 789
789 
Содержание
- Данные без контекста - это просто шум
- Анатомия управления метаданных: из чего состоит "паспорт" данных
- Бизнес-метаданные (Business Metadata)
- Технические метаданные (Technical Metadata)
- Операционные метаданные (Operational Metadata)
- Современный Data Catalog: операционная система для управления метаданными
- От пассивного репозитория к активной платформе
- Data Lineage — "Святой Грааль" метаданных
- Active vs. Passive Metadata — метаданные начинают действовать
- Кейс из реальной жизни: как банк ускорил работу Data Scientist'ов
- Заключение и анонс
- Рекомендованные материалы
Данные без контекста — это просто шум
Представьте, что вы нашли старую пиратскую карту. На ней есть крестик, обозначающий сокровище. Но сама карта порвана, условные обозначения стерты, а масштаб неизвестен. Что вы будете делать с этой информацией? Ничего. Без контекста, без дополнительных данных о данных, эта карта — просто бесполезный кусок пергамента.
То же самое происходит в мире корпоративных данных. Число «120» в колонке amount таблицы orders — это тот самый крестик на карте. Оно абсолютно бессмысленно, пока мы не получим метаданные, которые дадут на него ответ.
- Это 120 рублей, долларов или тугриков?
- Эта сумма включает НДС или нет?
- Это сумма всего заказа или одной позиции?
- Данные в этой таблице обновляются раз в сутки или в реальном времени?
- Кто отвечает за качество и достоверность этих данных?
Управление метаданными (Metadata Management) — это не скучная техническая рутина по «заполнению документации». Это фундаментальный процесс создания той самой «легенды» для нашей карты данных, который превращает бессмысленный шум цифр и букв в надежный и понятный актив.
Отсутствие управления метаданными — первопричина многих корпоративных бед.
- Новый сотрудник тратит месяцы, чтобы просто разобраться, где лежат нужные ему данные и что они означают, вместо того чтобы приносить пользу.
- Два отдела до хрипоты спорят о смысле показателя «Активный клиент», потому что у каждого свое, нигде не зафиксированное определение.
- Аналитик строит критически важный отчет на данных из таблицы с названием orders_final_final_2, не зная, что она давно заброшена, а все актуальные данные лежат в sales_mart.
В этой статье мы разберемся, из чего состоят метаданные, почему современные Data Catalog стали «операционной системой» для них и как новая парадигма «активных метаданных» меняет правила игры.
Анатомия управления метаданных: из чего состоит «паспорт» данных
Метаданные, или «данные о данных», можно условно разделить на три большие категории, каждая из которых предназначена для своей аудитории.
Бизнес-метаданные (Business Metadata)
Это информация о данных, изложенная на языке, понятном бизнес-пользователям. Это тот самый контекст, который превращает технические таблицы в бизнес-сущности. Что это включает?
- Определения бизнес-терминов. Что мы в компании понимаем под «валовой прибылью», «новым клиентом» или «оттоком». Это содержимое Бизнес-глоссария.
- Роли и ответственности. Кто является Владельцем (Data Owner) этих данных? Кто Стюард (Data Steward), к которому можно прийти с вопросом?
- Правила качества и политики. Каким правилам должны соответствовать эти данные? Каков их уровень конфиденциальности?
- Классификация и теги. Являются ли эти данные персональными (PII)? Относятся ли они к финансовой отчетности?
Бизнес-метаданные — это мост между миром IT и миром бизнеса.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Технические метаданные (Technical Metadata)
Это информация о физической структуре, происхождении и обработке данных. Это «рентгеновский снимок» наших данных, понятный инженерам и разработчикам. Сюда мы относим:
- Схемы баз данных. Названия таблиц, столбцов, их типы данных (VARCHAR, INT, TIMESTAMP).
- Модели данных. ER-диаграммы.
- Информация о происхождении данных (Data Lineage). Как данные попали в эту таблицу? Из каких систем-источников они пришли и через какие ETL/ELT-скрипты прошли?
- Код трансформаций. Сами SQL-скрипты или код на Python/Java, который преобразует данные.
Операционные метаданные (Operational Metadata)
Это информация о том, как данные «живут» и используются во времени. Это «медицинская карта» наших данных.
- Статистика выполнения процессов. Когда в последний раз обновлялась эта таблица? Успешно ли прошел ETL-джоб?
- Профили данных. Какое минимальное и максимальное значение в этом столбце? Сколько в нем пустых значений (NULL)?
- Статистика использования. Как часто запрашивается эта таблица? Какие пользователи или дашборды ее используют?
- Логи доступа. Кто и когда пытался получить доступ к этим данным?
Современный Data Catalog: операционная система для управления метаданными
Долгое время управление метаданными было болью. Вся информация хранилась в разрозненных Excel-файлах, Confluence или просто в головах «старожилов» компании. Это было неэффективно и ненадежно.
От пассивного репозитория к активной платформе
Революцию в этой области произвели Каталоги Данных (Data Catalogs). Но важно понимать их эволюцию.
- Старый подход (Пассивный каталог). Это был просто централизованный справочник, который нужно было заполнять вручную. Это было трудоемко, и информация в нем быстро устаревала.
- Современный подход (Активный каталог). Современные Data Catalog — это умные, живые платформы. Они сами, с помощью специальных коннекторов, «ходят» по всем вашим источникам данных (базам, озерам, BI-системам), автоматически сканируют их и собирают технические и операционные метаданные. Задача человека (Стюарда данных) — обогатить этот автоматически собранный скелет бизнес-смыслом.
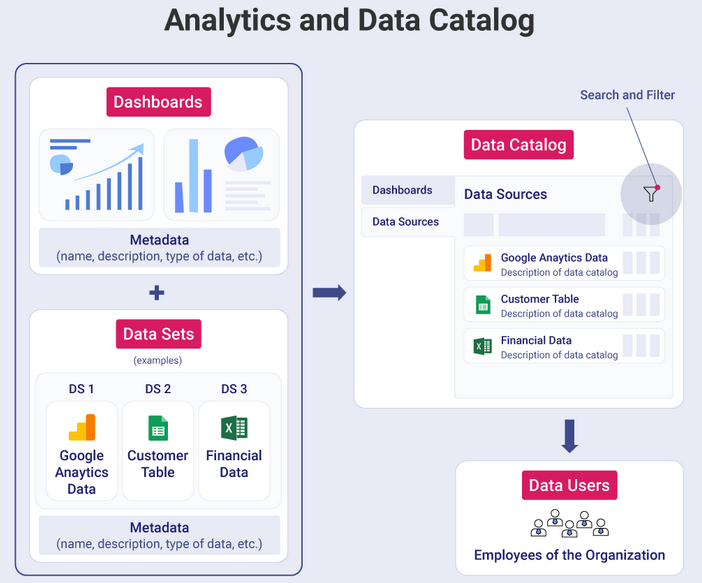
Примеры инструментов: Юниверс DG, Alation, Collibra, Informatica EDC, open-source Amundsen, OpenMetadata.
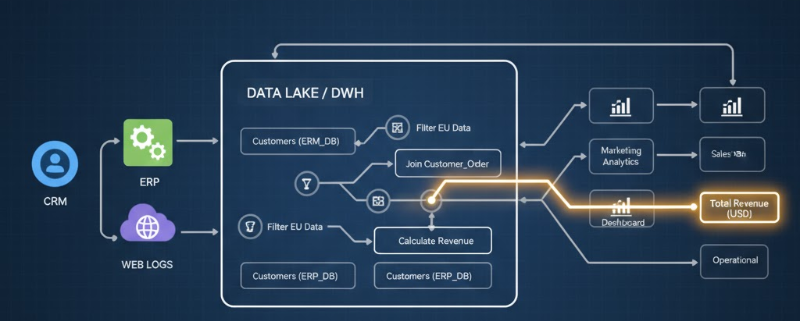
Data Lineage — «Святой Грааль» метаданных
Одной из самых ценных функций современных каталогов является автоматическое построение Data Lineage — визуального графа, показывающего полный путь данных от их рождения до использования в отчете. Это не просто красивая картинка. Это мощнейший аналитический инструмент.
- Анализ влияния (Impact Analysis). Инженер хочет переименовать столбец в системе-источнике. Один клик в каталоге — и он видит, что это изменение «сломает» 5 ETL-процессов и 28 критически важных дашбордов. Катастрофа предотвращена.
- Поиск первопричины (Root Cause Analysis). Финансовый директор видит в отчете неверную цифру. Аналитик открывает lineage этого показателя и, как по ниточке, распутывает весь клубок трансформаций до самого источника, быстро находя, на каком этапе произошла ошибка.
- Соответствие регуляторам (Compliance). Аудитор или Центробанк спрашивает: «Докажите, откуда вы взяли эту цифру в отчете?». Вы просто показываете ему автоматически сгенерированный и всегда актуальный граф происхождения данных.
Active vs. Passive Metadata — метаданные начинают действовать
Новейшая парадигма развития каталогов — это активные метаданные. Суть в том, что каталог перестает быть просто системой для чтения. Он начинает сам инициировать действия в других системах.
- Пассивные метаданные (старый мир): Аналитик видит в каталоге, что данные в таблице помечены как «конфиденциальные». Он идет в другую систему и вручную настраивает права доступа.
- Активные метаданные (новый мир): Каталог «видит», что данные помечены как «конфиденциальные». Он сам через API отправляет команду в систему управления доступом, чтобы автоматически применить нужные политики.
Это превращает каталог из «Википедии» в настоящий «центр управления полетами» для всей экосистемы данных. Примеры:
- Каталог видит, что к данным давно не обращались, и автоматически инициирует их перенос в холодный архив.
- Каталог знает стоимость и сложность запросов и может предупреждать пользователей, если они пытаются запустить слишком «дорогой» запрос.
- Каталог видит, что качество данных в источнике резко упало, и может автоматически остановить ETL-процесс, чтобы «грязные» данные не попали в хранилище.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Кейс из реальной жизни: как банк ускорил работу Data Scientist’ов
Давайте посмотрим, как это работает на практике. Допустим у нас есть проблема.
В крупном розничном банке была создана сильная команда Data Science для построения моделей машинного обучения (скоринг, отток, персональные предложения). Но команда столкнулась с неожиданной проблемой. По их собственным оценкам, они тратили до 80% своего времени не на математику и программирование, а на поиск и подготовку данных.
Процесс выглядел как квест.
- Найти в компании человека, который вообще знает, где лежат нужные данные.
- Договориться с владельцем этой системы, чтобы он разрешил доступ.
- Написать официальную заявку в IT-отдел на выгрузку.
- Подождать несколько недель.
- Получить данные и понять, что это не совсем то, что нужно, потому что никто не объяснил смысл полей.
- Начать все сначала.
Продуктивность команды была крайне низкой, а Data Scientist’ы были демотивированы.
Банк принял стратегическое решение внедрить современный Data Catalog (в их случае это был Alation) и сделать его единой «точкой входа» для всех, кто работает с данными.
- Автоматическое сканирование. Каталог был подключен ко всем ключевым системам — DWH, Data Lake, BI-платформе. Он автоматически просканировал тысячи таблиц и собрал весь технический и операционный скелет метаданных.
- Запуск программы стюардшипа. Была запущена программа по назначению Data Stewards в каждом бизнес-подразделении. Их задачей было обогатить каталог бизнес-смыслом — написать понятные определения для ключевых таблиц и полей, проставить оценки качества.
- Социализация и геймификация. Каталог стал не просто справочником, а своего рода «социальной сетью для данных». Пользователи могли ставить оценки («лайки») качественным наборам данных, писать комментарии, задавать вопросы напрямую стюардам и видеть, какие данные наиболее популярны у их коллег.
В результате мы получаем
- Скорость. Время на поиск, понимание и оценку пригодности данных для новой ML-модели сократилось с нескольких недель до 1-2 дней.
- Продуктивность. Команда Data Science смогла увеличить количество создаваемых и внедряемых моделей более чем в 2 раза за год.
- Доверие. Наличие прозрачного Data Lineage и бизнес-определений резко повысило доверие к данным во всей организации.
- Compliance. Банк смог автоматически генерировать отчеты по происхождению данных для регулятора, что сэкономило тысячи человеко-часов юридического и IT-департаментов.
Заключение и анонс
Управление метаданными — это не опция, а абсолютная необходимость для любой компании, которая хочет принимать решения на основе данных. Без метаданных наши озера данных превращаются в болота, а хранилища — в свалки. Данные без контекста не просто бесполезны, они опасны.
Современные Data Catalog, которые автоматически собирают информацию, визуализируют Data Lineage и обогащаются бизнес-смыслом, становятся тем самым «Google-поиском» и «Википедией», без которых невозможна эффективная работа с данными в масштабах предприятия. А новая парадигма активных метаданных и вовсе превращает каталог в «мозг» и центральную нервную систему всей data-платформы.
Понимание того, как архитектурные решения влияют на сбор и использование метаданных для эффективного Governance, как спроектировать Data Lineage и как выбрать правильный Data Catalog — это неотъемлемая часть знаний современного архитектора данных, которую невозможно получить без разбора реальных кейсов и практического опыта.
У нас есть карта наших данных. Но насколько она точна? Что, если на ней обозначены города, которых не существует, или дороги, ведущие в никуда? В следующей статье мы поговорим о самой болезненной теме — Управлении качеством данных (Data Quality).
Рекомендованные материалы
- DAMA-DMBOK (Глава 11 Metadata Management).
- The Enterprise Big Data Lake by A. Gorelik (главы про Data Catalog и Discovery).
- Блоги компаний Alation, Collibra, и open-source проектов OpenMetadata, Amundsen.
- Статьи от Gartner

