 1875
1875 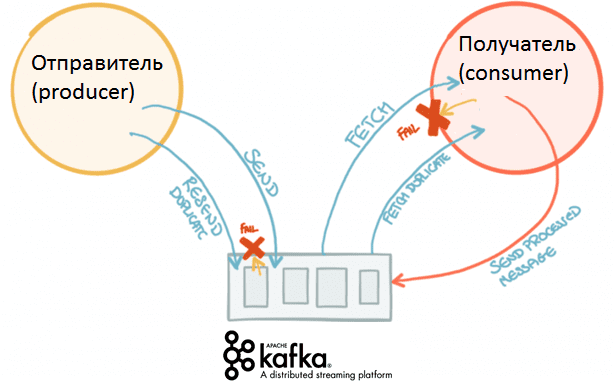
Содержание
Вчера мы говорили про концепцию QaaS, очереди сообщений в Apache Kafka и другие проблемы производительности высоконагруженных систем с использованием этой Big Data платформы. Сегодня рассмотрим сложности многопоточной обработки событий в разном порядке: когда возникают подобные ситуации и как их решить. Для этого еще раз сравним Кафку с ее вечным конкурентом, RabbitMQ, и проанализируем гарантии доставки сообщений: что это такое и почему exactly-once по-разному работает для издателей/производителей (producer) и подписчиков/потребителей (consumer).
Сложная маршрутизация очередей или проблемы многопоточной обработки в Big Data
Несмотря на надежность, масштабируемость, высокую пропускную способность и ряд других достоинств, Apache Kafka – это не серебряная пуля для всех Big Data систем потоковой обработки событий. В частности, на практике часто возникают задачи, для решения которых Кафка по умолчанию не предназначена. Например, если в один раздел (partition) топика Kafka попадают несколько сообщений (mes1, mes2, mes3), которые должны обрабатываться разными потоками. При этом бизнес-логика обработки этих сообщений не совпадает с порядком их записи в распределенный журнал Кафка. К примеру, обработка mes1 должна выполняться после mes3. А если при этом произошел сбой, то возможна потеря сообщения или их повторная обработка, что противоречит бизнес-правилам [1].
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Такая ситуация обусловлена самой концепцией Apache Kafka, где сообщения записываются в реплицированный журнал (топик) упорядоченно и последовательно. В отличие от Кафка, другой брокер сообщений, часто используемый в Big Data проектах, RabbitMQ позволяет гибко решить подобную задачу, благодаря 4-м способам маршрутизации на разные обменники для постановки в различные очереди. Также RabbitMQ поддерживает произвольный порядок работы с сообщениями в рамках задаваемых наборах (группах) событий. Подробнее про сходства и отличия Apache Kafka и RabbitMQ мы писали здесь.
Возвращаясь к рассматриваемой проблеме многопоточной обработки событий в Кафка, отметим несколько способов ее решения:
- стратегия доставки сообщений «строго 1 раз» (exactly once) позволит избежать потери или повторной обработки данных;
- обрабатывать смещение (offset) в разделе топика Кафка, чтобы в случае сбоя читатель/потребитель (consumer) возвращался к последней позиции, избегая потери данных или их повторной обработки [2].
Однако, 2-ой способ требует большей дополнительной работы по настройке, поскольку по умолчанию Кафка отправляет подтверждение об успешной обработке не каждого сообщения в отдельности, а в пределах пакета (группы) [1]. Поэтому сообщество Big Data разработчиков с восторгом встретило релиз Apache Kafka 0.11 в 2017 году, когда система стала поддерживать строго однократную доставку (exactly once).
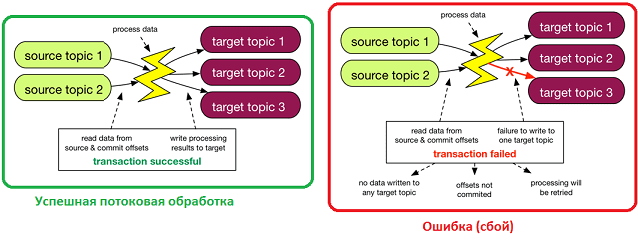
Что такое exactly once: как работает строго однократная доставка в Apache Kafka
Напомним основную суть работы Kafka как Big Data платформы потокового сбора и агрегации событий [1]:
- приложения-издатели или производители (producer) отправляют сообщения в реплицированный журнал (топик);
- приложения-подписчики или потребители (consumer) считывают сообщения из разделов (partition) топика по принципу «1 раздел – 1 потребитель», чтобы соблюсти очередность в пределах одного раздела.
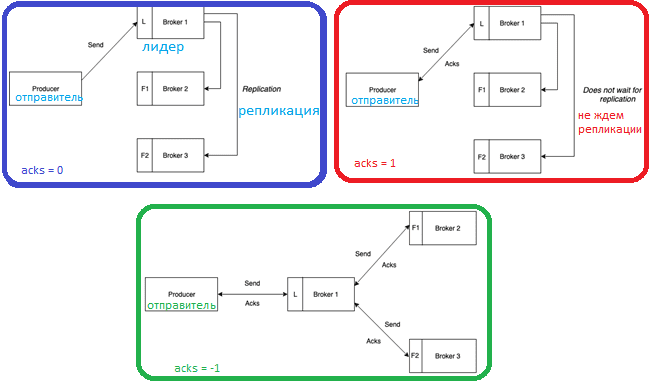
Кафка позиционируется как высоконадежная Big Data система, поэтому при сбое отдельного брокера или обрыве сетевого соединения отправляемые producer’ом сообщения не должны теряться. За это отвечают семантики доставки сообщений и число подтверждений об успешной записи (acknowledge, acks). Параметр acks влияет на надежность и может принимать следующие значения [3]:
- 0, когда producer вообще не ждет никакого подтверждения, а сообщение считается в любом случае отправленным. При этом невозможно гарантировать, что сервер получил запись, а в случае сбоя повторная отправка не выполняется. Смещение, возвращаемое для каждой записи, всегда будет установлено равным -1.
- 1, когда отправленное сообщение записывается в локальный журнал одного брокера в кластере Кафка (лидер, leader), не ожидая полного подтверждения от всех остальных серверов (подписчиков, followers). При этом сообщение может быть потеряно в случае сбоя лидера до репликации записи по всему кластеру.
- -1 или all, когда producer ждет полной репликации сообщения по всем серверам кластера, что обеспечивает надежную защиту от потери данных, но увеличивает задержку (latency) и снижает пропускную способность.
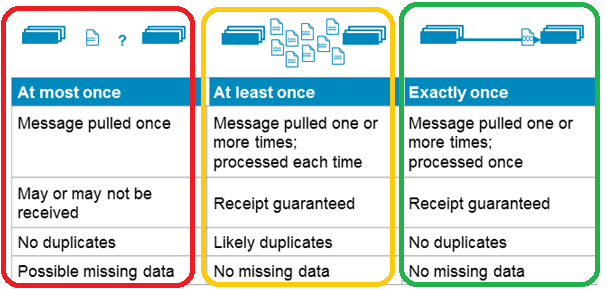
Также различают 3 вида семантик доставки сообщений [4]:
- хотя бы 1 раз (at least once), когда отправитель сообщения получает подтверждение от брокера Kafka при значении параметра acks=all, что гарантирует однократную запись сообщения в топик Kafka. Но если отправитель не получил подтверждения по истечении определенного времени или получил ошибку, он может повторить отправку. При этом сообщение может быть дублировано, если брокер дал сбой непосредственно перед отправкой подтверждения, но после успешной записи сообщения в топик Kafka.
- не более 1-го раза (at most once), когда отправитель не повторяет отправку сообщения при отсутствии подтверждения или в случае ошибки. При этом возможна ситуация, что сообщение не записано в топик Кафка и не получено потребителем. На практике в большинстве случаев сообщения будут доставляться, но иногда возможна потеря данных.
- строго однократно (exactly once), когда даже при повторной попытке отправителя отправить сообщение, оно доставляется строго один раз. В случае ошибки, заставляющей отправителя повторить попытку, сообщение будет однократно записано в логе брокера Kafka. Это избавляет от дублирования или потери данных из-за ошибок на стороне producer’a или брокера Кафка. Чтобы включить эту функцию для каждого раздела следует задать свойство идемпотентности в настройках отправителя idempotence=true. Напомним, идемпотентной считается операций, которая при многократном выполнении даёт тот же результат, что и при однократном.
Доставка exactly once реализована следующим образом: каждый пакет сообщений, отправленный в Kafka, содержит порядковый номер, чтобы брокер мог определить наличие данных и исключить их дублирование. Этот порядковый номер сохраняется в реплицированный лог, поэтому даже в случае сбоя главной реплики любой брокер распознает дублирование вновь отправленной информации [4]. Подробнее про репликацию и ее влияние на общую производительность Big Data системы на базе Кафка мы рассказываем в новой статье.
Резюмируя описание строго однократной доставки сообщений в Apache Kafka, можно заметить, что этот механизм ориентирован, в первую очередь, на отправителей. Потребитель сам должен позаботиться о том, чтобы не обработать одну и ту же запись несколько раз. Впрочем, это соответствует самой концепции Kafka «тупой сервер, умный клиент», когда вся логика работы с сообщениями реализуется на клиентской стороне. Таким образом, в Кафка потребитель вытягивает (pull) нужное сообщение из топика, ориентируясь на смещение (offset). В RabbitMQ, наоборот, consumer не заботится о получении информации – брокер сам обеспечивает всю логику работы с сообщениями, проталкивая их потребителям (push). Из-за такой специфики работы с отправителями и потребителями RabbitMQ не гарантирует строго однократную доставку сообщений, при этом предоставляя гарантии «at most once» и «at least once», как и Кафка. Подробнее об этом мы рассказывали в статье «Apache Kafka vs RabbitMQ».
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Еще больше прикладных примеров работы с кластером Apache Kafka и распределенными приложениями потоковой обработки событий вы узнаете, пройдя обучение Кафка на специализированных практических курсах в «Школе Больших Данных» — лицензированном учебном центре для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

