 1126
1126 
Содержание
В начале своего пути Apache Hadoop был настоящей революцией. Он предложил решение для обработки данных таких объемов, которые ранее считались невозможными, используя кластеры из обычного оборудования. Философия «перемещай вычисления к данным, а не данные к вычислениям» легла в основу мира Big Data. Но технологии не стоят на месте. Облачные платформы, новые движки обработки и объектные хранилища изменили правила игры.
Многие задаются вопросом: «Актуален ли Hadoop сегодня?». Ответ — да, но его роль кардинально изменилась. Он перестал быть монолитным решением «все в одном». Вместо этого Apache Hadoop превратился в фундаментальный слой и набор зрелых технологий, которые интегрируются в современные, гибридные архитектуры данных. В этом руководстве мы разберем, какие компоненты Hadoop остаются критически важными, как они работают с современными хранилищами вроде S3 и Ozone, и какую роль играют в облачных сервисах типа Yandex Data Proc и корпоративных платформах, таких как Arenadata.
Фундамент Apache Hadoop: Ядро, которое все еще имеет значение
Несмотря на эволюцию экосистемы, два ключевых компонента Apache Hadoop до сих пор составляют основу многих on-premise инсталляций. Понимание их работы — ключ к пониманию всей архитектуры больших данных.
HDFS: Надежное on-premise хранилище
HDFS (Hadoop Distributed File System) — это распределенная файловая система, спроектированная для хранения огромных файлов на кластерах из стандартных серверов. Ее главные преимущества — высочайшая отказоустойчивость за счет репликации данных и способность горизонтально масштабироваться. В современном мире HDFS по-прежнему является стандартом для построения локальных (on-premise) «озер данных», что особенно важно для компаний с жесткими требованиями к безопасности и суверенитету данных
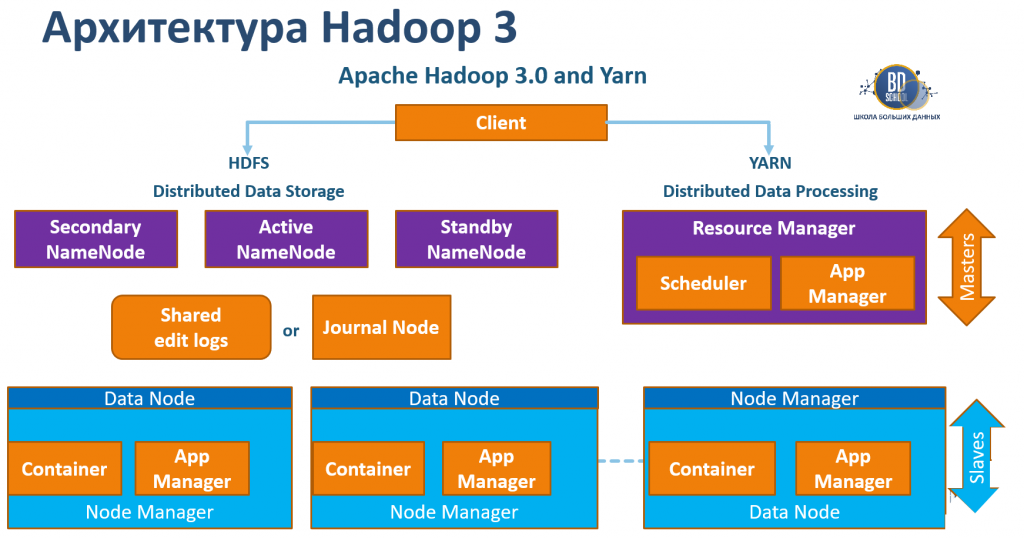
YARN: Универсальный менеджер ресурсов
YARN (Yet Another Resource Negotiator) — это система управления ресурсами кластера. Появление YARN стало поворотным моментом, превратив Apache Hadoop в многофункциональную платформу. YARN — это «мозг», который позволяет на одном и том же физическом кластере одновременно запускать задачи Apache Spark, SQL-запросы через Apache Hive и другие приложения. Именно YARN обеспечивает эффективное разделение ресурсов, изоляцию приложений и масштабируемость всего вычислительного слоя.
Эволюция обработки данных: От MapReduce к современным движкам
Подход к обработке данных — это та область, где эволюция заметна сильнее всего. Классическая модель MapReduce, хотя и была революционной, уступила место более быстрым и гибким инструментам. MapReduce — это программная модель, которая была сердцем раннего Apache Hadoop. Она разбивала большие задачи на множество мелких параллельных операций (Map) и затем объединяла их результаты (Reduce). Сегодня MapReduce практически не используется для написания нового кода из-за низкой производительности, но понимание его концепции «разделяй и властвуй» по-прежнему полезно. Apache Spark стал фактическим преемником MapReduce. Его ключевое преимущество — обработка данных в оперативной памяти (in-memory), что делает его на порядки быстрее. Важно понимать, что Spark не является конкурентом всей платформе Hadoop. Напротив, они идеально работают вместе: Spark использует YARN для управления ресурсами, а в качестве источника данных — HDFS или современные объектные хранилища.
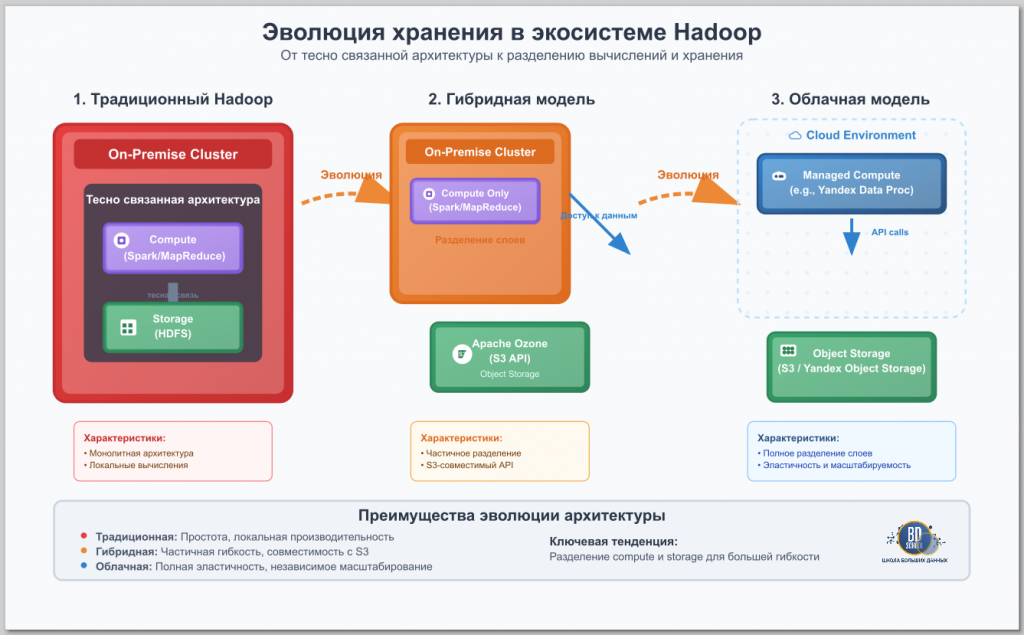
Эволюция хранения данных: От HDFS к объектным хранилищам
Главное изменение в архитектуре Big Data за последние годы — это переход от файловых систем к объектным хранилищам. Amazon S3 (Simple Storage Service) де-факто стал мировым стандартом для хранения данных в облаке. В отличие от HDFS, S3 разделяет хранение и вычисления, что дает невероятную гибкость. Экосистема Apache Hadoop прекрасно адаптировалась к этому тренду. С помощью коннектора S3A инструменты вроде Spark и Hive могут работать с данными в S3 напрямую.
Ответом сообщества Apache Hadoop на вызовы HDFS и популярность S3 стал Apache Ozone. Это современное, распределенное объектное хранилище для on-premise сред. Ozone решает ключевую проблему HDFS — неэффективную работу с миллиардами мелких файлов. Самое главное, Ozone предоставляет S3-совместимый API, что позволяет приложениям, написанным для работы с Amazon S3, без изменений работать в вашей локальной инфраструктуре.
Современные платформы и дистрибутивы Apache Hadoop
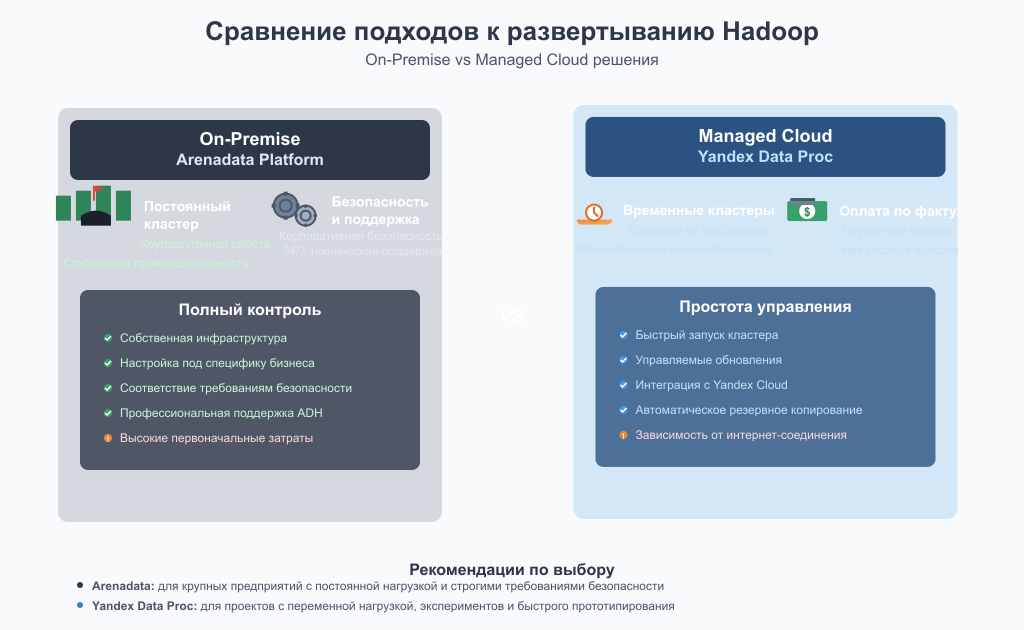
Времена, когда компании вручную устанавливали «ванильный» Apache Hadoop, практически прошли. Сегодня рынок движется в сторону управляемых облачных сервисов и корпоративных дистрибутивов.
Облачные управляемые сервисы: Yandex Data Proc — это яркий пример современного подхода к использованию экосистемы Hadoop в облаке. Это управляемый сервис, который позволяет за считанные минуты создавать временные (ephemeral) кластеры с предустановленными Spark, Hive и другими инструментами. Ключевая идея — отказ от постоянно работающих кластеров. Вы запускаете кластер под задачу, он обрабатывает данные (например, из Yandex Object Storage), а после завершения работы вы его удаляете. Такой подход снижает затраты и избавляет от сложностей администрирования.
Корпоративные дистрибутивы: Arenadata Platform для крупных организаций, строящих свои озера данных on-premise, критически важны безопасность и поддержка. Эту нишу занимают корпоративные дистрибутивы, такие как Arenadata Hadoop (ADH). Arenadata берет лучшие open-source инструменты экосистемы, тщательно тестирует их, добавляет функции enterprise-уровня (безопасность, управление) и предоставляет полноценную техническую поддержку.
Заключение: Hadoop как зрелый фундамент
Итак, Apache Hadoop в 2025 году — это уже не «серебряная пуля» для всех задач Big Data. Он прошел путь от монолитной платформы до набора фундаментальных технологий, которые лежат в основе современных архитектур данных. Его роль сегодня можно описать так:
- HDFS и YARN остаются надежной основой для построения on-premise озер данных, особенно в рамках корпоративных дистрибутивов, таких как Arenadata.
- Экосистема Hadoop полностью адаптировалась к облачной реальности, научившись работать с объектными хранилищами, такими как S3.
- Появились нативные on-premise объектные хранилища нового поколения, такие как Apache Ozone.
- Принципы Hadoop легли в основу управляемых облачных сервисов, вроде Yandex Data Proc.
Понимание архитектуры и эволюции Apache Hadoop по-прежнему является обязательным для любого специалиста по данным. Это фундамент, на котором построено все современное здание Big Data.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Референсные ссылки
- Apache Ozone Official Documentation https://ozone.apache.org/
- Arenadata Platform Documentation https://docs.arenadata.io/
- Using the S3A connector with Apache Hadoop https://hadoop.apache.org/docs/stable/hadoop-aws/tools/hadoop-aws/index.html
- Apache Spark Official Website https://spark.apache.org/