688
688 
Содержание
- Как управлять топиками Kafka: полное удаление, очистка и аварийные сценарии
- Полное удаление топика (Штатный режим)
- Очистка топика (Удаление всех сообщений)
- Способ 1: Временное изменение retention.ms (Рекомендуемый)
- Способ 2: Удаление и пересоздание (Быстрый, но рискованный)
- Важный нюанс: TopicId против Имени топика
- Аварийный сценарий: Закончилось место на диске
- Особый случай: Log Compacted (Сжатые) топики
- Шпаргалка: Что выбрать?
- Полезные ссылки
Как управлять топиками Kafka: полное удаление, очистка и аварийные сценарии
Apache Kafka — мощный инструмент, но без должного ухода он быстро «захламляется». Топики, которые вы создавали для тестов, старые проекты или просто логи, со временем начинают занимать место и мешать. А иногда они разрастаются так, что кластер «ложится» из-за нехватки дискового пространства. Давайте разберемся, как навести порядок в штатном и в аварийном режиме. Важно сразу разделить два понятия:
- Удаление топика (Deletion): Это полное уничтожение. Вы удаляете топик, все его партиции, данные, конфигурации. Он просто исчезает из кластера.
- Очистка топика (Truncation/Cleanup): Вы хотите CОХРАНИТЬ топик (его имя, количество партиций), но удалить из него ВСЕ сообщения. Например, чтобы начать тест заново.
️
Полное удаление топика (Штатный режим)
Это необратимая операция. Если вы удалили топик, вернуть данные стандартными средствами Kafka будет невозможно.
Шаг 0: Важнейшая проверка. По умолчанию в Kafka удаление топиков запрещено. Чтобы его включить, в конфигурации каждого брокера (файл server.properties) должен быть параметр:
# server.properties delete.topic.enable = true
Если этот параметр false или отсутствует, топик будет лишь «помечен к удалению» в Zookeeper/KRaft, но брокеры его физически никогда не сотрут. Если вы админ кластера, убедитесь, что эта опция включена. Если нет — команда удаления просто не сработает как надо.
Шаг 1: Команда удаления. Для удаления используется стандартная утилита kafka-topics.sh.
# Укажите --bootstrap-server или --zookeeper в зависимости от вашей версии и настроек # --bootstrap-server считается современным подходом kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic my_topic_to_delete
Что произойдет? Kafka асинхронно удалит топик. Это может занять от нескольких секунд до нескольких минут, в зависимости от размера топика и нагрузки на кластер. Как проверить, что топик удален? Просто попробуйте получить его описание:
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic my_topic_to_delete
Если вы получите ошибку Error: Topic ‘my_topic_to_delete’ does not exist, значит, все прошло успешно.
Очистка топика (Удаление всех сообщений)
Здесь начинается самое интересное. В Kafka нет прямой команды kafka-topics.sh —clear-data my_topic. Чтобы «опустошить» топик, нам придется прибегнуть к хитрости, основанной на том, как Kafka хранит данные. Самый «правильный» способ — временно изменить политику хранения данных (Retention Policy).

Способ 1: Временное изменение retention.ms (Рекомендуемый)
Шаг 1: Устанавливаем минимальное время хранения. Мы выставляем retention.ms (время хранения в миллисекундах) на очень низкое значение, например, 1000 мс (1 секунда).
kafka-configs.sh --bootstrap-server localhost:9092 --alter \ --entity-type topics --entity-name my_topic_to_clean \ --add-config retention.ms=1000
Шаг 2: Ждем. Данные не исчезнут мгновенно. Kafka нужно время, чтобы заметить изменение и чтобы отработал процесс очистки сегментов. Обычно это занимает от 30 секунд до нескольких минут (в зависимости от настройки log.retention.check.interval.ms на брокере).
Шаг 3: Возвращаем старые настройки. Когда топик пуст, верните старые настройки хранения (если они были) или просто удалите кастомную настройку, чтобы топик использовал дефолтное значение кластера.
kafka-configs.sh --bootstrap-server localhost:9092 --alter \ --entity-type topics --entity-name my_topic_to_clean \ --delete-config retention.ms
Плюсы: Безопасно, не требует остановки продюсеров/консьюмеров (хотя они могут пропустить данные, если активны). Минусы: Не мгновенно.
Способ 2: Удаление и пересоздание (Быстрый, но рискованный)
Этот способ простой, как топор, и такой же «опасный».
Шаг 1: Удаление. Требует delete.topic.enable = true
kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic my_topic_to_clean
Шаг 2: Пересоздание. (ВАЖНО: Вы должны точно знать, сколько партиций и какой фактор репликации был у топика!)
kafka-topics.sh --bootstrap-server localhost:9092 --create \ --topic my_topic_to_clean \ --partitions 3 \ --replication-factor 2
Плюсы: Мгновенный и 100% гарантированный результат очистки.
Минусы:
- Все продюсеры и консьюмеры, которые в этот момент работали с топиком, получат ошибки UNKNOWN_TOPIC_OR_PARTITION.
- Если вы неправильно укажете число партиций или фактор репликации, вы создадите другой топик, что может сломать логику вашего приложения.
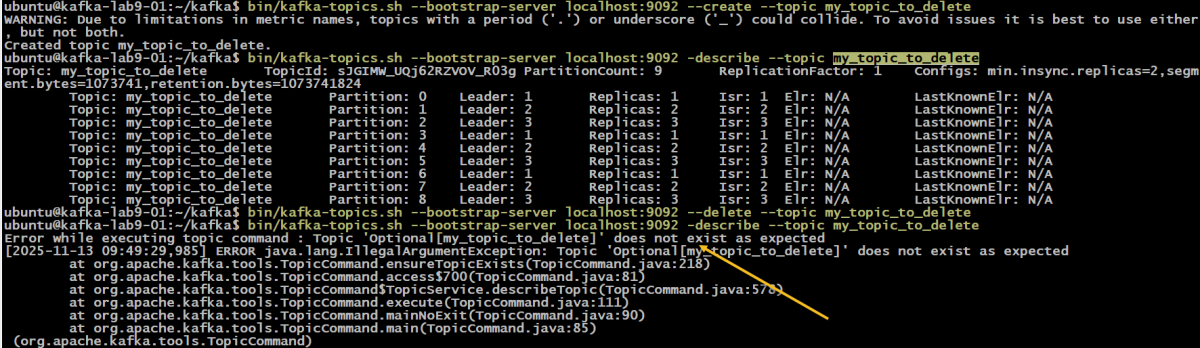
- (Самый главный минус) Вы столкнетесь с проблемой TopicId и старых offset-ов.
Важный нюанс: TopicId против Имени топика
Используя Способ 2 (Удаление и пересоздание), вы должны понимать, как Kafka работает «под капотом». Эта механика была официально закреплена в KIP-516 (Kafka Improvement Proposal 516).
- Снаружи (для вас): Kafka работает с топиками по имени (например, my_topic_to_clean).
- Внутри (для брокера): Kafka идентифицирует каждый топик по TopicId — это уникальный и неизменяемый UUID.
Когда вы удаляете топик и тут же создаете его заново с тем же именем, Kafka генерирует для него новый TopicId. Для кластера это абсолютно новый топик, который просто случайно называется так же, как старый.
Какие у этого последствия?
Конфигурации топика: Все старые настройки (вроде retention.ms) исчезают вместе со старым TopicId. Новый топик создается с настройками по умолчанию (если вы не указали их в команде —create).
ACL (Права доступа): ACL обычно привязаны к имени топика. Поэтому права доступа, скорее всего, продолжат работать для нового топика.
Главная проблема — Consumer Offsets:
- Смещения (offsets) для consumer group хранятся по ключу (groupId, topicName, partition).
- Когда ваша группа (со старыми offset-ами) обращается к новому топику (с тем же именем, но новым TopicId), она пытается читать с тех смещений, которых в новом (пустом) топике еще нет.
- Это приводит к ошибке «вне диапазона», и у потребителя срабатывает политика auto.offset.reset (обычно latest, т.е. он начнет читать новые сообщения, пропуская все, что могло быть записано за секунду до его старта).
Правильное решение при пересоздании: Всегда сбрасывайте смещения для групп, которые читали из старого топика.
kafka-consumer-groups.sh --bootstrap-server localhost:9092 \ --group my-consumer-group \ --topic my_topic_to_clean \ --reset-offsets --to-earliest --execute
Альтернатива — просто начать использовать новый group.id. Как увидеть TopicId? Современные версии kafka-topics.sh показывают его по команде —describe:
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic my_topic_to_clean # Topic: my_topic_to_clean TopicId: VlSNflz1R6G-I-A-m2NlAg PartitionCount: 3 ...
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
18 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Аварийный сценарий: Закончилось место на диске
Это классика: какой-то топик с логами (cleanup.policy=delete) неконтролируемо вырос и «съел» все место. Иногда, хоть и реже, виновником может быть __consumer_offsets. Хоть он и использует политику compact (которая должна сдерживать его размер, храня только последний offset для группы), он может «взорваться», если у вас в кластере по какой-то причине создается огромное количество уникальных consumer group id (например, из-за ошибок в коде или CI/CD-пайплайнах, генерирующих группы-однодневки).
В любом случае, брокеры Kafka «ложатся» или не могут старторовать. Вам нужно срочно освободить место, чтобы поднять кластер.
Проблема: Стандартная команда kafka-topics.sh —delete не сработает или сработает слишком медленно. Она асинхронная. Она говорит «лежачим» брокерам удалить топик, но они не могут этого сделать, так как не работают. Здесь есть два пути, в зависимости от состояния брокеров.
Сценарий А: Брокеры еще «живы», но место почти на нуле (95%+)
Это ваш предпочтительный аварийный сценарий. Немедленно действуйте:
Найдите «пожирателя»:
# Зайдите в папку с логами Kafka (зависит от вашей ОС) cd /var/lib/kafka/data # Посмотрите, какие папки топиков самые большие du -sh *

Агрессивно чистите топик: Не удаляйте его! Используйте Способ 1 (из Раздела 2), но с очень агрессивным тайм-аутом. Установите время хранения 1 минута:
kafka-configs.sh --bootstrap-server localhost:9092 --alter \ --entity-type topics --entity-name a_very_big_topic \ --add-config retention.ms=60000

Ждите: Kafka немедленно начнет применять эту политику и удалять самые старые сегменты лога. Вы должны увидеть, как свободное место на диске начнет появляться в течение нескольких минут. Это самый безопасный способ «потушить пожар».

Сценарий Б: Брокеры «лежат» и не стартуют (Диск 100%)
Это плохой сценарий. Кластер не работает. Команды kafka- не работают.
ВНИМАНИЕ: Следующая процедура — это «хирургическое вмешательство». Она опасна, и ее можно применять, только если кластер УЖЕ неработоспособен. Категорически не рекомендуется для KRaft-кластеров, так как там метаданные хранятся в самой Kafka. Этот метод — для старых кластеров на Zookeeper.
Остановите все сервисы Kafka и Zookeeper (если они еще не «упали»).
sudo systemctl stop kafka sudo systemctl stop zookeeper
Найдите «пожирателя» (как в Сценарии А) с помощью du -sh на каждом брокере.
Удалите файлы вручную: На каждом брокере вам нужно физически удалить папки этого топика
rm -rf /data/kafka/kafka-logs/my_big_topic-0, .../my_big_topic-1
Удалите метаданные из Zookeeper:
# Запускаем ZK shell zookeeper-shell.sh my-zookeeper-host:2181 # Рекурсивно удаляем метаданные rmr /brokers/topics/my_big_topic
Запустите кластер: Сначала Zookeeper, потом брокеры Kafka.
sudo systemctl start zookeeper sudo systemctl start kafka
Для KRaft-кластеров: Не делайте ручного удаления. Лучшая стратегия — временно добавить диск (если это VM), запустить брокеры, а затем штатно удалить топик через kafka-topics.sh —delete.
Особый случай: Log Compacted (Сжатые) топики
Если ваш топик использует cleanup.policy=compact (например, для хранения состояний или топик __consumer_offsets), то метод с retention.ms может сработать не так, как вы ожидаете.
- retention.ms в compact топиках применяется только к «голове» лога (новые сообщения, которые еще не были сжаты).
- Уже сжатые данные (старые версии ключей) он не тронет.
Чтобы очистить compacted топик, самый надежный способ — это Способ 2 (Удаление и пересоздание), но с обязательным сбросом offset-ов, как описано выше.
Шпаргалка: Что выбрать?
| Ваша задача | Рекомендуемый метод |
| Топик больше не нужен (штатно) | Удаление (kafka-topics.sh —delete) |
| Нужен пустой топик для тестов (dev/staging) | Удаление и пересоздание + сброс offset-ов |
| Нужно очистить топик в Production без остановки | Временное изменение retention.ms (Безопасно) |
| Нужно очистить compacted топик | Удаление и пересоздание + сброс offset-ов |
| Авария: Место кончается, но брокеры живы | Агрессивное retention.ms=60000 (Быстро и безопасно) |
| Авария: Брокеры «лежат» (только ZK-кластер) | Ручное удаление файлов + rmr в Zookeeper (Опасно!) |
Полезные ссылки
Для более глубокого погружения в тему:
- Официальная документация Apache Kafka: kafka-topics.sh Первоисточник по всем командам для управления топиками.
- Официальная документация: kafka-configs.sh Описание утилиты для изменения конфигураций, включая retention.ms.
- Официальная документация: Log Compaction (Политика compact) Объяснение, как работает сжатие лога и почему топики compact ведут себя иначе.
- KIP-516: Topic Identifiers (Первоисточник) Техническое предложение, которое ввело TopicId и описало мотивацию (проблему пересоздания топиков).
- Официальная документация: kafka-consumer-groups.sh Описание утилиты для управления группами, включая —reset-offsets.
Надеюсь, это руководство поможет вам держать ваш Kafka-кластер в чистоте и порядке — если нет ждем вас на наших курсах