 1730
1730 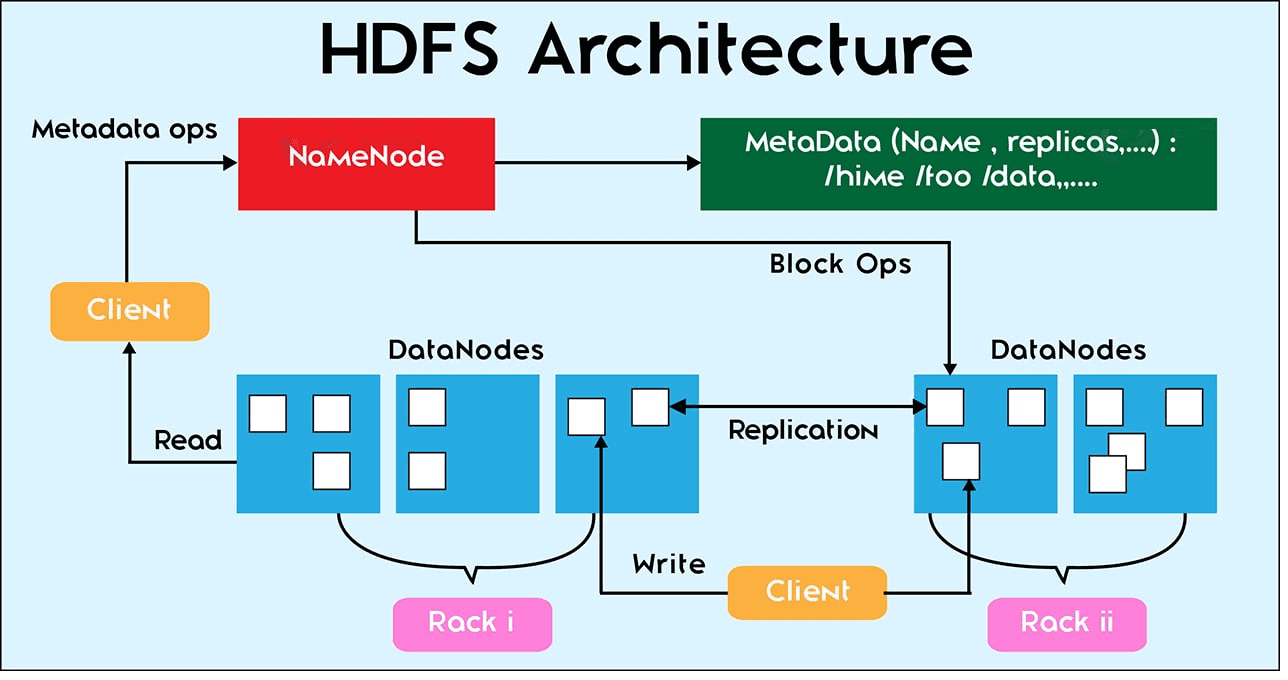
Содержание
Мы уже рассказывали, как большие данные (Big Data) сохраняются на диск. Сегодня поговорим о других файловых операциях в HDFS: репликации, чтении и удалении данных.
За все файловые операции в Hadoop Distributed File System отвечает центральная точка кластера – сервер имен NameNode. Сами операции с конкретными файлами выполняются на локальном узле данных DataNode, где эти файлы находятся [1].
Что такое репликация данных и зачем она нужна
Репликация данных в HDFS – это процесс синхронизации содержимого нескольких копий файлового блока, когда его содержимое с одного DataNode копируется на другие узлы данных, чтобы предотвратить потерю данных в случае сбоя какого-либо хранилища.
По умолчанию все HDFS-блоки реплицируются 3 раза, если клиентом (пользователем или приложением) не задано другое значение коэффициента репликации. С целью повышения надежности для хранения 2-ой и 3-ей реплики выбираются те узлы данных, которые расположены в разных серверных стойках. Последующие реплики могут храниться на любых серверах. Чтобы предотвратить потерю данных в случае сбоя кластера, следует настроить сервер имен так, чтобы он знал, на каких серверных стойках расположены узлы данных. Это делается с помощью специального механизма Hadoop — rack awareness [1].
Важно отметить, что в HDFS отсутствуют инструменты поддержки ссылочной целостности данных, которые могут гарантировать идентичность реплик. А, поскольку репликация выполняется в асинхронном режиме, т.е. с задержкой, вопрос идентичности реплик остается открытым – по крайней мере, на время распространения копий. Проверка целостности данных находится в зоне ответственности клиента. При создании файла клиент рассчитывает контрольные суммы каждые 512 байт и сохраняет их на сервере имен [2].
Когда и как реплицируются данные
Репликация данных в HDFS выполняется в следующих случаях [2]:
- создание нового файла (операция записи);
- обнаружение сервером имен отказа одного из узлов данных – если NameNode не получает от DataNode heartbeat-сообщений, он запускает механизм репликации;
- повреждение существующих реплик;
- увеличение количества реплик, присущих каждому блоку.
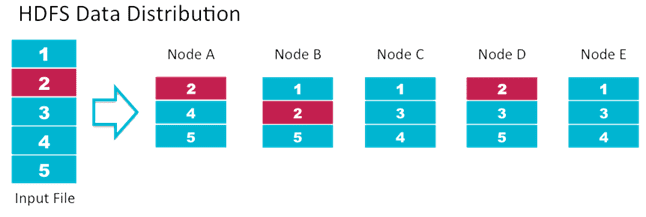
Репликация данных выполняется следующим образом [2]:
- NameNode выбирает новые узлов данных для размещения реплик;
- сервер имен выполняет балансировку размещения данных по узлам и составляет список узлов для репликации;
- 1-я реплика размещается на первом узле из списка;
- 2-я реплика копируется на другой узел в этой же серверной стойке;
- 3-я реплика записывается на произвольный узел в другой серверной стойке;
- остальные реплики размещаются произвольным способом.
Чтение данных в HDFS
Для чтения файла клиент получает адреса расположения блоков от сервера имен и самостоятельно последовательно считывает файловые блоки с узлов данных. Для каждого блока выбирается ближайший узел с репликой. Поскольку клиент считывает файлы напрямую с узлов данных, возможно большое количество конкурентных клиентов, т.к. трафик распределен между узлами данных в кластере [3]. Также при считывании файла клиент обращается к контрольным суммам, хранящимся на сервере имен. В случае их несоответствия клиент обращается к другой реплике [2]
Удаление данных в HDFS
Чтобы обеспечить сохранность данных на случай отката операции удаления, в HDFS это выполняется следующим образом [2]:
- файл перемещается в специально отведенную для этого директорию – корзину, /trash;
- по истечении определенного времени происходит физическое удаление файла – удаление из пространства имен HDFS и освобождение связанных с данными блоков.
Узнайте больше о работе с HDFS: настройка, администрирование и использование инфраструктуры Hadoop для больших данных и машинного обучения в нашем учебном центре в Москве для новичков и профессионалов – специализированные компьютерные курсы для пользователей, инженеров, администраторов и аналитиков Big Data:
- INTR: Основы Hadoop;
- HADM: Администрирование кластера Hadoop;
- HIVE: Hadoop SQL Hive администратор.
- DSEC: Безопасность озера данных Hadoop
- HDDE: Hadoop для инженеров данных
- BAHU: Основы Hadoop для пользователей
Источники

