 1115
1115 
Содержание
Сегодня поговорим про движки хранения больших данных в экосистеме Apache Hadoop и рассмотрим, что такое Kudu, каковы особенности применения, достоинства и недостатки этой колоночной NoSQL-СУБД. Также читайте в нашей статье, как Kudu связан с Impala, Spark и другими Big Data фреймворками.
Что такое Apache Kudu и где это используется
Распределенная файловая система для Apache Hadoop, HDFS отлично подходит для эффективного хранения больших данных, обеспечивая надежность записи с высокой степенью сжатия. Однако, данные в HDFS не подлежат модификации, а из-за архитектурных особенностей этого движка он не подходит для быстрой аналитики Big Data в реальном времени. Колоночная СУБД Apache HBase, работающая поверх HDFS, характеризуется противоположными свойствами: она позволяет довольно оперативно искать данные в режиме real-time, однако долго сканирует записанные объемы информации [1].
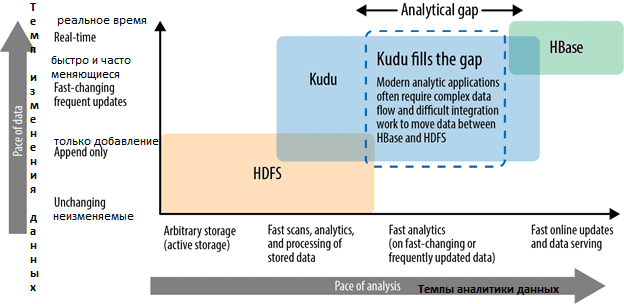
Для устранения этих недостатков компания Cloudera в 2015 году начала внутренний проект по созданию новой колоночной СУБД для оперативной аналитики быстро меняющихся больших данных. В сентябре 2016 года 1-ая версия Kudu с открытым исходным кодом была выпущена под лицензией Apache [2].
Apache Kudu предназначен для работы с быстро меняющимися данными, предоставляя комбинацию быстрых вставок/обновлений и эффективного столбцового сканирования для аналитики в реальном времени на одном уровне хранения. Поэтому Kudu хорошо подходит для использования в качестве места для хранения данных, которые необходимо немедленно запрашивать. Также Kudu поддерживает обновление и удаление строк в режиме real-time, что позволяет исправлять данные и работать с их «опозданием» [3].
Таким образом, основными областями применения Apache Kudu считаются следующие варианты Big Data систем [4]:
- приложения для генерации отчетов, когда поступающие данные должны быть немедленно доступны для конечных пользователей;
- анализ временных рядов, где требуется одновременно поддерживать общие запросы к большим объемам исторических данных и быструю обработку подробных обращений к отдельной сущности;
- прогнозирование будущего для принятия решений в режиме реального времени с периодическим обновлением прогнозной модели на основе всех исторических данных.
Особенности архитектуры и использования
При том что Apache Kudu является NoSQL-СУБД для Apache Hadoop, в отличие от других движков работы с данными в этой экосистеме, она не использует HDFS для хранения информации даже косвенно, записывая файлы в ext4 или XFS. Репликация обеспечивает сохранность данных при отказе отдельных узлов кластера, который состоит из двух типов серверов [1]:
- master – главный узел, отвечающий за управление метаданными и координацию между узлами;
- tablet, которые разбивают данные на логические разделы (tablets) – сегменты таблиц.
При этом с точки зрения пользователя данные в Кudu хранятся в таблицах с четко заданной структурой, что нетипично для NoSQL-СУБД. Пользователь должен задать столбцы, их типы, определить первичные ключи и политику разбиения на разделы. Таким образом, в терминах CAP-теоремы Apache Kudu можно отнести к колоночным CP-системам, которая поддерживает несколько уровней согласованности данных, а также операции обновления и транзакции на уровне записей, обеспечивая высокую производительность при сканировании больших объемов данных и быстрый отклик при поиске [1].
Достоинства и недостатки Куду
Ключевыми преимуществами Apache Kudu считаются следующие [2]:
- поддержка общих принципов экосистемы Hadoop в части невысоких требований к оборудованию, горизонтальной масштабируемости, надежности и высокой доступности;
- интеграция с MapReduce, Spark и другими компонентами экосистемы Hadoop;
- структурированный подход к хранению данных;
- интеграция с Impala, что позволяет эффективно работать с большими данными через SQL-запросы;
- гибкая модель согласованности (consistency), позволяющая выбирать требования согласованности для каждого запроса при строго последовательной согласованности;
- высокая производительность для одновременного выполнения последовательных и случайных операций;
- наличие API C++, Java и Python;
- простота администрирования и эксплуатации.
При этом Kudu свойственен целый ряд ограничений, которые могут рассматриваться как недостатки [5]:
- первичный ключ не может быть изменен после создания таблицы;
- все столбцы, являющиеся частью определения первичного ключа, должны иметь значение NOT NULL;
- по умолчанию таблицы могут содержать не более 300 столбцов;
- столбцы не поддерживают такие типы данных, как CHAR, DATE, ARRAY, MAP и STRUCT;
- таблицы должны иметь нечетное количество реплик, но не более 7. Коэффициент репликации устанавливается во время создания таблицы и не может быть изменен.
- таблицы должны быть предварительно вручную разделены на tablets с использованием простых или составных первичных ключей, автоматическое разделение пока не поддерживается.
- данные в существующих таблицах пока не могут быть автоматически перераспределены – можно вручную создать новую таблицу с новым разделением, вставив туда содержимое старой таблицы.
- tablets-сегменты, которые потеряли большинство реплик при сбое, требуют ручного восстановления;
- внешние ключи, вторичные индексы и многострочные транзакции не поддерживаются.
- имена столбцов и таблиц, должны быть допустимыми строками UTF-8 с максимальной длиной не более 256 символов;
- авторизация на уровне строк недоступна;
- шифрование данных в состоянии покоя напрямую не встроено в Kudu, но может быть обеспечено с помощью отдельных решений, например, dmcrypt;
- безопасный протокол Kerberos на серверах Kudu настраивается в шаблоне kudu / <HOST> @ DEFAULT.REALM;
- WAL-журналы (Write Ahead Log) можно хранить только на одном диске;
- изменение адреса или порта tablet-серверов недопустимо;
- все master-сервера должны быть запущены одновременно при старте кластера;
- рекомендуемая максимальная двухточечная задержка (point-to-point latency) в кластере составляет 20 миллисекунд;
- рекомендуемая минимальная пропускная способность между двумя точками (point-to-point bandwidth) в кластере составляет 10 Гбит/с.
Тем не менее, несмотря на эти недостатки, Apache Kudu активно используется в различных Big Data приложениях вместе с Hadoop и Impala. В следующей статье мы рассмотрим особенности совместного использования этих инструментов для эффективного хранения и быстрой аналитики больших данных.
Еще больше подробностей про работу с большими данными с помощью компонентов экосистемы Apache Hadoop в проектах цифровизации своего бизнеса вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Hadoop
- Администрирование кластера Hadoop
- Hadoop для инженеров данных
- Администрирование кластера Arenadata Hadoop
- Основы Arenadata Hadoop
- Интеграция Hadoop и NoSQL
Источники

