 1225
1225 
Как написать пользовательский оператор Apache AirFlow и использовать его в DAG. А также чем хороши функции обратного вызова вместо XCom, и когда их не следует применять.
Создаем свой оператор AirFlow и используем его в DAG
Однажды мы уже разбирали, как создать свой оператор Apache AirFlow на примере сенсора – оператора специального вида, который предназначен для выполнения строго одной задачи в виде ожидания, когда что-то произойдет, например, загрузится файл, будет получен ответ от внешней системы и пр. Сегодня поработаем с обычными операторами на примере задачи загрузки файла. Хотя Apache AirFow предоставляет множество операторов для выполнения различных задач, иногда дата-инженеру приходится писать свои собственные.
Оператор AirFlow представляет собой Python-класс, решающий одну задачу в рабочем процессе, включая логику ее выполнения, входы, выходы и зависимости.
Чтобы разработать собственный оператор, нужно создать новый класс Python, который наследуется от класса BaseOperator, предоставленного AirFlow. Например, необходимо считать файл из удаленного места и записать его в локальный каталог. Для разработки собственного оператора в виде Python-скрипта надо сперва импортировать необходимые зависимости:
from airflow.models.baseoperator import BaseOperator from airflow.utils.decorators import apply_defaults from urllib.request import urlretrieve
Затем можно объявить новый класс своего оператора с именем DownloadFileOperator, который является потомком класса BaseOperator и принимает два параметра: URL-адрес удаленного файла для загрузки и локальный каталог для его сохранения.
class DownloadFileOperator(BaseOperator):
@apply_defaults
def __init__(self, source_url, destination_dir, *args, **kwargs):
super().__init__(*args, **kwargs)
self.source_url = source_url
self.destination_dir = destination_dir
def execute(self, context):
self.log.info('Downloading file from %s', self.source_url)
file_path, _ = urlretrieve(self.source_url)
self.log.info('File downloaded to %s', file_path)
self.log.info('Moving file to %s', self.destination_dir)
shutil.move(file_path, self.destination_dir)
self.log.info('File moved to %s', self.destination_dir)
В этом участке кода метод __init__ принимает сообщение параметра и сохраняет его как переменную экземпляра. Метод execute выполняет действия по считыванию и переносу файла: загружает файл с помощью функции urlretrieve из библиотеки urllib, а затем перемещает загруженный файл в указанный локальный каталог с помощью библиотеки Shutil. Декоратор @apply_defaults используется для применения значений по умолчанию к параметрам, переданным конструктору. Использование декоратора необязательно, но может пригодиться для указания значений по умолчанию для параметров создаваемого оператора.
После определения своего оператора, его следует зарегистрировать в AirFlow, чтобы использовать в DAG. Для этого нужно импортировать созданный класс оператора и создать его экземпляр, передав все необходимые аргументы. Далее можно добавить этот экземпляр в качестве задачи в DAG. При этом, как и в любом Python-скрипте, надо сперва импортировать необходимые зависимости:
from airflow import DAG from airflow.operators.dummy_operator import DummyOperator from datetime import datetime from custom_operators import DownloadFileOperator
Затем можно определить свой конвейер обработки данных, т.е. DAG:
dag = DAG(
'download_file_dag',
description='Download a file from a remote location and save it to a local directory',
schedule_interval=None,
start_date=datetime(2023, 3, 26),
)
start = DummyOperator(task_id='start', dag=dag)
download_file = DownloadFileOperator(
task_id='download_file',
source_url='https://example.com/file.txt',
destination_dir='/path/to/local/directory',
dag=dag,
)
end = DummyOperator(task_id='end', dag=dag)
start >> download_file >> end
В этом примере создается DAG с именем download_file_dag с задачей с именем download_file и двумя фиктивными задачами в качестве начала и конца. Экземпляр DownloadFileOperator создается с параметрами URL-адреса источника (source_url) и директории назначения (destination_dir), для которых заданы значения https://example.com/file.txt и /path/to/local/directory соответственно.
В GUI Apache Airflow созданный конвейер обработки данных будет выглядеть следующим образом:
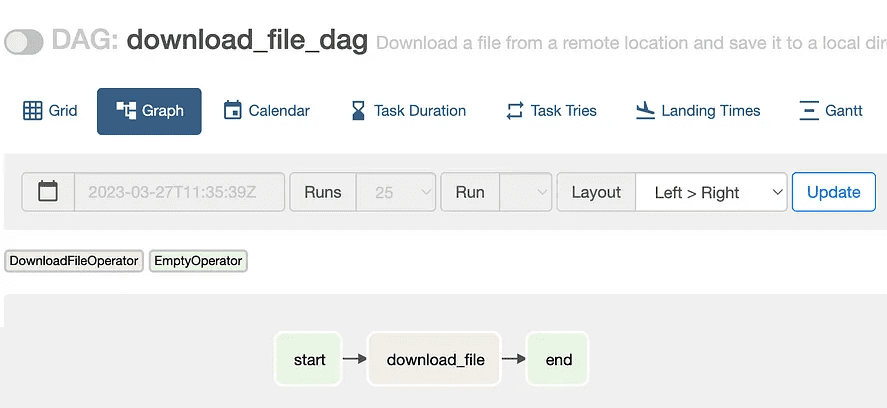
Таким образом, создание собственного пользовательского оператора AirFlow может расширить функциональные возможности этого ETL-фреймворка в соответствии с конкретными потребностями дата-инженера. Следует всего лишь определить новый класс оператора и реализовать метод execute(), чтобы создать пользовательскую задачу, которую можно использовать в DAG, как и любой другой оператор.
Однако, при этом стоит помнить о рекомендации делать оператор идемпотентным, чтобы результаты его повторного вызова не создавали побочных эффектов в виде создания нового файла или рекурсивного удаления объектов. Разумеется, перед использованием пользовательского оператора в реальном проекте, его следует тщательно протестировать, о чем мы говорили здесь.
Читайте в нашей новой статье, как использовать самую модную на сегодня ИИ-технологию ChatGPT для создания своего пользовательского оператора AirFlow, работающего с OpenAPI.
Обратный вызов вместо XCom
Кроме создания пользовательских операторов также дата-инженеру необходимо организовать взаимодействие между ними. Разумеется, для этого можно использовать механизм XCom (Cross Communication), который позволяет обмениваться небольшим количеством данных между задачами в AirFlow, храня эти промежуточные данные в метаданных фреймворка. Однако, этот способ не универсален и имеет ограничения, связанные с размером передаваемых данных. Предельный размер XCom в Apache AirFlow зависит от базы данных, которая используется для хранения метаданных. В частности, для встроенной SQLite этот лимит равен 2 ГБ, для PostgreSQL 1 ГБ и 64 КБ для MySQL. Подробнее об этом мы писали здесь.
Вместо XCom можно использовать функцию обратного вызова on_success_callback() как на уровне оператора, так и на уровне DAG. Этот подход позволяет сделать DAG максимально простым и может быть обобщен для применения в нескольких конвейеров обработки данных.
Возвращаясь к ранее рассмотренному примеру, добавим в DAG и созданный оператор функцию обратного вызова:
dag = DAG(
'download_file_dag',
description='Download a file from a remote location and save it to a local directory',
on_success_callback=on_success_callback,
schedule_interval=None,
start_date=datetime(2023, 3, 26),
)
start = DummyOperator(task_id='start', dag=dag)
download_file = DownloadFileOperator(
task_id='download_file',
source_url='https://example.com/file.txt',
destination_dir='/path/to/local/directory',
dag=dag,
on_success_callback=on_success_callback,
)
end = DummyOperator(task_id='end', dag=dag)
start >> download_file >> end
Теперь DAG и оператор загрузки файла определяют функцию on_success_callback() и оба ее используют. Разумеется, надо определить саму эту функцию. Для простоты в этом определении выведем идентификатор экземпляра задачи и индекс сопоставления:
def on_success_callback(context, session=None):
task_instance = context["ti"]
print("------------")
print("ON_SUCCESS_CALLBACK CALLED")
print(task_instance.task_id)
print(task_instance.map_index)
print("------------")
Результаты работы созданного оператора и DAG, в котором он используется, можно посмотреть в GUI Apache AirFlow. В заключение отметим, что не рекомендуется применять одну и ту же функцию обратного вызова для DAG и оператора, если его поведение зависит от какого-либо (сопоставленного) свойства экземпляра задачи. Как обратные вызовы могут пригодиться при отладке и мониторинге конвейера обработки данных. читайте в нашей новой статье.
Освойте все возможности Apache AirFlow для дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

