 914
914 
Благодаря архитектурным особенностям распределенной файловой системы Hadoop, допустимые файловые операции в ней отличаются от возможных действий с файлами на локальных системах. В этой статье мы рассмотрим файловые операции в HDFS и взаимодействие ее компонентов: узлов данных и сервера имен с клиентами — пользователями или приложениями.
Файловые операции HDFS
В отличие от локальных файловых систем, в HDFS (Hadoop Distributed File System) невозможно изменение (модификация) файла. Файлы в HDFS могут быть записаны лишь однажды, причем одновременно запись в файл осуществляет только один процесс. Поскольку HDFS используется для Big Data, эта файловая система ориентирована на большой размер файлов (>10GB). При этом файлы состоят из блоков, размер которых тоже больше, чем у других файловых систем: >64MB [1].
Итак, в HDFS допустимы только следующие операции с файлами:
За все файловые операции отвечает сервер имен NameNode. Операции с конкретными файлами находятся в зоне ответственности узла данных DataNode, на котором эти файлы находятся [2]. Подробности каждой из этих операций мы раскрыли в отдельных статьях.
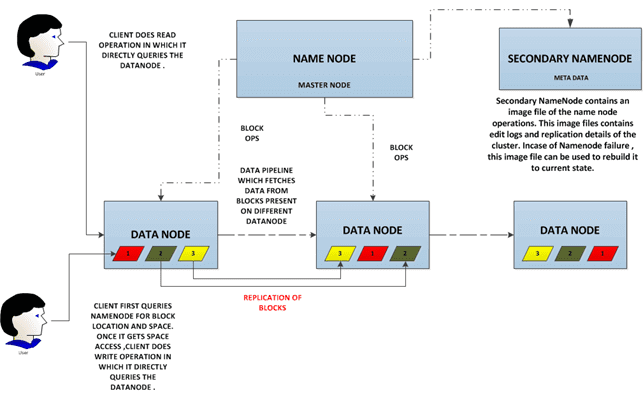
Взаимодействие клиента и кластера
Общение между узлами данных и сервером имен, а также взаимодействие с клиентами осуществляется по протоколам на основе TCP/IP: DataNode Protocol и ClientProtocol соответственно [2]. Оба протокола используют технологию удаленного вызова процедур (Remote Procedure Call, RPC), которая расширяет локальный механизм передачи управления и данных внутри программы на распределенный режим (через сеть).
RPC-вызовы являются асимметричными (только 1 из взаимодействующих сторон инициирует общение) и синхронными (выполнение вызывающей процедуры приостанавливается с момента выдачи запроса и возобновляется лишь после возврата из вызываемой процедуры).
Из-за того, что вызывающая и вызываемая процедуры находятся на разных компьютерах, невозможно использовать разделяемую память, поэтому все параметры RPC-вызова копируются с одного сервера на другой в виде последовательности битов, т.е. сериализуются [3].
Узлы данных DataNode взаимодействуют друг с другом по протоколу DataNode Protocol. Сервер имен NameNode никогда сам не инициирует RPC-вызовы, а лишь отвечает на RPC-вызовы узлов данных и клиентов [2].
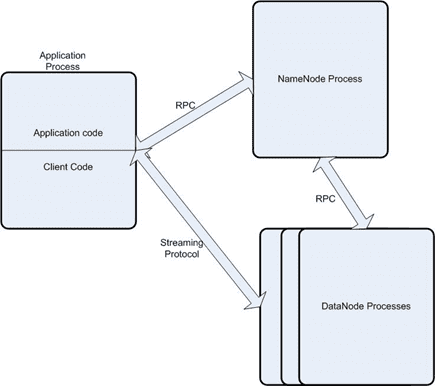
Взаимодействие с клиентом состоит из следующих шагов [4]:
- Клиент отправляет работу (job, файл в формате jar) на трекер работ (JobTracker), создавая при этом соединение через специально сконфигурированный для взаимодействия TCP-порт на сервере имен. Взаимодействие происходит по протоколу ClientProtocol.
- JobTracker ищет трекеры задач (TaskTracker), учитывая локализацию данных – в приоритете те трекеры, которые уже хранят данные из файловой системы. Далее каждый найденный TaskTracker получает задание на выполнение MapReduce-операций.
- После выполнения задачи TaskTracker отправляет на JobTracker отчет об этом. В случае сбоя подзадача автоматически перезапускается на другом узле.
Все о HDFS, а также практика настройки, администрирования и использования инфраструктуры Hadoop для Big Data и Machine Learning в нашем учебном центре на компьютерных курсах для пользователей, инженеров, администраторов и аналитиков больших данных в Москве:
- INTR: Основы Hadoop;
- HADM: Администрирование кластера Hadoop;
- HIVE: Hadoop SQL Hive администратор.
- DSEC: Безопасность озера данных Hadoop
- HDDE: Hadoop для инженеров данных
- BAHU: Основы Hadoop для пользователей
Источники
- https://ru.wikipedia.org/wiki/Hadoop
- https://www.codeinstinct.pro/2012/08/hdfs-design/?m=1
- https://ru.wikipedia.org/wiki/Удалённый_вызов_процедур
- https://habr.com/ru/company/dataart/blog/234993/

