 712
712 
Сегодня рассмотрим, как развернуть модель машинного обучения в конвейере Apache Kafka, используя потоковый API технологии удаленного вызова процедур от Google под названием gRPC и сервер ML-моделей TensorFlow Serving.
Краткий ликбез по gRPC
Напомним, gRPC – это технология интеграции систем, включая клиентский и серверный компоненты, основанная на удаленном вызове процедур в редакции 2015 года от Google. Как и многие RPC-технологии, gRPC предполагает определение сервиса и его методов, которые можно вызывать удаленно, с их параметрами и типами возвращаемых значений. По умолчанию gRPC использует бинарный формат Protobuf в качестве языка определения интерфейса (IDL) для описания интерфейса сервиса и структуры сообщений полезной нагрузки. В качестве транспортного протокола gRPC использует HTTP/2 и предоставляет несколько API:
- унарные RPC, когда клиент отправляет один запрос на сервер и получает один ответ, как в типовых синхронных веб-сервисах;
- серверные потоковые RPC, когда клиент отправляет запрос на сервер и получает поток для чтения последовательности сообщений. Клиент читает данные из возвращенного потока до тех пор, пока не останется сообщений. Технология gRPC гарантирует упорядочение сообщений в рамках отдельного RPC-вызова.
- клиентские потоковые RPC, когда клиент записывает последовательность сообщений и отправляет их на сервер, используя предоставленный поток. Как только клиент закончил писать сообщения, он ждет, пока сервер прочитает их и вернет свой ответ. За порядок сообщений в рамках отдельного RPC-вызова отвечает сама технология gRPC.
- двунаправленные потоковые RPC, когда обе стороны (клиент и сервер) отправляют последовательность сообщений, используя поток чтения-записи. Два потока работают независимо, поэтому клиенты и серверы могут читать и записывать в любом порядке. Например, сервер может дождаться получения всех клиентских сообщений, прежде чем отправлять ответы, или попеременно читать сообщение, а затем отвечать, или комбинировать операции чтения и записи каким-то другим образом. Порядок сообщений в каждом потоке сохраняется.
Начиная с определения службы в файле .proto, gRPC предоставляет подключаемые модули компилятора формата protobuf, которые генерируют клиентский и серверный код. Пользователи gRPC обычно вызывают эти API на стороне клиента и реализуют соответствующий API на стороне сервера. В отличие от других стилей веб-API, таких как REST, SOAP и GraphQL, gRPC-сервис невозможно напрямую вызвать из браузера: необходимо разрабатывать клиентское приложение, которое будет обращаться к серверу, используя любой язык разработки.
На бэкенде сервер реализует методы, объявленные службой, и запускает сервер gRPC для обработки клиентских вызовов. Инфраструктура gRPC декодирует входящие запросы, выполняет методы службы и кодирует ответы службы. На стороне клиента у клиента есть локальный stub-объект, который реализует те же методы, что и сервис. Клиент может просто вызывать эти методы для локального объекта. Эти методы заключают параметры для вызова в соответствующий тип protobuf-сообщения, отправляют запросы на сервер и возвращают protobuf-ответы сервера.
Канал gRPC обеспечивает подключение к gRPC-серверу на указанном узле и порту. Он используется при создании клиентского stub-объекта. Клиенты могут указать аргументы канала, чтобы изменить поведение gRPC по умолчанию, например, включить или выключить сжатие сообщений. Канал имеет состояние, например, подключен и свободен.
Таким образом, gRPC является очень мощной технологией и подходит для потоковой обработки данных благодаря наличию настраиваемых стриминговых API. Поэтому потенциально ее можно использовать в проектах машинного обучения, которые должны переобучаться в режиме реального времени. Как это сделать, рассмотрим далее.
MLOps с Kafka Streams: 3 способа развернуть ML-модель
Предположим, ML-модели разрабатываются и поддерживаются с помощью MLOps-фреймфорка TensorFlow Serving — гибкой, высокопроизводительной системы обслуживания моделей машинного обучения для производственных сред. TensorFlow Serving упрощает развертывание новых алгоритмов и экспериментов, сохраняя исходную архитектуру сервера и API. TensorFlow Serving обеспечивает готовую интеграцию с моделями TensorFlow, но может быть расширен для обслуживания других типов моделей и данных.
Пусть за обработку в реальном времени входного потока данных, на которых ML-модель должна выполнить прогноз, отвечает приложение Kafka Streams. Сервер ML-модели, развернутый в TensorFlow Serving, взаимодействует с приложением Kafka Streams через HTTP или gRPC.
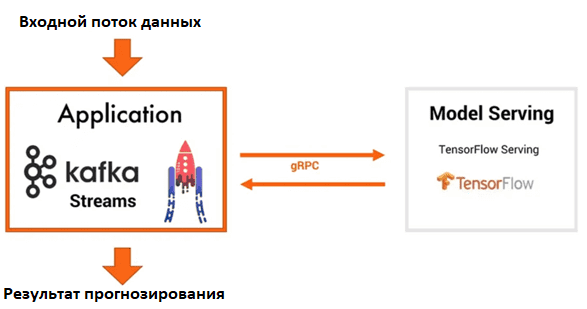
Такой способ развертывания может обслуживать несколько ML-моделей или несколько версий одного алгоритма, позволяя управлять ими без изменения кода клиента и поддерживая оптимальную скорость обработки данных. Однако, перехват сетевого исключения между приложением Kafka Streams и MLOps-сервером TensorFlow Serving должен обрабатываться в потоковых приложениях Kafka Stream, что не очень просто, поскольку может включать вызов другого приложения.
Альтернативой является потоковая обработка со встроенными ML-моделями. Вместо внешнего использования TensorFlow-сервера ML-моделей и обращения к нему с использованием gRPC API можно встроить модель машинного обучения непосредственно в приложение Kafka Streams или KSQL. Также можно клиентский API Kafka, написав собственный код на Java, Scala, Python или Go.
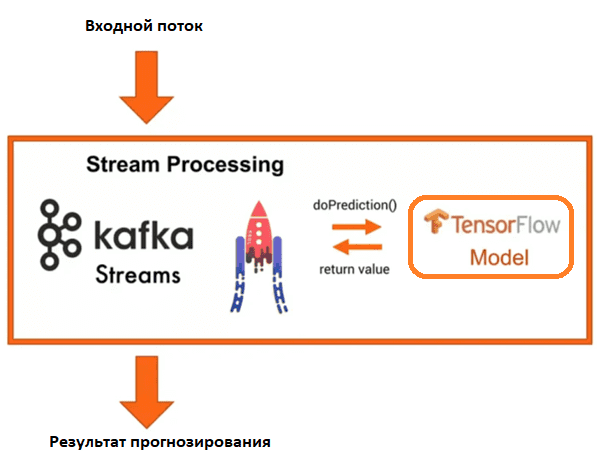
В этом варианте производительность ML-системы будет выше из-за отсутствия обращения к внешним системам. Но потребление памяти в этом случае сильно возрастает, что может увеличить задержку обработки данных. Также необходимо решить традиционные MLOps-вопросы обновления модели, управление версиями и их A/B-тестирования для выбора наилучшей модели. Для этого можно использовать контейнеризацию, запуская для каждой ML-модели новый под Kubernetes. Перенаправление трафика при этом будет осуществляться самой инфраструктурой Kubernetes, без обновления Docker-контейнера с помощью замены весов ML-модели. Публиковать и использовать модели машинного обучения можно через топики Kafka, а благодаря облачному характеру Kubernetes развертывание будет происходить в реальном времени изолировано и масштабируемо. Если необходимо использовать функции сервера ML-моделей, включая их A/B-тестирование, в облаке, пригодится шаблон sidecar, который включает обслуживание TensorFlow в том же поде и использованием RPC-вызовов.
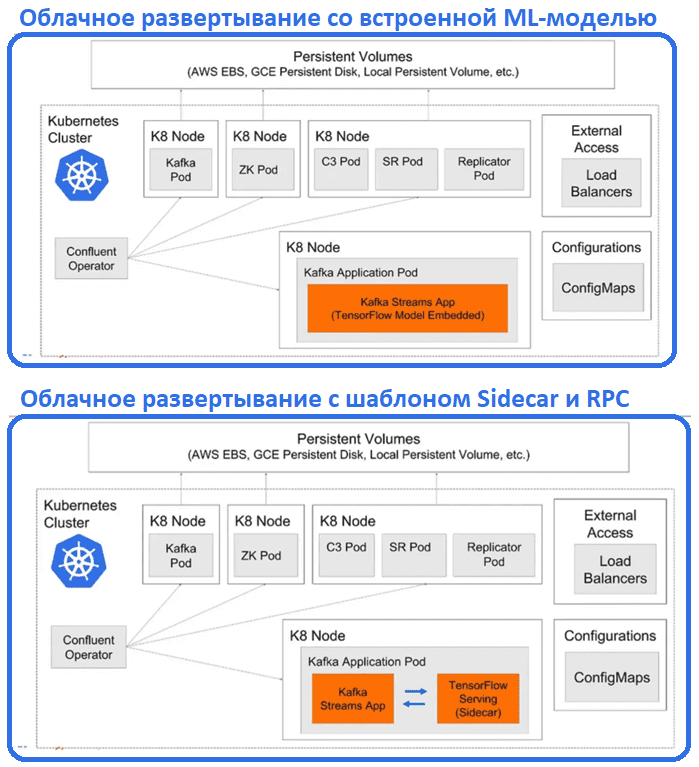
Наконец, можно совместить оба рассмотренных подхода, объединив gRPC-сервер потоковой передачи с приложениями Kafka Streams. Это позволяет разделить задачи, предоставляя сервер ML-модели со всеми нужными функциями без использования RPC-вызовов через HTTP или gRPC. Вместо этого сервер ML-моделей будет взаимодействовать с клиентским приложением через собственный протокол Kafka и топики этой распределенной платформы потоковой передачи событий.
В заключение отметим, что помимо разработки ML-модели еще необходимо организовать MLOps-инфраструктуру для ее полноценного сопровождения. Как это сделать, читайте в нашей новой статье.
Как применять эти и другие средства MLOps в проектах аналитики больших данных и машинного обучения, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Разработка и внедрение ML-решений
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

