 1119
1119 
Чтобы сделать наши курсы для DevOps-инженеров и специалистов по Machine Learning еще более полезными, сегодня рассмотрим, как автоматизировать развертывание и обслуживание ML-моделей согласно концепции MLOps с помощью GitLab CI/CD, BentoML, Yatai, MLflow и Kubeflow.
BentoML для CI в MLOPS
При развертывании ML-модели необходимо учитывать следующие аспекты:
- как была построена модель и что влияет на ее обслуживание;
- как будет использоваться обслуживаемая модель;
- как масштабировать рабочие нагрузки;
- как контролировать сервис и реализовать логирование;
- как модель может быть переобучена и автоматически развернута.
Концепция MLOps предполагает целостное решение всех этих вопросов через использование специальных открытых и проприетаных инструментов, которые позволяют выстроить сквозной конвейер разработки, оразвертывания и поддержки эксплуатации системы машинного обучения. К таким инструментам относятся Kubeflow, MLflow и BentoML. О том, что представляет собой Kubeflow и MLflow, мы писали здесь.
А BentoML – это открытая библиотека для быстрого создания MVP систем машинного обучения. Она упрощает создание API методов для доступа к обученной ML-модели и совместима со всеми крупными фреймворками: Tensorflow, Keras, PyTorch, XGBoost, scikit-learn и fastai. BentoML поддерживает адаптивную микропакетную обработку данных, а также предоставляет функции управления моделью и ее развертывания. Поэтому BentoML отлично реализует идеи MLOps, позволяя разработчикам моделей машинного обучения использовать лучшие практики DevOps.
Специалисты по Data Science и инженеры Machine Learning используют BentoML для ускорения и стандартизации процесса запуска моделей в производство, позволяя создавать масштабируемые и высокопроизводительные ML-сервисы. Библиотека поддерживает непрерывное развертывание, мониторинг и сопровождение сервисов в производственной среде.
Впрочем, перед автоматизированным развертыванием модели необходимо автоматизировать ее обучение. Это можно сделать, реализовав конвейер с использованием Kubeflow, что гарантирует повторяемость и воспроизводимость обучения ML-модели. Как только модель успешно обучена, она регистрируется в реестре моделей с помощью MLFlow. Также автоматически регистрируются такие показатели работы ML-модели, в частности, точность. Благодаря регистрации модели в реестре MLflow к ней можно будет обратиться по уникальному URL-адресу, например:
model = mlflow.sklearn.load_model(f"runs:/{run_id}/model")
Здесь run_id — это уникальный идентификатор, к примеру, 8aa4630a023c4e94b22c6e738127ee7a. Он будет передаваться в инструмент непрерывного развертывания (CI, Continuous Integration), который запускается после успешного обучения модели. Используя GitLab CI/CD, можно запустить задание CI с помощью инструмента командной строки curl, передав HTTP-методом POST идентификатор запуска MLflow в качестве переменной среды при выполнении задания:
curl --request POST \ --form token=<token> \ --form ref=<branch> \ --form "variables[MLFLOW_RUN_ID]=8aa4630a023c4e94b22c6e738127ee7a" \ "https://gitlab.com/api/v4/projects/<project-id>/trigger/pipeline"
Это можно быстро превратить в код Python используя один из многочисленных конвертеров, например, https://curlconverter.com/, чтобы быстро создать компонент Kubeflow:
def trigger_ci(mlflow_run_id: str, branch: str = "main"):
import requests
files = {
"token": (None, "your-token-here"),
"ref": (None, branch),
"variables[MLFLOW_RUN_ID]": (None, mlflow_run_id),
}
response = requests.post(
"https://gitlab.com/api/v4/projects/project-id/trigger/pipeline", files=files
)
return response.text
Чтобы развернуть ML-модель, упакованную в RESTfull API решение с помощью BentoML, в Kubernetes, можно воспользоваться сервисом Yatai, который обеспечивает развертывание, сопровождение и масштабирование BentoML-решений в Kubernetes. Как это сделать, рассмотрим далее.
Автоматизация развертывания Bento-службы в Yatai
Следующий YAML-файл .gitlabci.yml содержит все необходимые команды BentoML:
bentoml-build-and-push:
image: "python:3.8"
stage: bentoml
script:
- apt-get update -y
- apt-get install -y jq
- pip install --upgrade pip
- pip install -r $CI_PROJECT_DIR/bento/requirements.txt
- export BENTO_MODEL="aml-case"
- python $CI_PROJECT_DIR/bento/save_model_to_bentoml.py --model_name ${BENTO_MODEL} --run_id $MLFLOW_RUN_ID
- bentoml build -f $CI_PROJECT_DIR/bento/bentofile.yaml
- bentoml yatai login --api-token $YATAI_API_TOKEN --endpoint http://yatai.yatai-system.svc.cluster.local
- export BENTO_DEPLOYMENT_NAME="${BENTO_MODEL}-${CI_COMMIT_SHORT_SHA}"
- bentoml push ${BENTO_MODEL}
- export BENTO_MODEL_AND_TAG=`bentoml list ${BENTO_MODEL} -o json | jq '.[0]["tag"]'`
- cp $CI_PROJECT_DIR/bento/deployment.yaml ./deployment.yaml
- 'sed -i "s/BENTO_MODEL_AND_TAG/$BENTO_MODEL_AND_TAG/g" ./deployment.yaml'
- 'sed -i "s/BENTO_DEPLOYMENT_NAME/$BENTO_DEPLOYMENT_NAME/g" ./deployment.yaml'
- 'sed -i "s/BENTO_MODEL/$BENTO_MODEL/g" ./deployment.yaml'
artifacts:
paths:
- deployment.yaml
only:
- triggers
bentoml-deploy:
image: bitnami/kubectl:latest
stage: bentoml
script:
- kubectl create -f deployment.yaml
needs: ["bentoml-build-and-push"]
only:
- triggers
Первые четыре команды устанавливают jq, необходимый для работы с JSON, и зависимости для службы BentoML, включая scikit-learn и MLflow. Команда save_model_to_bentoml.py сохраняет ML-модель, с указанием ее имени и идентификатором run_id, который ранее передавался при ручном запуске CI. Код регистрации модели в реестре BentoML выглядит следующим образом:
def main(model_name: str, run_id: str):
model = mlflow.sklearn.load_model(f"runs:/{run_id}/model")
saved_model = bentoml.picklable_model.save_model(
name=model_name, model=model, signatures={"predict_proba": {"batchable": True}}
)
runner = bentoml.picklable_model.get(f"{model_name}:latest").to_runner()
runner.init_local()
EXAMPLE_INPUT = np.random.rand(4, 24)
data = pd.DataFrame(EXAMPLE_INPUT)
predicted_probs = [x[1] for x in model.predict_proba(data)]
print(predicted_probs)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--model_name")
parser.add_argument("--run_id")
args = parser.parse_args()
main(model_name=args.model_name, run_id=args.run_id)
Первые две строки этого скрипта загружают модель из MLflow, используя идентификатор run_id, а затем сохраняют ее в реестре моделей BentoML с ранее переданным именем. После того, как модель зарегистрирована в реестре BentoML, можно начать создание службы Bento. Остальная часть скрипта выполняет проверку работоспособности, удостоверяясь, что загруженная модель в BentoML может работать с некоторыми случайными входными данными. YAML-файл службы Bento довольно прост:
model = mlflow.sklearn.load_model(f"runs:/{run_id}/model")
saved_model = bentoml.picklable_model.save_model(
name=model_name,
model=model,
signatures={"predict_proba": {"batchable": True}})
Команда bentoml build -f $CI_PROJECT_DIR/bento/bentofile.yaml создает службу Bento, которая упаковывает все в единый артефакт, чтобы использовать его для развертывания ML-модели. Сервис Yatai играет роль центрального хранилища Bento-моделей. Перед развертыванием в Yatai, нужно войти в кластер с токеном API:
bentoml yatai login --api-token $YATAI_API_TOKEN --endpoint http://yatai.yatai-system.svc.cluster.local
И выполнить команду проталкивания Bento-службы в Yatai:
bentoml push ${BENTO_MODEL}
В случае успеха Yatai приступит к контейнеризации Bento, а пока это происходит, можно подготовить развертывание Bento, подготовив YAML-файл deployment.yaml:
apiVersion: serving.yatai.ai/v1alpha2
kind: BentoDeployment
metadata:
name: BENTO_DEPLOYMENT_NAME
namespace: ds-models
spec:
bento_tag: BENTO_MODEL_AND_TAG
ingress:
enabled: true
resources:
limits:
cpu: "1"
memory: "1Gi"
requests:
cpu: "500m"
memory: "512m"
runners:
- name: BENTO_MODEL
resources:
limits:
cpu: "1"
memory: "1Gi"
requests:
cpu: "500m"
memory: "512m"
Чтобы упростить управление развертываниями, их можно называть по имени ML-модели и версии Git. Это позволит сопоставить, какое развертывание было получено из какой фиксации Git. Затем следует создать образ Docker, который будет использовать Bento-развертывание с нужными sed и jq:
export BENTO_DEPLOYMENT_NAME="${BENTO_MODEL}-${CI_COMMIT_SHORT_SHA}"
export BENTO_MODEL_AND_TAG=`bentoml list ${BENTO_MODEL} -o json | jq '.[0]["tag"]'`
cp $CI_PROJECT_DIR/bento/deployment.yaml ./deployment.yaml
'sed -i "s/BENTO_MODEL_AND_TAG/$BENTO_MODEL_AND_TAG/g" ./deployment.yaml'
'sed -i "s/BENTO_DEPLOYMENT_NAME/$BENTO_DEPLOYMENT_NAME/g" ./deployment.yaml'
'sed -i "s/BENTO_MODEL/$BENTO_MODEL/g" ./deployment.yaml'
Команда cp $CI_PROJECT_DIR/bento/deployment.yaml ./deployment.yaml создает копию файла deployment.yaml, который будет передаваться на следующий шаг CI-конвейера. Чтобы завершить развертывания Bento, осталось выполнить команду ее создания в kubectl:
bentoml-deploy:
image: bitnami/kubectl:latest
stage: bentoml
script:
- kubectl create -f deployment.yaml
needs: ["bentoml-build-and-push"]
only:
- triggers
По завершении развертывания оно отобразится в пользовательском интерфейсе Yatai, где также можно выполнять обслуживание, мониторинг и ведение журнала. При этом мониторинг и ведение журнала нужно сперва включить вручную:
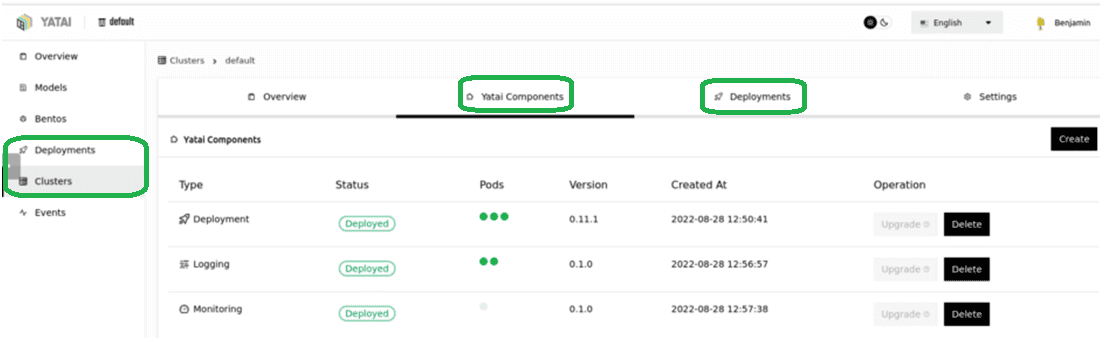
После этого каждая развертываемая вами модель будет сопровождаться мониторингом через Grafana и ведением журнала через Loki. А используя URL-адрес конечной точки развернутой ML-модели, можно перейти в веб-инструмент тестирования REST API Swagger, чтобы проверить ее работу:
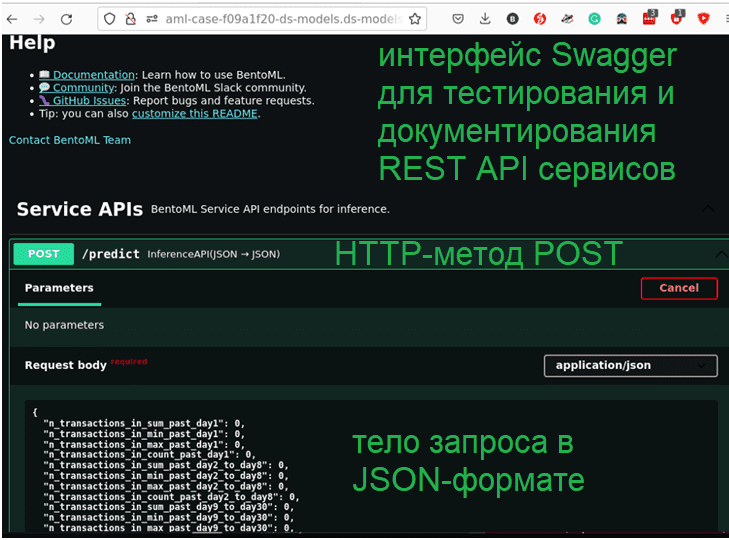
В заключение отметим, что все рассмотренные MLOPS-инструменты также поддерживают переобучение моделей Machine Learning. В частности, можно просто запланировать периодический запуск конвейера Kubeflow по расписанию. Это позволит не ждать, пока сработают предупреждения об обнаружении дрейфа данных или модели, а начать ее переобучение, когда для этого будут доступны свежие данные. Для этого нужны метрики оценки, чтобы сравнить новые модели с теми, которые работают в производстве. Сделать это поможет компонент Trigger CI в GitLab. Альтернативой является простое переключение службы в Ingress на модель с наилучшей производительностью. Напомним, Ingress — объект API, который управляет внешним доступом к объектам Service в проекте Kubernetes, он идентифицирует маршруты HTTP и HTTPS из внешней среды для объектов Service проекта. Маршрутизация трафика контролируется правилами, определенными для ресурса Ingress.
Например, если имеется следующий вход:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: aml
namespace: ds-models
spec:
rules:
- host: aml-case.ds-models.dev.jago.data
http:
paths:
- backend:
service:
name: "aml-123"
port:
number: 3000
path: /
pathType: ImplementationSpecific
Ingress указывает на службу aml-123, которую можно заменить на другую вручную или с помощью триггера CI.
Таким образом, Kubeflow, MLflow и BentoML с Yatai позволяют автоматизировать развертывание и переобучение модели Machine Learning в любой среде. Чем BentoML отличается от другого популярного фреймворка FastAPI и что лучше для MLOps, читайте в нашей новой статье.
Как применять эти и другие современные инструменты MLOps в проектах аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

