 699
699 
Содержание
Сегодня разберем типовые ошибки, которые часто возникают в системах аналитики больших данных на базе Apache Hadoop YARN, Spark и RESTful-интерфейсу Livy, а также каким образом их избежать. В качестве практического примера используем ранее рассмотренный кейс интерактивной аналитики о пользовательском поведении в фотохостинге Pinterest.
Интерактивная аналитика больших данных в Pinterest
Недавно мы рассказывали, как система анализа данных о поведении пользователей соцсети Pinterest ежедневно обрабатывает около 1500 интерактивных запросов Spark SQL практически без отказов. Основными технологиями этой системы стали Apache Hadoop YARN, Spark и Livy. Однако, сбои периодически случаются, поэтому нужно не только оперативно устранить их, но и определить причину, чтобы не допустить повторного отказа. Без автоматизации процессов сопровождения Big Data системы исправление таких сбоев сводится к длинному и утомительному циклу просмотра журналов драйверов, поиска решения путем самодиагностики и повторной попытки запроса. Чтобы упростить этот процесс и снять с себя часть рутинных задач, дата-инженеры компании Pinterest определили наиболее частые отказы и причины их возникновения. Каждый из них мы рассмотрим далее.
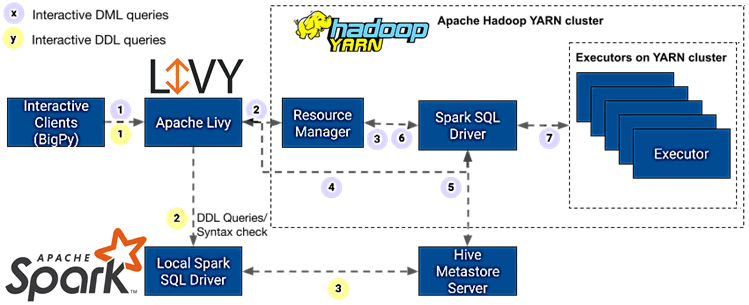
Сбой приложения в Hadoop YARN на основании статуса выполнения последнего запроса
Интерактивные сеансы Livy в кластерном режиме постоянно сообщают мастеру приложения YARN о своем успешном статусе. Это происходит потому, что программа удаленного драйвера, отправленная Livy в SparkLauncher, запускает контекст Spark, выполняет в нем некоторые запросы, а затем закрывает. При этом, независимо от статуса запущенных запросов, окончательный результат определяется статусом успешного закрытия контекста Spark, что вводит в заблуждение пользователей. Чтобы смягчить эту проблему, необходимо отслеживать состояние выполнения последнего запроса в рамках одного интерактивного сеанса, генерируя исключение времени выполнения в программе удаленного драйвера при сбое запроса. Это помогает правильно сообщить мастеру приложения YARN о статусе сеанса и указать причину сбоя в случае его возникновения.
Ошибки в пользовательских запросах Spark SQL и интеграция с клиентами
После внесения в журнал диагностики YARN записи с указанием причины сбоя запроса, необходимо отследить саму ошибку в Spark SQL. Чтобы определить, какие ошибки совершаются чаще всего, дата-инженеры Pinterest просмотрели историю трассировок стека сбоев и классифицировали их с помощью регулярных выражений. Для отслеживания эвристики и показателей приложения Spark использовался инструмент мониторинга производительности и настройки приложений Dr. Elephant. В него добавлен метод классификации ошибок, который просматривает диагностическую информацию YARN для приложения и классифицирует ее на основе механизма регулярных выражений. В веб-интерфейс Dr. Elephant добавлена информация об устранении неполадок для типичных ошибок, обнаруживаемых через REST API.
А сам RESTful-API Dr.Elephant интегрирован с Apache Livy для каждого запущенного приложения Spark. Эта конечная точка возвращается клиентам при каждом запуске запроса и удобна для просмотра информации об устранении неполадок. Получив конечную точку анализа устранения неполадок Dr. Elephant от Livy, клиент извлекает эту информацию из API и отображает ее в логах запросов. Это позволяет пользователям быстрее диагностировать проблемы и устранить самостоятельно.
Чрезмерное потребление ресурсов в кластере Spark
SparkАнализируя показатели потребления памяти в кластерах Apache Hadoop и Spark, сотрудники Pinterest заметили, что приложения часто выделяют излишнюю память исполнителям и драйверам, что приводит к ненужной трате ресурсов. С другой стороны, для некоторых Spark-приложений часто случались ошибки нехватки памяти (OOM, Out Of Memory), про которые мы писали здесь и здесь. Поэтому их пользователям требовалось упреждающее обнаружение таких проблем, чтобы быстрее перенастроить свои запросы.
Для этого было решено показывать информацию о потреблении памяти в реальном времени непосредственно на клиентах с учетом агрегирующей статистики о максимальной, минимальной и средней памяти, используемая всеми исполнителями Spark. Также на этом дэшборде отмечается недостаточное и чрезмерное потребление и формируются рекомендации для пользователей на основе эвристики.
Информация о потреблении памяти в реальном времени собирается для каждого Spark-приложения с помощью специального приемника метрик, который использует библиотеку метрик этого фреймворка. Затем эти показатели проверяются на вхождение в диапазон допустимых значений, а клиентам возвращается информация в табличном виде.
Обработка больших результатов в Livy
По умолчанию Apache Livy имеет ограничение в 1000 строк для набора результатов запроса. Этот набор результатов хранится в памяти, поэтому увеличение предела 1000 строк может привести к проблемам при масштабировании в среде с ограничением памяти. Чтобы решить эту проблему, конечный результат каждого запроса перенаправляется в AWS S3, куда можно загружать большие датасеты за несколько раз, не влияя на общую производительность сервиса. Далее на клиенте извлекается окончательный выходной путь S3, возвращенный в ответе на REST-запрос с разбивкой на страницы. Это ускоряет поиск без риска истечения тайм-аутов AWS S3 при перечислении объектов пути.
Такое перенаправление также можно настроить на уровне запроса, чтобы получать его непосредственно из конечной точки REST без дополнительных обращений к файловому хранилищу. Интерактивность сохраняется благодаря обновлениям в режиме реального времени, которые получаются путем усреднения количества завершенных и активных задач по общему числу задач для запроса Spark SQL.
Узнайте больше полезных приемов практического использования Apache Spark и Livy для разработки распределенных приложений и построения конвейеров аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Построение эффективных конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
Источники

