 1146
1146 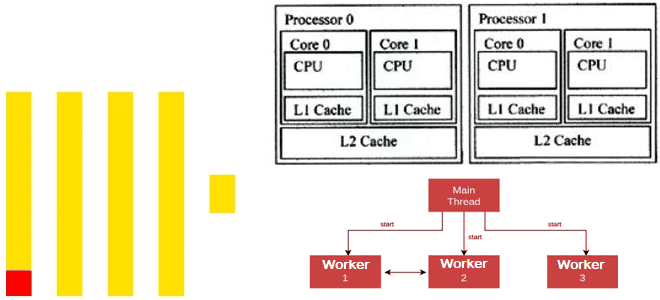
Как ClickHouse распараллеливает обработку данных для максимального использования всех ядер ЦП: особенности многопоточных вычислений в колоночной СУБД.
Особенности многопоточной обработки в Clickhouse
Современные центральные процессоры (ЦП) содержат несколько ядер и могут работать с несколькими задачами одновременно. Это называется многопоточной обработкой, где каждый поток, последовательность выполняемых инструкций, представляется как отдельная задача. На уровне операционной системы (ОС) многопоточный ЦП выглядит как несколько логических, количество которых обычно равно количеству ядер. Программная многопоточность для управления несколькими потоками внутри одного процесса поддерживается на уровне ОС, но реализуется в коде многопоточного приложения, чтобы ускорить его производительность. Именно так работает многопоточная обработка данных в ClickHouse.
Чтобы эффективно справляться с аналитической обработкой огромных объемов данных, ClickHouse изначально был спроектирован для максимального использования всех ресурсов ЦП. Поэтому СУБД способна достигать высокой производительности за счет:
- параллельного выполнения запросов несколькими потоками одновременно;
- параллельной обработки данных, когда разные части таблиц обрабатываются разными потоками;
- векторизованной обработки с помощью кэша ЦП и SIMD-инструкций, о чем мы уже писали здесь.
ClickHouse использует векторизованный движок выполнения запросов, обрабатывая данные не по одной записи, а блоками (обычно по 8192 записи). Это сокращает накладные расходы на вызовы функций, повышает эффективность использования кэша ЦП и позволяет компилятору применять SIMD-инструкции (Single Instruction, Multiple Data), обеспечивая параллелизм на уровне данных через реализацию множественного потока данных на одиночный поток команд. ClickHouse распределяет данные между потоками, каждый поток выполняет агрегацию своей части, затем результаты объединяются.
Благодаря колоночному хранению данных, в отличие от строковых СУБД, ClickHouse при выполнении запросов считывает только нужные колонки, т.к. данные одного типа хранятся последовательно, что улучшает локальность обращения. Это значительно сокращает объем данных, проходящих через кэш ЦП. Хотя потенциально ClickHouse может запускать много потоков для параллельной обработки данных, слишком большое количество потоков не рекомендуется, т.к. каждое переключение между потоками требует ресурсов процессора на смену контекста вместо полезной работы. Кроме того, потоки конкурируют за общие ресурсы, такие как кэш процессора, память и дисковый ввод-вывод. Это может привести к взаимоблокировкам и снижению производительности. Поскольку каждый поток требует выделения памяти для своего стека, общее потребление памяти прямо пропорционально количеству потоков. Наконец, добавление количества потоков эффективно до определенного порога, зависящего от конкретного оборудования и рабочей нагрузки. Поэтому ClickHouse оптимально работает, когда количество потоков сбалансировано с числом ядер ЦП, размером памяти и характером запросов. Обычно оптимальное количество потоков обычно соответствует количеству физических ядер или немного превышает его (в 1.5-2 раза), что позволяет эффективно использовать ресурсы без избыточных накладных расходов.
Модель параллелизма в ClickHouse построена на концепции главного и рабочих потоков:
- главный поток (master) — центральный элемент обработки любой задачи, с которого начинается любой запрос или фоновая операция. Он отвечает за планирование работы и координацию рабочих потоков, анализирует запрос и создает плана выполнения, распределяет задачи между рабочими потоками и собирает результаты от них. Также главный поток обеспечивает финальную обработку и формирование ответа. Он существует на протяжении всего запроса от начала до конца/
- рабочий поток (worker) — дополнительный вычислительный ресурс, динамически создаваемый главным потоком для параллельной обработки по мере необходимости. Он выполняет конкретные ресурсоемкие задачи, особенно интенсивные для ЦП операции: чтение частей данных, фильтрация наборов данных, агрегация промежуточных результатов, слияние отсортированных наборов данных. Рабочие потоки могут создаваться и завершаться многократно в рамках одного запроса.
ClickHouse разделяет данные на части и обрабатывает их параллельно, причем каждая часть может обрабатываться отдельным рабочим потоком. Количество рабочих потоков адаптируется к размеру и сложности задачи. Количество создаваемых рабочих потоков зависит от ресурсов ЦП, сложности запроса и текущей загрузки системы. Данные проходят через конвейер преобразований, каждый этап которого может быть распараллелен между рабочими потоками. Главный поток координирует работу конвейера, используя для управления алгоритм work-stealing (рабочие потоки, завершившие свои задачи, могут забирать задачи у других потоков) и динамически распределяя задачи в зависимости от загрузки и доступности ресурсов.
Пока рабочие потоки выполняют CPU-интенсивные операции, главный поток может заниматься операциями ввода-вывода. Эта модель хорошо масштабируется от однопроцессорных систем до многоядерных серверов. Взаимодействие между потоками можно представить так:
- при поступлении запроса создается главный поток;
- главный поток анализирует запрос и планирует его выполнение;
- для задач, поддающихся распараллеливанию, создаются рабочие потоки;
- рабочие потоки выполняют свои задачи параллельно;
- главный поток собирает и объединяет результаты работы;
- финальный результат формируется и возвращается клиенту.
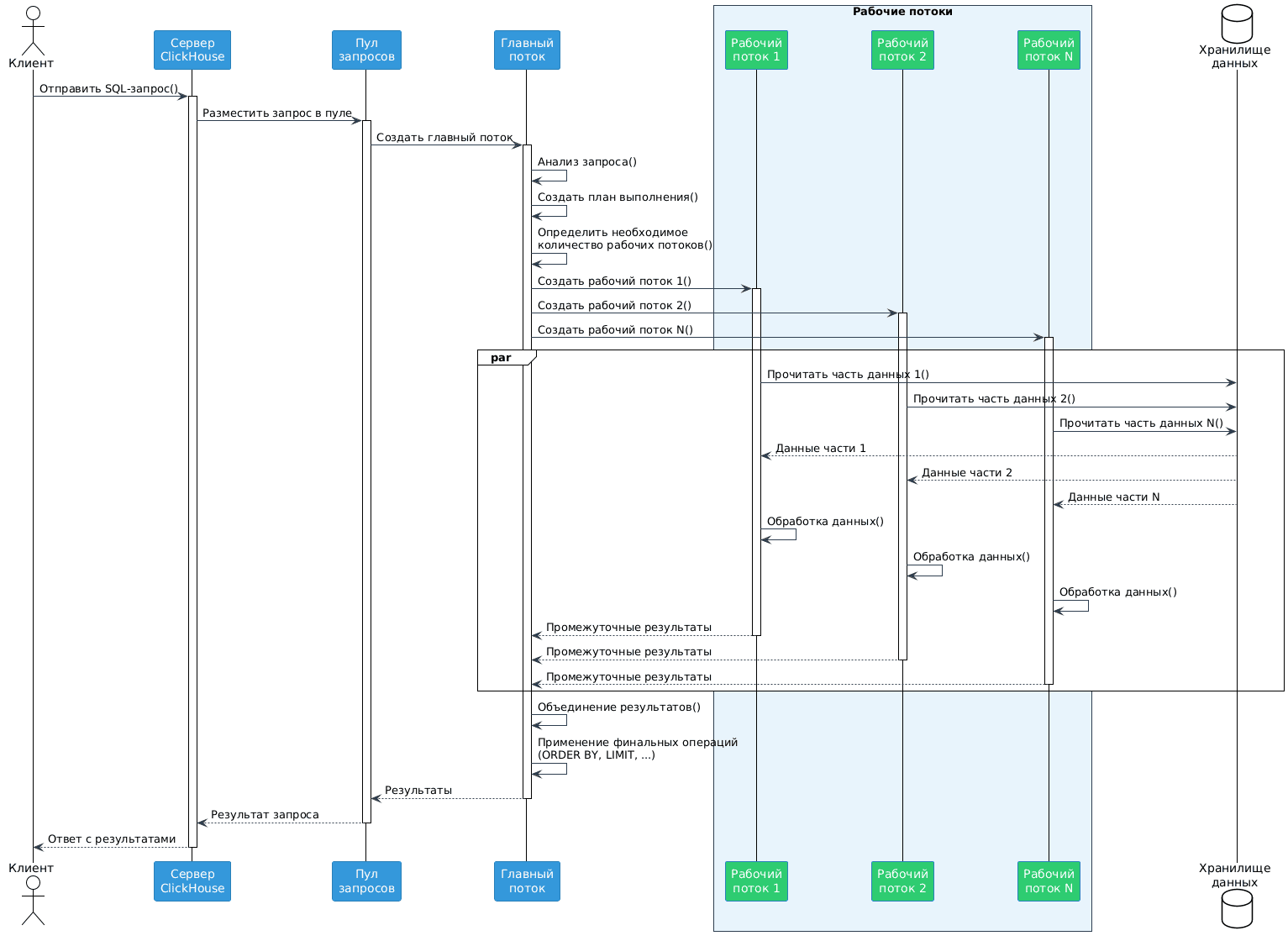
Взаимодействие между главным и рабочими потоками позволяет ClickHouse эффективно использовать многоядерные процессоры для аналитических запросов, обеспечивая высокую производительность и масштабируемость. При этом есть определенные рекомендации по настройке параллелизма. Лучше использовать несколько параллельных запросов с меньшим числом потоков, чем один запрос с большим числом потоков. Для оптимальной настройки многопоточности в ClickHouse надо следить за утилизацией ЦП, чтобы вовремя выявить наиболее ресурсоемкие запросы и запланировать для них соответствующий характер рабочей нагрузки. Как это сделать, рассмотрим в следующий раз, а пока поговорим про параметры управления потоками в этой колоночной СУБД.
Управление потоками
Для планирования нагрузки на ЦП в ClickHouse есть следующие параметры настройки количества потоков:
- max_threads— максимальное количество потоков для выполнения одного запроса;
- max_concurrent_queries— максимальное количество одновременно выполняемых запросов;
- background_pool_size — размер пула потоков для фоновых операций (слияния, мутации и т.д.);
- background_merges_mutations_concurrency_ratio — соотношение количества одновременных слияний/мутаций к количеству ядер процессора.
ClickHouse может автоматически определять оптимальное количество потоков для запроса на основе количества доступных ядер ЦП, объема данных для обработки и типа выполняемой операции. По умолчанию параметр max_threads устанавливается равным количеству ядер ЦП, но это можно настраивать.
Для управления потоками ClickHouse использует следующие пулы:
- Пул запросов— для обработки запросов SELECT, INSERT и других пользовательских операций. Контролируется параметрами max_threads и max_concurrent_queries. Он динамически распределяет доступные потоки между запросами, учитывая их приоритет, имеет механизмы предотвращения перегрузки системы и автоматически масштабирует ресурсы в зависимости от сложности запроса. Размер пула запросов обычно настраивается под количество логических ядер ЦП.
- Пул слияний— отвечает за фоновые операции слияния данных, что критично для таблиц семейства MergeTree. Он выполняет слияние частей данных после вставки или во время оптимизации таблиц. Управляется параметром background_pool_size, обычно равным 16 (по умолчанию). Критически важен для производительности и хранения данных. Этот пул работает асинхронно в фоновом режиме, имеет механизмы защиты от перегрузки дисковой подсистемы и автоматически регулирует интенсивность слияний в зависимости от нагрузки. Обычно настраивается в диапазоне 8-16 потоков для большинства систем.
- Пул мутаций— обрабатывает операции изменения данных (ALTER, UPDATE, DELETE). Выполняет фоновые операции изменения данных после выполнения команд мутации. Управляется параметром Создает новые части данных с примененными изменениями, заменяет старые части данных на новые. Мутации выполняются асинхронно, не блокируют другие операции с таблицей и могут быть ресурсоемкими для больших таблиц. Пул мутаций зависит от частоты операций UPDATE и DELETE.
- Пул планировщика— отвечает за координацию и планирование (управление расписанием) системных задач, таких как проверка необходимости слияний, контроль истечения срока хранения данных (TTL), разные задачи самообслуживания системы. Обеспечивает регулярное выполнение необходимых системных операций и имеет низкий приоритет по сравнению с пользовательскими запросами, поэтому адаптирует свое поведение к текущей нагрузке системы. При высокой нагрузке фоновые операции могут замедляться.
Пулы имеют разные приоритеты, обеспечивая первоочередное обслуживание пользовательских запросов. Можно настраивать размеры и поведение пулов с учетом профиля нагрузки ClickHouse, чтобы повысить производительность СУБД. Размер каждого пула должен соответствовать имеющимся ресурсам сервера и особенностям рабочей нагрузки. Как это сделать, рассмотрим в новой статье.
Освойте ClickHouse на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

