитика: Яндекс.Метрика, Cloudflare, Sentry – сбор и анализ данных о посещениях сайтов, поведении пользователей, метриках производительности.
Ad-Tech: Анализ рекламных кампаний, кликов, показов, конверсий в реальном времени.
Мониторинг и логирование: Сбор и анализ логов серверов, приложений, сетевого оборудования для выявления аномалий и проблем.
IoT (Интернет вещей): Обработка потоков данных с датчиков и устройств.
Финансовые данные: Анализ транзакций, торговых операций, рыночных данных.
Телекоммуникации: Анализ CDR (Call Detail Records), трафика.
Если у вас есть большие объемы данных, которые нужно быстро агрегировать, фильтровать и анализировать, то ClickHouse – это ваш выбор.
Начинаем работу: локальная установка через Docker
Docker – это самый простой и быстрый способ запустить ClickHouse на вашей машине, будь то Windows, macOS или Linux. Убедитесь, что у вас установлен Docker Desktop, и выполните в терминале одну команду:
docker run -d --name clickhouse-server --ulimit nofile=262144:262144 -p 8123:8123 -p 9000:9000 clickhouse/clickhouse-server
Давайте разберем эту команду:
-d: Запускает контейнер в фоновом режиме (detached mode).
--name clickhouse-server: Дает вашему контейнеру понятное имя.
--ulimit nofile=262144:262144: Устанавливает лимит на количество открытых файлов для процесса ClickHouse (важно для производительности).
-p 8123:8123: Маппинг портов. Порт 8123 используется для HTTP-интерфейса ClickHouse (например, для подключения через веб-браузер или BI-инструменты).
-p 9000:9000: Порт 9000 используется для TCP-интерфейса (для clickhouse-client, JDBC/ODBC драйверов).
-p 9009:9009: Порт для ClickHouse Keeper (если вы будете использовать его для координации кластера, хотя на этом этапе это не критично).
clickhouse/clickhouse-server: Имя Docker-образа, который мы используем.
Docker скачает образ (если его еще нет) и запустит контейнер. Для подключения к вашему новому серверу проще всего запустить еще один контейнер с клиентом:
docker run -it --rm --link clickhouse-server clickhouse/clickhouse-client --host clickhouse-server
-it: Интерактивный режим.
--rm: Удалит контейнер клиента после выхода.
--link clickhouse-server: Связывает клиентский контейнер с контейнером сервера по имени (устаревший, но простой способ для одного хоста). В более новых версиях Docker или в production лучше использовать Docker Compose или сетевые настройки.
clickhouse/clickhouse-client: Образ клиента.
--host clickhouse-server: Указывает клиенту, к какому хосту подключаться (имя вашего контейнера).
Если все прошло успешно, вы увидите приветственное приглашение clickhouse :). Поздравляем, вы в консоли ClickHouse!
Альтернатива: быстрый старт с ClickHouse Cloud
Если вы не хотите заниматься установкой и настройкой, идеальным вариантом будет ClickHouse Cloud или Yandex Cloud Managed Service for Clickhouse. Это полностью управляемый сервис, который позволяет вам создать готовый к работе кластер ClickHouse за несколько минут.
Перейдите на сайт ClickHouse.com: Откройте ваш веб-браузер и перейдите на https://clickhouse.com/.
Зарегистрируйтесь и войдите в аккаунт:
Нажмите кнопку «Get Started» или «Sign Up». Вы можете зарегистрироваться, используя Google-аккаунт, GitHub или электронную почту. Обычно предоставляется бесплатный пробный период или стартовый лимит ресурсов.
Создайте новый сервис (Service):
После входа в панель управления ClickHouse Cloud, вы увидите опцию для создания нового сервиса. Вам будет предложено выбрать регион (например, AWS US East, GCP Europe West) и размер кластера (например, «Developer» или «Production» с разным количеством CPU и RAM). Для начала вполне подойдет минимальный «Developer» или «Starter» план. Присвойте имя вашему сервису.
Получите данные для подключения:
После создания сервиса (это может занять несколько минут), перейдите в его детали. Там вы найдете информацию для подключения:
Host (Endpoint): Адрес вашего ClickHouse Cloud инстанса (например, xxx.yyyy.gcp.clickhouse.cloud).
Port: Обычно 8443 (HTTPS) или 9440 (TCP/TLS).
User: Обычно default.
Password: Пароль, который вы можете сгенерировать или установить в настройках пользователя.
Важно: ClickHouse Cloud использует защищенные соединения (TLS/SSL) по умолчанию.
Подключитесь к ClickHouse Cloud
Подключиться к облачному сервису можно как через уже знакомый clickhouse-client, так и через множество популярных BI-инструментов, таких как DBeaver, DataGrip, Metabaseили Grafana.
Через Веб-интерфейс (ClickHouse Play): Самый простой способ. В панели управления ClickHouse Cloud обычно есть встроенный веб-интерфейс (или ссылка на него, часто называемый «ClickHouse Play» или «SQL Console»), где вы можете выполнять запросы прямо из браузера. Это отличный инструмент для быстрого тестирования и просмотра данных. Просто введите свои запросы и нажмите «Run».
Через clickhouse-client (локально): Если вы предпочитаете работать из терминала, можно использовать clickhouse-client с параметрами вашего облачного инстанса. Вам нужно будет указать хост, порт, пользователя и пароль, а также флаг --secure или --tls для защищенного соединения.
--пример команды (замените YOUR_HOST, YOUR_USER, YOUR_PASSWORD): clickhouse-client --host YOUR_HOST --port 9440 --user YOUR_USER --password YOUR_PASSWORD --secure
Через BI-инструменты (DBeaver, DataGrip, Metabase, Grafana и т.д.): Большинство популярных BI-инструментов имеют нативные коннекторы для CH. Вам просто нужно будет ввести полученные данные для подключения (хост, порт, пользователь, пароль) и убедиться, что включен SSL/TLS.
Создаем первую таблицу и работаем с данными
Теперь, когда у нас есть доступ к ClickHouse, давайте создадим нашу первую таблицу.
Разберем команду CREATE TABLE:
timestamp DateTime64(3): Тип данных DateTime64 позволяет хранить дату и время с точностью до миллисекунд (3 знака после запятой). DateTime хранит с точностью до секунды.
event_type LowCardinality(String): String – это обычная строка. LowCardinality – это модификатор типа данных, который очень эффективен для столбцов с небольшим количеством уникальных значений (например, event_type – у вас будет ограниченный набор типов событий). Он значительно экономит память и ускоряет запросы на фильтрацию и группировку по таким столбцам.
user_id UInt64: Беззнаковое 64-битное целое число. Хорошо подходит для ID.
ip_address IPv4: Специальный тип данных для IPv4-адресов, который хранит их как 32-битное целое число, что очень эффективно для хранения и фильтрации.
url String: Обычная строка для URL.
duration_ms UInt32: Беззнаковое 32-битное целое число для продолжительности.
ENGINE = MergeTree(): Мы указываем, что используем движок MergeTree. Это основной движок для таблиц, предназначенных для хранения больших объемов данных с сортировкой по первичному ключу.
ORDER BY (timestamp, user_id): Это ключ сортировки (primary key) для MergeTree. Данные на диске будут отсортированы по timestamp, а затем по user_id. Это очень важно для производительности ClickHouse, так как он использует этот порядок для быстрого поиска и агрегации данных. При выполнении запросов с WHERE условием по timestamp или user_id, ClickHouse сможет быстро отфильтровать нужные блоки данных.
Теперь вставим несколько строк и выполним первый аналитический запрос:
-- Вставляем данные
INSERT INTO access_logs VALUES
('2024-06-19 10:00:00.123', 'page_view', 101, '192.168.1.1', '/home', 150),
('2024-06-19 10:00:01.456', 'click', 101, '192.168.1.1', '/button_a', 20),
('2024-06-19 10:00:02.789', 'page_view', 102, '10.0.0.5', '/products', 300);
-- Выполняем аналитический запрос
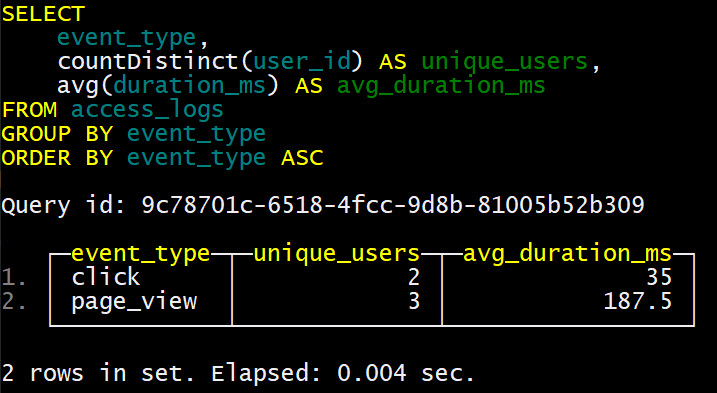
SELECT
event_type,
count(DISTINCT user_id) AS unique_users,
avg(duration_ms) AS avg_duration_ms
FROM access_logs
GROUP BY event_type;
-- весь код доступен для выгрузки в SQL блокноте на GitHub https://github.com/BigDataSchoolRU/clickhouse_intro_course
Обратите внимание, что INSERT в ClickHouse оптимизирован для массовой вставки данных. Вставка по одной строке (INSERT INTO ... VALUES (...)) неэффективна для больших объемов. В реальных сценариях данные обычно вставляются большими пачками (батчами) или потоками из Kafka, S3 и т.д. Посчитаем количество уникальных пользователей и среднюю продолжительность событий для каждого типа события:
Что дальше?
Эта статья — ваш первый шаг в мир высокопроизводительной аналитики. Вы узнали о философии ClickHouse, его ключевых преимуществах и научились выполнять базовые операции. Мы также приглашаем Вас посетить наши курсы для аналитиков и разработчиков на платформе ClickHouse а также посмотреть статьи посвященные использованию СУБД ClickHouse
Использованные референсы и материалы
- Официальная документация ClickHouse: https://clickhouse.com/docs/en/
- Сообщество ClickHouse на GitHub: https://github.com/ClickHouse/ClickHouse
- Интерактивная песочница ClickHouse Play: https://play.clickhouse.com/
SQL-блокнот к Уроку 1 бесплатного курса доступен в нашем репозитории на GitHub
Урок 1. Что такое ClickHouse: Полный гид по колоночной СУБД для сверхбыстрой аналитики.
Урок 2. Выбрать Типы данных и движки в ClickHouse: Фундамент для производительности.
Урок 3. Основы работы с данными в ClickHouse: вставка, выборка и первые аналитические запросы.
Урок 4. Продвинутые функции SQL в ClickHouse: обработка строк, дат и условная логика.
Урок 5. Глубокое погружение в движки MergeTree: Replacing, Summing, Aggregating и Collapsing.
Урок 6. Оптимизация запросов в ClickHouse: индексы, EXPLAIN и лучшие практики.
Урок 7. Интеграции ClickHouse: работа с MySQL, S3, Kafka и внешними словарями.
Урок 8. Аналитические суперсилы ClickHouse: Оконные функции и работа с массивами.
Урок 9. Администрирование и мониторинг ClickHouse: от системных таблиц до бэкапов.
Урок 10. Изучение ClickHouse: Итоги курса и следующие шаги в мире больших данных.

