 974
974 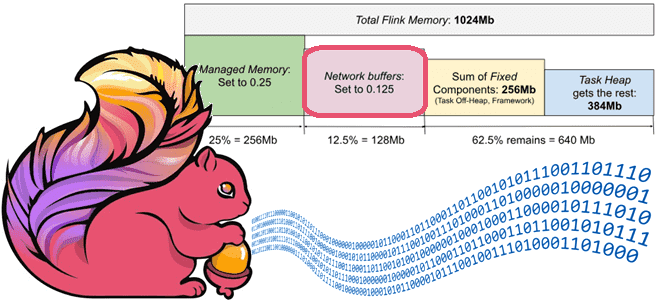
Как Apache Flink обеспечивает стабильно высокую пропускную способность потоковой обработки данных с помощью сетевых буферов и контрольных точек, каковы возможности и ограничения этих механизмов и какие конфигурации надо настроить для их эффективного использования.
Зачем Apache Flink нужны сетевые буферы
Каждая запись в Flink отправляется следующей подзадаче вместе с другими записями в сетевом буфере — наименьшей единице связи между подзадачами. Чтобы поддерживать стабильно высокую пропускную способность, Flink использует очереди сетевых буферов (текущих данных) на входной и выходной стороне процесса передачи. Каждая подзадача имеет входную очередь, ожидающую потребления данных, и выходную очередь, ожидающую отправки данных следующей подзадаче. Наличие большего объема передаваемых данных означает, что Flink может обеспечить более высокую и устойчивую пропускную способность конвейера. Однако, это приведет к увеличению времени прохождения контрольной точки. Контрольные точки во Flink могут завершиться только после того, как все подзадачи пройдут все заданные барьеры. В согласованных (выровненных) контрольных точках эти барьеры перемещаются по графу задания вместе с сетевыми буферами. Чем больше объем данных, тем дольше время распространения барьера контрольной точки. Размер невыровненных контрольных точек прямо пропорционален объему передаваемых данных, поскольку все захваченные текущие данные должны сохраняться как часть контрольной точки. Поэтому, чтобы предупредить чрезмерное увеличение сетевого буфера из-за большого объема передаваемых данных, ранее нужно было жестко задать объем буфера с учетом модели памяти Flink-приложений, которую мы подробно разбирали здесь.
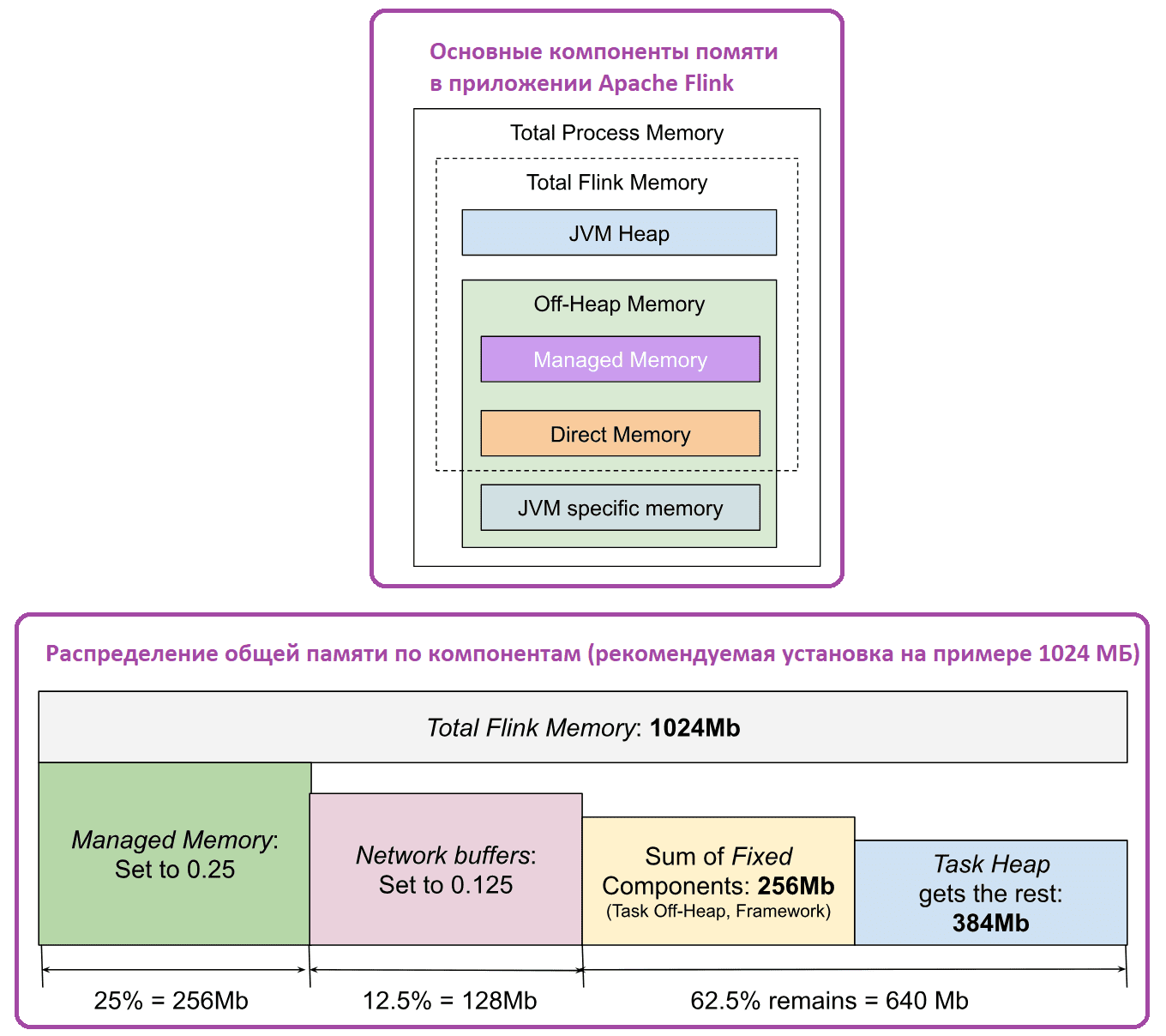
Напомним, процесс диспетчера задач Flink представляет собой типичный JVM-процесс, память которого состоит из кучи JVM и памяти вне кучи. Эти типы памяти используются Flink напрямую или JVM для своих конкретных целей, например, метапространства. У Flink есть два основных потребителя памяти: пользовательский код задач оператора заданий и сам фреймворк, потребляющий память для внутренних структур данных, сетевых буферов и пр. Пользовательский код имеет прямой доступ ко всем типам памяти: JVM Heap, Direct и Native Memory. Поэтому Flink не может контролировать его распределение и использование. Однако, существует два типа памяти вне кучи, которые используются задачами и явно контролируются Flink: управляемая память Off-Heap и сетевые буферы, которые являются частью прямой памяти JVM, выделенной для обмена данными пользовательских записей между задачами оператора.
Можно настроить распределение памяти, пропорционально разбив ее общий объем между управляемой памятью и сетевыми буферами. Оставшаяся память затем назначается куче задач, если она не задана явно, и другим фиксированным компонентам кучи JVM и компонентам вне кучи.
Как настроить размер сетевого буфера
Несмотря на эмпирические рекомендации по настройке памяти в Apache Flink, на практике бывает сложно выбрать идеальные значения для каждого компонента памяти Flink, поскольку они могут отличаться для каждого развертывания. Поэтому в версии 1.14 объем передаваемых данных автоматически корректируется до разумных значений с помощью вычисления максимально возможной пропускной способности для подзадачи и регулировки объема текущих данных так, чтобы время их потребления было равно настроенному значению. Этот механизм раздувания сетевого буфера можно включить, установив для свойства taskmanager.network.memory.buffer-debloat.enabled значение true. Целевое время использования данных в полете можно настроить, установив для свойства taskmanager.network.memory.buffer-debloat.target большое значение duration. Функция использует прошлые данные о пропускной способности для прогнозирования времени, необходимого для использования оставшихся данных.
Если прогнозы неверны, механизм может выйти из строя, когда буферизованных данных недостаточно для обеспечения полной пропускной способности или, наоборот, их слишком много. Оба случая отрицательно влияют на время распространения барьеров выровненных контрольных точек или на их размер. Если в задании непостоянная нагрузка, т.е. случаются внезапные всплески входящих записей, периодические запуски оконных агрегаций или соединений, придется настраивать следующие параметры:
- network.memory.buffer-debloat.period — минимальный период времени между пересчетом размера буфера. Чем короче период, тем быстрее время реакции механизма раздувания сетевого буфера. Но слишком короткий период повышает нагрузку на ЦП за счет интенсивных вычислений.
- network.memory.buffer-debloat.samples — количество выборок, по которым усредняются измерения пропускной способности. Частоту собираемых образцов можно регулировать с помощью taskmanager.network.memory.buffer-debloat.period. Чем меньше выборок, тем быстрее время реакции механизма раздувания, но выше вероятность внезапного скачка или падения пропускной способности. Это может привести к тому, что механизм раздувания буфера неправильно вычислит оптимальный объем передаваемых данных.
- network.memory.buffer-debloat.threshold-percentages – порог срабатывания механизма для предотвращения частого изменения размера буфера, если новый размер не сильно отличается от старого.
Для мониторинга текущего размера буфера можно отслеживать метрики estimatedTimeToConsumeBuffersMs (общее время потребления данных со всех входных каналов) и debloatedBufferSize (текущий размер буфера).
В настоящее время расчет пропускной способности и раздувание буфера происходят на уровне подзадач. Поэтому если подзадача имеет несколько разных входных данных или имеет один, но объединенный входной сигнал, раздувание буфера приводит к тому, что входные данные с низкой пропускной способностью содержат слишком много буферизованных данных в процессе передачи, а входные данные с высокой пропускной способностью имеют слишком маленькие буферы, чтобы ее поддерживать. Это особенно заметно, когда разные входы имеют совершенно разную пропускную способность.
Также текущая реализация механизма раздувания буфера ограничивается только его максимальным используемым размером, однако фактический размер буфера и их количество остаются неизменными. Поэтому механизм раздувания не снизит потребление заданием памяти: придется вручную уменьшать количество или размер буферов.
В настоящее время механизм раздувания буфера может работать неправильно при высоком параллелизме (более ~200) и конфигурации по умолчанию. Если наблюдается снижение пропускной способности или превышение ожидаемого времени создания контрольных точек, рекомендуется увеличить количество плавающих буферов (конфигурация taskmanager.network.memory.floating-buffers-per-gate) со значения по умолчанию до числа, равного параллелизму. Фактическое значение параллелизма, из-за которого возникает проблема, отличается от задания к заданию, но обычно оно больше нескольких сотен.
Узнайте больше про использование Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

