 1166
1166 
Содержание
Зачем маркировать DAG в Apache AirFlow тегами, как их задать и где это пригодится дата-инженеру. А также еще разберем, какими свойствами должен обладать хорошо спроектированный конвейер обработки данных и как они улучшают их качество.
Тегирование DAG в Apache AirFlow
Когда дата-инженер работает с несколькими конвейерами данных, помнить все зависимости между ними становится трудно. Чтобы ускорить поиск цепочек задач в визуальном веб-интерфейсе фреймворка, Apache AirFlow предоставляет механизм тегирования. Теги — это проиндексированные строки ключевых слов, доступные для поиска, подобно хэштегам в социальных сетях для маркировки сообщений по определенной теме. Впервые тэги стали доступны в версии AirFlow 1.10.8.
Ключи тегов имеют максимальную длину 32 символа и могут содержать только буквы (a-zA-Z), цифры (0-9), символы подчеркивания (_), точки (.), двоеточия (:) и тире (-). Значения тегов имеют максимальную длину 200 символов и не могут содержать символ новой строки (\n). Важно, чтобы при тегировании DAG вся команда дата-инженеров придерживалась одного стиля и соглашения о маркировке, например, привязывая теги к событиям или другим особенностям домена.
Чтобы отфильтровать DAG, к примеру, по команде или какой-то функции, можно добавить теги. Фильтр сохраняется в файле cookie и может быть сброшен в GUI. Тегирование выполняется в файле DAG, где надо указать список тегов, которые следует добавить к объекту DAG:
dag = DAG(dag_id="example_dag_tag", schedule="0 0 * * *", tags=["example"])
Затем по значению тега можно искать экземпляры DAG в GUI:
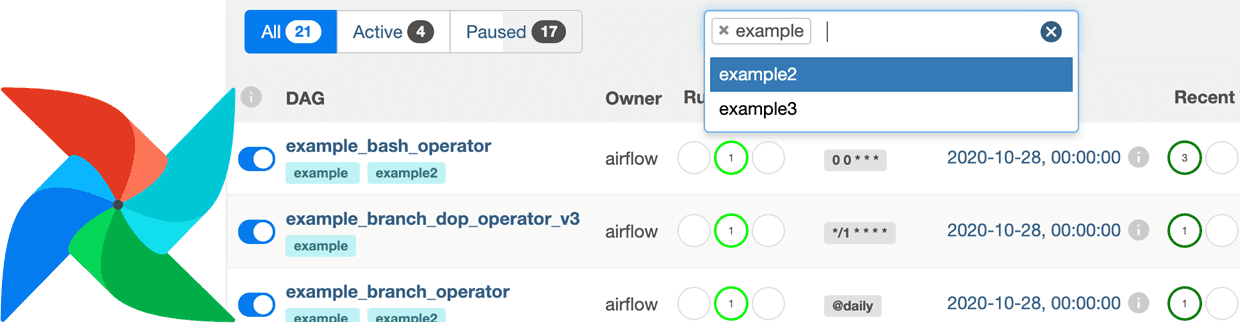
На практике такой поиск DAG может быть особенно полезен дата-инженеру в следующих сценариях:
- мониторинг происхождения графа задач;
- тестирование и устранение сбоев.
В AirFlow отдельные DAG являются независимыми друг от друга объектами. С помощью тегов их можно отнести к одной группе, что позволит найти связанные графы задач, не обращаясь к документации или кодовой базе. Для поддержания уровня согласованности между различными системами можно установить следующие теги, показывающие уровень критичности влияния одного DAG на другие:
- наивысший приоритет, что предполагает влияние DAG на множество процессов и пользователей;
- повышенная важность задания, которое ограниченно влияет на другие процессы. Обычно в этом случае затрагивается одна команда или небольшая группа пользователей, а сам конвейер обработки данных конвейер не создает критически важных для бизнеса показателей;
- не критично – DAG не влияет на другие процессы и не используется для создания каких-либо управленческих решений, используемых бизнес-пользователями.
Таким образом, маркировка DAG’ов с помощью тегов не зря считается одной из лучших практик работы дата-инженера с Apache AirFlow, о чем мы упоминали здесь. Другие рекомендации по проектированию конвейеров обработки данных рассмотрим далее.
3 главных свойства качественного конвейера обработки данных
Самым первым качеством хорошо спроектированного конвейера обработки данных можно назвать модульность, когда общие компоненты определены и их код отделен от остальной части конвейера, чтобы не повторять одну и ту же логику несколько раз. Например, когда есть много заданий, где выполняются большие SQL-запросы, рекомендуется организовать код так, чтобы блокноты не содержали «лишние» строки за пределами этих запросов. Если хранить эти SQL-запросы в виде файлов YAML в расположении конфигурации S3 для всех заданий, определив все необходимые столбцы, условия и соединения, то их использование можно автоматизировать. В частности, разработать скрипт или библиотеку, которая берет YAML-конфигурацию и преобразует ее в обычный SQL-запрос, чтобы быстро найти его и использовать.
Такой подход отлично работает с Apache AirFlow, позволяя создать Python-скрипты или утилиты для общего кода, например, вызов внешних API для сбоев заданий. Это делает конвейеры обработки данных понятными и читабельными.
Вторым важным качество хорошо спроектированного конвейера является гибкость, т.е. возможность его настройки через определение параметров. Так можно легко и быстро вызывать задания в нужное время. Для AirFlow следует сохранить ключевые параметры в файлах YAML и загрузить в конвейер с отдельными папками для каждой среды. Дополнительное преимущество дает подход с одним файлом конфигурации для каждого конвейера, как описано выше.
Наконец, тестируемость нужная для проверки и гарантии корректной работы конвейера обработки данных. Успешно пройденные тестовые примеры показывают, что ключевые компоненты конвейера работают должным образом. Однако, дата-инженеру недостаточно просто запускать интеграционные тесты данных в среде разработки, следует тестировать ключевые функции, чтобы выявлять проблемы, когда они возникают. Также тестирование конвейера помогает повысить качество данных, о чем мы недавно писали. О других лучших практиках использования Apache AirFlow для эффективного проектирования DAG читайте в нашей новой статье. А о том, как организовать отслеживание оповещений AirFlow с помощью сервиса мониторинга cron-заданий Healthchecks.io, мы рассказываем в этом материале.
Больше полезных приемов администрирования и эксплуатации Apache AirFlow для дата-инженерии и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/@ganesan.ramesh77/how-to-use-airflow-tags-for-dag-lineage-8ac941baba91
- https://airflow.apache.org/docs/apache-airflow/stable/howto/add-dag-tags/
- https://mozilla.github.io/bigquery-etl/reference/airflow_tags/
- https://docs.sentry.io/platforms/python/guides/airflow/enriching-events/tags/
- https://medium.com/@matt_weingarten/data-pipeline-best-practices-7993e5760588

