 1058
1058 
Недавно мы писали про JSON-преобразования в Apache NiFi. Продолжая тему работы с данными различного формата, сегодня рассмотрим, как штатными средствами этого потокового ETL-инструмента преобразовать данные, поступающие в виде XML-документов.
Что такое XSLT
Хотя сегодня XML-формат нельзя назвать самым модным, он до сих пор активно используется во многих информационных системах, которые могут генерировать и потреблять данные в потоковых ETL-конвейерах. Если таких XML-документов множество, для их маршрутизации и обработки можно использовать Apache NiFi. Этот фреймворк позволяет работать с XML-документами следующими способами:
- использовать встроенный процессор TransformXML, который применяет предоставленный файл XSLT к полезной нагрузке XML в потоковом файле. Новый FlowFile создается с преобразованным содержимым и направляется в отношение success. Если XSL-преобразование не удается, исходный FlowFile перенаправляется к отношению failure.
- написать собственный скрипт, используя процессор ExecuteScript, если логику преобразования сложно реализовать в XML-преобразованиях (XSLT). Например, в языке Groovy обработка XML довольно лаконична и позволяет эффективно манипулировать с тегированными данными в нетривиальных XSLT или JOLT-спецификациях.
- Написать пользовательский процессор, расширив собственный скрипт, чтобы повторно использовать этот компонент в нескольких конвейерах данных и делиться им с командой.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Сравним производительность этих способов, но сперва вспомним, что представляет собой XSLT (eXtensible Stylesheet Language Transformations) — язык преобразования XML-документов. XSLT позволяет отделить данные от их представления и преобразовать XML-документы из одной XSD-схемы в другую. Правила преобразования данных из исходного дерева XML-документа пишутся на языке запросов XPath. XSLT-процессор получает на входе два документа: входной XML-документ и таблицу стилей XSLT, чтобы создать выходной документ.
Язык XSLT является декларативным: он определяет правила, которые будут применяться к XML-документу во время преобразования по фиксированному алгоритму. Сначала XSLT-процессор разбирает файл преобразования и строит XML-дерево входного файла, затем ищет подходящий для корневого узла шаблон и вычисляет его содержимое. Инструкции в каждом шаблоне декларируют XSLT-процессору создание определенного тега или обработку какого-либо узла по какому-то правилу.
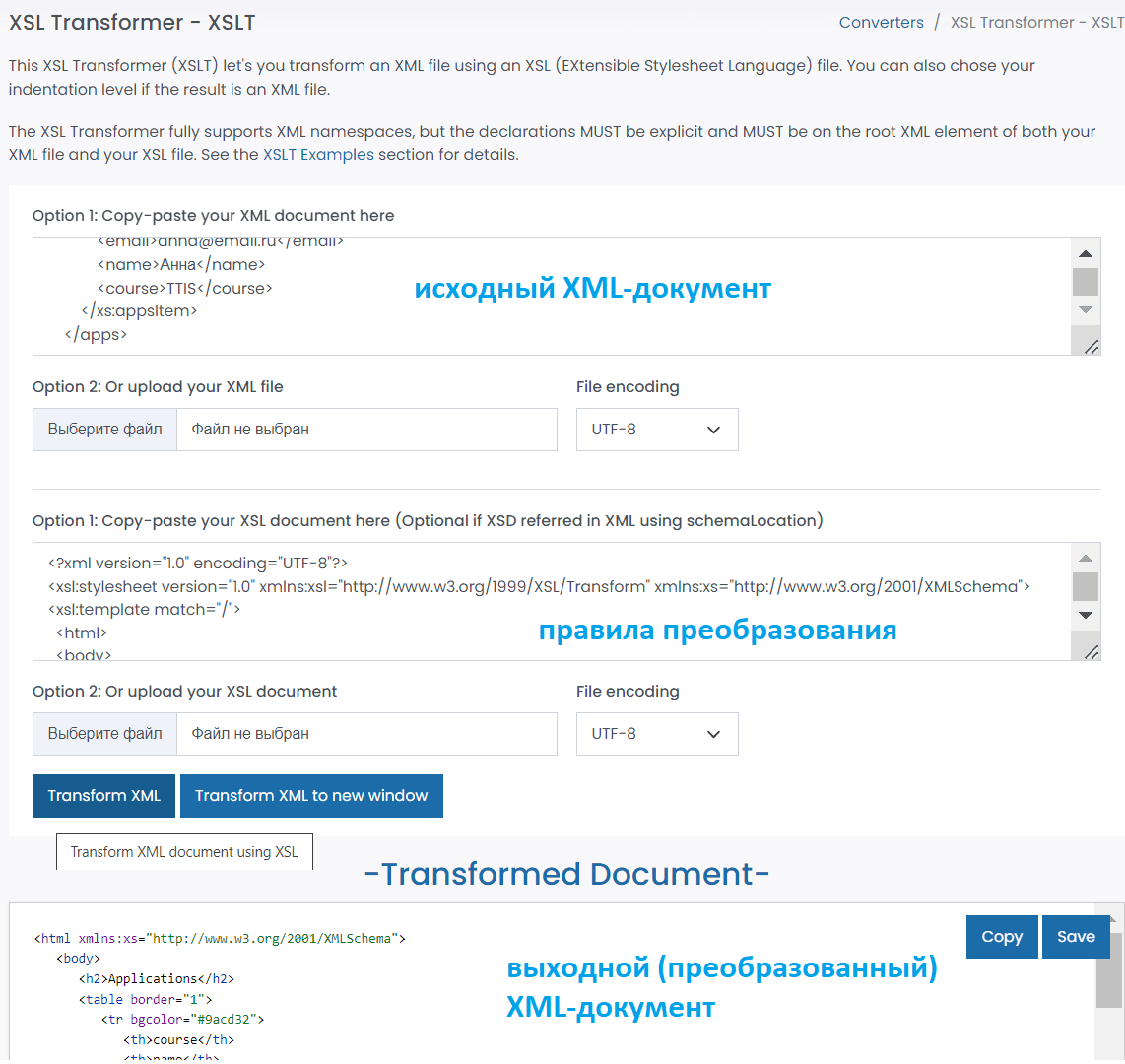
В качестве практического примера возьмем исходный XML-документ, который содержит набор данных по заявкам слушателей на курсы по бизнес-анализу:
<?xml version="1.0" encoding="ISO-8859-1"?>
<apps xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:appsItem>
<wishes>
<info>Позвоните мне для уточнения деталей</info>
<group >false</group >
<online>false</online>
<city>Москва</city>
<country>Россия</country>
</wishes>
<corp>false</corp>
<phone>998887766</phone>
<name>Алексей</name>
<course>MODP</course>
</xs:appsItem>
<xs:appsItem>
<wishes>
<company>Банк</company>
<group >true</group >
<online>false</online>
<city>Астана</city>
<country>Казахстан</country>
</wishes>
<corp>true</corp>
<email>nikita@email.bank</email>
<phone>1122334455</phone>
<name>Никита</name>
<course>BAMP</course>
</xs:appsItem>
<xs:appsItem>
<wishes>
<info>Прошу связаться со мной в телеграм</info>
<group >true</group >
<online>true</online>
<country>Россия</country>
</wishes>
<corp>false</corp>
<phone>987654321</phone>
<name>Лиза</name>
<course>OAIS</course>
</xs:appsItem>
<xs:appsItem>
<wishes>
<group >false</group >
<online>true</online>
</wishes>
<corp>false</corp>
<email>boris@email.ru</email>
<name>Борис</name>
<course>MODP</course>
</xs:appsItem>
<xs:appsItem>
<wishes>
<number_of_students>20</number_of_students>
<group >true</group >
<online>true</online>
<city>Казань</city>
</wishes>
<corp>true</corp>
<phone>123456789</phone>
<email>anna@email.ru</email>
<name>Анна</name>
<course>TTIS</course>
</xs:appsItem>
</apps>
Далее составим XSLT-спецификацию, которая будет описывать преобразования:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xsl:template match="/">
<html>
<body>
<h2>Applications</h2>
<table border="1">
<tr bgcolor="#9acd32">
<th>course</th>
<th>name</th>
<th>phone</th>
<th>email</th>
<th>corp</th>
<th>wishes</th>
</tr>
<xsl:for-each select="apps/xs:appsItem">
<tr>
<td><xsl:value-of select="course"/></td>
<td><xsl:value-of select="name"/></td>
<td><xsl:value-of select="phone"/></td>
<td><xsl:value-of select="email"/></td>
<td><xsl:value-of select="corp"/></td>
<td><xsl:value-of select="wishes"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
С помощью онлайн-конвертера https://www.freeformatter.com/xsl-transformer/ получим выходной XML-документ, преобразованный из исходного:
<html xmlns:xs="http://www.w3.org/2001/XMLSchema">
<body>
<h2>Applications</h2>
<table border="1">
<tr bgcolor="#9acd32">
<th>course</th>
<th>name</th>
<th>phone</th>
<th>email</th>
<th>corp</th>
<th>wishes</th>
</tr>
<tr>
<td>MODP</td>
<td>Алексей</td>
<td>998887766</td>
<td/>
<td>false</td>
<td>
Позвоните мне для уточнения деталей
false
false
Москва
Россия
</td>
</tr>
<tr>
<td>BAMP</td>
<td>Никита</td>
<td>1122334455</td>
<td>nikita@email.bank</td>
<td>true</td>
<td>
Банк
true
false
Астана
Казахстан
</td>
</tr>
<tr>
<td>OAIS</td>
<td>Лиза</td>
<td>987654321</td>
<td/>
<td>false</td>
<td>
Прошу связаться со мной в телеграм
true
true
Россия
</td>
</tr>
<tr>
<td>MODP</td>
<td>Борис</td>
<td/>
<td>boris@email.ru</td>
<td>false</td>
<td>
false
true
</td>
</tr>
<tr>
<td>TTIS</td>
<td>Анна</td>
<td>123456789</td>
<td>anna@email.ru</td>
<td>true</td>
<td>
20
true
true
Казань
</td>
</tr>
</table>
</body>
</html>
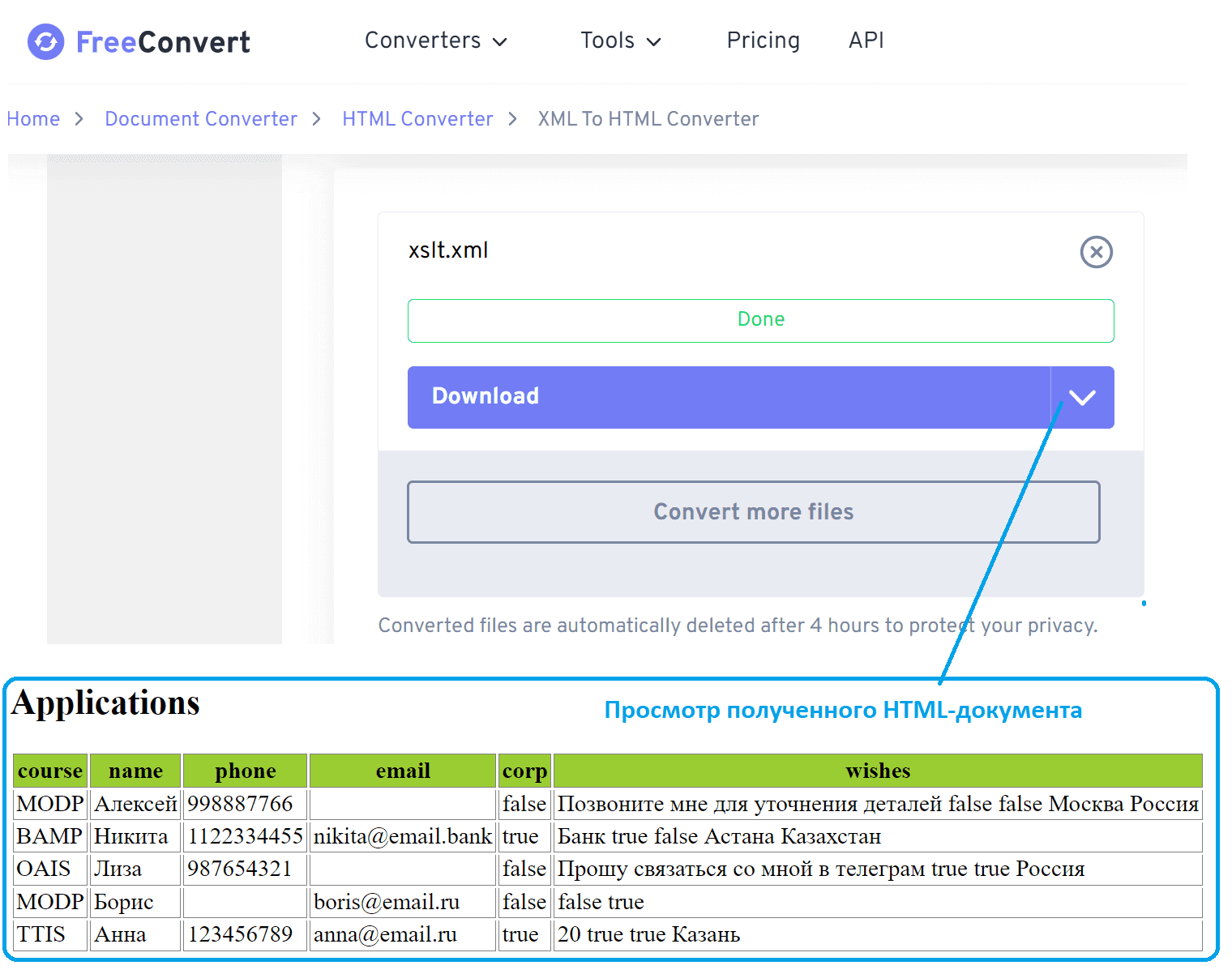
Чтобы просмотреть полученный файл в виде HTML-документа, воспользуемся другим онлайн-конвертером https://www.freeconvert.com/xml-to-html/:
Разобравшись с тем, что такое XSLT, далее рассмотрим, как обработать XML-документы в Apache NiFi.
Обработка XML-документов в Apache NiFi
Предположим, необходимо обработать множество XML-файлов на основе одной и той же входной схемы XSD. А выходные данные должны быть в другом формате, например, AVRO или JSON и должны соответствовать другой схеме. Как мы уже отметили выше, для этого преобразования XML-документов можно реализовать один из следующих способов:
- использовать встроенный процессор TransformXML, который применяет предоставленный файл XSLT к полезной нагрузке XML в потоковом файле;
- написать собственный скрипт, используя процессор ExecuteScript;
- написать пользовательский процессор.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Чтобы сравнить производительность этих 3-способов, создадим в NiFi небольшой дата-конвейер. Процессор GenerateFlowFile будет генерировать потоки XML-документов, которые будут параллельно направляться на 3 разных процессора, реализующих вышеупомянутые способы выполнения XSLT-преобразований в Apache NiFi. Протестируем производительность этих XSLT-процессоров на XML-документах разного размера (от 5 КБ до 1 МБ).
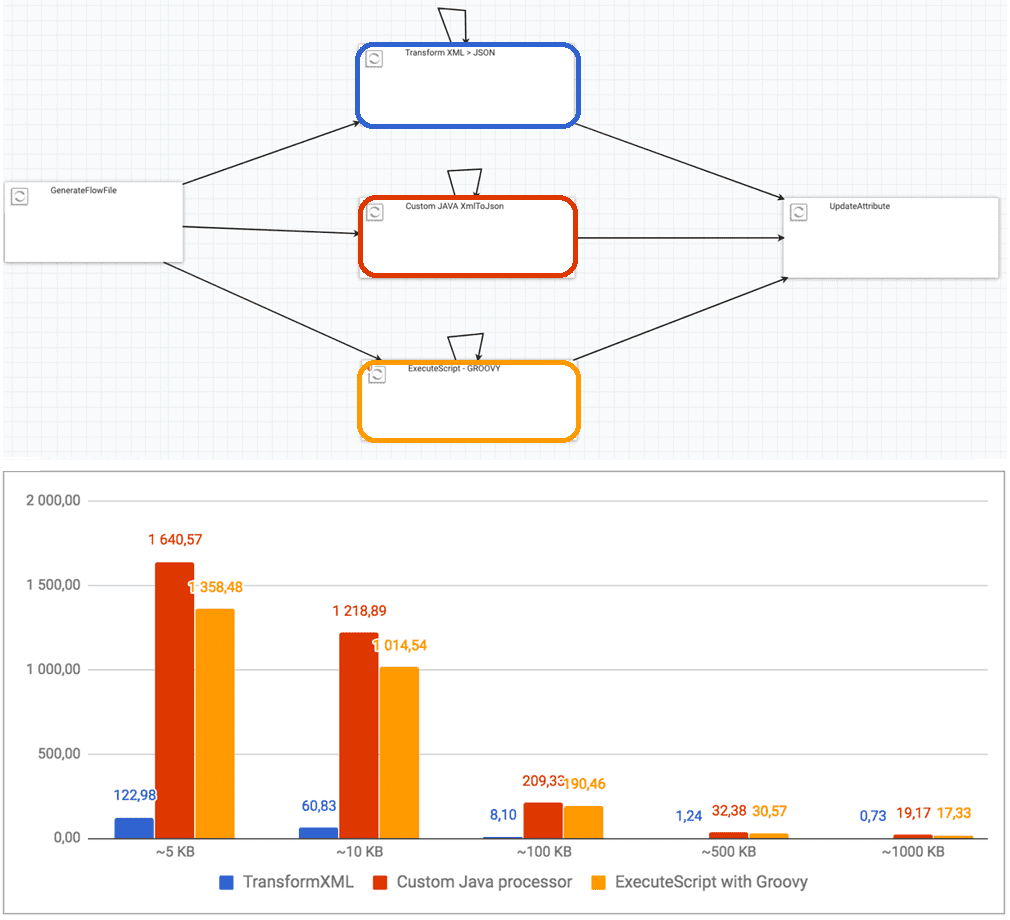
Эксперименты показали наибольшую производительность пользовательского процессора, написанного на Java, который является нативным языком Apache NiFi. А встроенный процессор TransformXML оказался самым медленным. Вариант с Groovy-скриптом и процессором ExecuteScript оказался эффективнее TransformXML, но имеет меньшую производительность, чем пользовательский Java-процессор. Впрочем, это предсказуемо, поскольку динамический объектно-ориентированный язык программирования Groovy, разработанный как дополнение к языку Java с возможностями Python, Ruby и Smalltalk, все же работает чуть медленнее оригинала (Java). Тем не менее, вариант c Groovy-скриптом обеспечивает довольно хорошую производительность и не требует сборки и компиляции собственного процессора: дата-инженер может написать его прямо из пользовательского интерфейса NiFi, что намного проще разработки Java-кода.
Согласно результатам эксперимента, обработка очень маленьких файлов с использованием Java-процессора примерно в 13 раз эффективнее, чем TransformXML-процессор. А с файлами размером более 100 КБ разница возрастает еще в 2 раза. Это связано с тем, при обработке тысяч потоковых файлов в секунду в NiFi возникают небольшие накладные расходы.
Чтобы улучшить производительность XSLT-процессора, можно изменять значения параметра продолжительность выполнения (run duration) и увеличить количество одновременных задач. При этом стоить помнить про ограничения фреймворка, особенно те, которые касаются операций дискового ввода-вывода, о чем мы писали здесь. Впрочем, с несколькими объемными дисками для репозитория контента кластер NiFi вполне способен обрабатывать сотни миллионов XML-документов в день.
Читайте в нашей новой статье про уязвимости, связанные с XSLT-преобразованиями и обработкой внешних сущностей XML в Apache NiFi.
Как эффективно использовать Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://ru.wikipedia.org/wiki/XSLT
- https://pierrevillard.com/2017/09/07/xml-data-processing-with-apache-nifi/
- https://stackoverflow.com/questions/55713740/how-to-transform-xml-in-apache-nifi
- https://nifi.apache.org/docs/nifi-docs/components/org.apache.nifi/nifi-standard-nar/1.20.0/org.apache.nifi.processors.standard.TransformXml/index/
- https://www.freeformatter.com/xsl-transformer/

