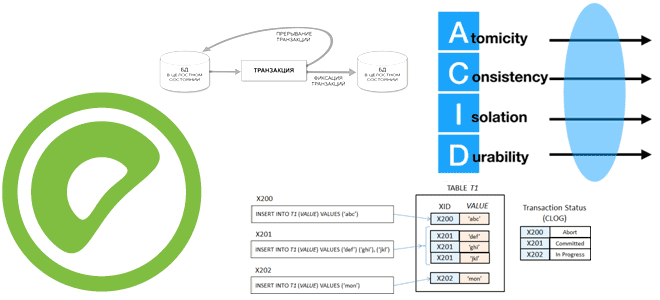
Недавно мы писали про трудности реализации ACID-требований к транзакциям в распределенных базах данных и способах их решения. Сегодня рассмотрим, как это работает в Greenplum с Arenadata DB: уровни изоляции, идентификаторы транзакций, моментальные снимки и MVCC-модель управления параллелизмом. Как GP и Arenadata DB реализуют распределенные транзакции Будучи основанной на PostgreSQL, Greenplum...

В этой статье для обучения дата-инженеров и разработчиков ETL-конвейеров на Apache NiFi рассмотрим, как преобразовать JSON-документы с помощью реализации JOLT-библиотеки в процессорах JOLTTransformJSON и JOLTTransformRecord. Что такое JOLT и как это работает Человекочитаемый формат JSON активно используется для представления пакетных и потоковых данных. Он легковеснее XML и прост для понимания,...
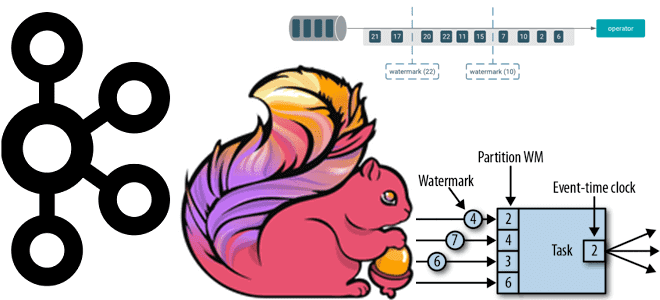
Почему вместо автоматической фиксации топиков Kafka приложению-потребителю Apache Flink лучше использовать контрольные точки, как создаются и обрабатываются водяные знаки и при чем тут оконные операторы потоковой обработки данных. Смещение в топиках Kafka для потоковых приложений Apache Flink Благодаря мощному API пакетной и потоковой обработки, Apache Flink часто используется для разработки...
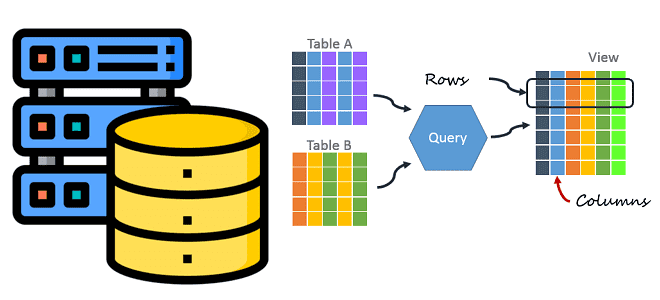
Как данные хранятся на диске при разной ориентации хранилища в СУБД: чем отличаются колоночные базы от строковых с точки зрения практического использования в дата-инженерии. Сравнительная таблица с примерами и выводами. Как данные хранятся на диске и при чем здесь ориентация СУБД Способы хранения данных в СУБД можно разделить на 2...

Что общего у FastAPI с BentoML, чем они отличаются и почему только один из них является полноценным MLOps-инструментом. Смотрим на примере операций разработки и развертывания API сервисов машинного обучения. Что общего у FastAPI с BentoML и при чем здесь MLOps С точки зрения промышленной эксплуатации, в проектах машинного обучения следует...
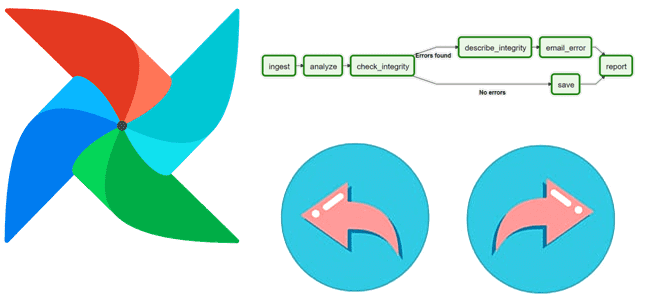
Что такое backfill в Apache AirFlow и зачем дата-инженеру запускать эту команду CLI-интерфейса при управлении DAG. Разбираемся с параметрами, возможностями и исключениями. Что такое backfill в Apache AirFlow и чем это полезно при управлении DAG Иногда при управлении конвейерами обработки данных в Apache AirFlow дата-инженеру необходимо вернуться в прошлое, чтобы...

Как использовать преимущества графических процессоров для Spark-приложений аналитики больших данных и машинного обучения с помощью библиотек RAPIDS. Знакомимся с ускорителем Spark RAPIDS и его возможностями сделать популярный вычислительный движок еще быстрее. Что такое RAPIDS Accelerator для Apache Spark и как он работает Системы Machine Learning, особенно проекты глубокого обучения, уже...
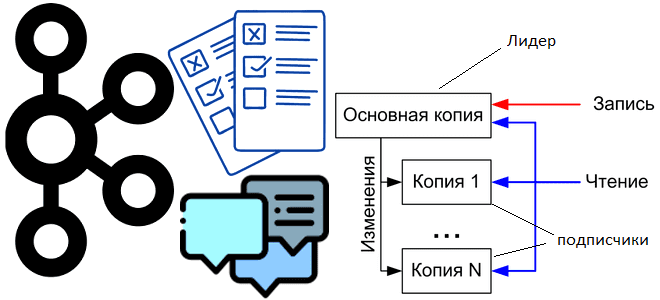
Сегодня рассмотрим, как внутренние механизмы Apache Kafka обеспечивают отказоустойчивость это потоковой платформы передачи событий, а также разберем, почему до сих пор приходится выбирать между доступностью и надежностью. Выборы нового лидера при сбое прежнего и ожидание подтверждений об успешной репликации. Поиск компромисса между надежностью и доступностью в Apache Kafka Для обеспечения...

9 февраля 2023 года опубликован очередной выпуск Apache NiFi. Разбираемся, что нового в релизе 1.20, какие появились процессоры для потокового приема и обработки данных, как устранена уязвимость CVE-2023-22832 и зачем нужны очередные изменения в функциях внутренних языков NiFi. Исправленные ошибки в Apache NiFi 1.20 В свежем выпуске Apache NiFi 1.20...

Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh. Что такое Delta Sharing и при чем здесь Data Lake Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и...
Как протестировать работу приложения Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Разбираем особенности ручного и автоматизированного тестирования Flink SQL на уровне отдельных функций, модулей и их интеграционного взаимодействия. Модульное и интеграционное тестирование приложений Apache Flink SQL Тестирование является неотъемлемой частью любого процесса разработки ПО,...

Сегодня в рамках обучения администраторов SQL-on-Hadoop рассмотрим, как защитить данные в кластере Apache HBase от несанкционированного доступа. Аутентификация и авторизация пользователей, операторы управления доступом к таблицам, метки видимости и шифрование данных. Механизмы защиты данных в Apache HBase Как и любое хранилище, колоночно-ориентированная мультиверсионная NoSQL-СУБД типа key-value Apache HBase, которая работает...
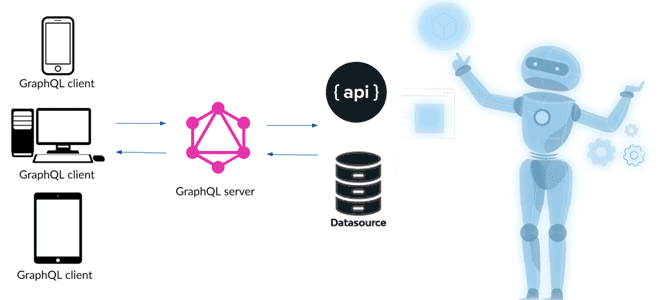
Недавно мы упоминали GraphQL как мощный и гибкий язык запросов к данным, хранящимся в графовых СУБД. Сегодня рассмотрим, чем эта технология может быть полезна в проектах Machine Learning, какие сложности с ней связаны и как их решить с помощью MLOps. GraphQL для ML: возможности и примеры Не будучи в чистом...
Какие подходы позволяют увеличить емкость СУБД, чтобы повысить объем хранящихся в ней данных и ускорить вычисления. Разбираем тонкости масштабирования распределенной базы данных с массово-параллельной обработкой Greenplum: действия администратора по добавлению новых узлов в кластер. Как увеличить емкость базы данных: 4 подхода к масштабированию Чтобы увеличить емкость СУБД, т.е. объем хранимых...

Продолжая разговор про языки запросов к графовым базам данных, сегодня познакомимся с GSQL, который поддерживается в MPP-СУБД TigerGraph. Как работает эта распределенная NoSQL-база данных и каким образом реализует ACID-требования к транзакциям в операциях с графами. Архитектура и принципы работы графовой MPP-СУБД TigerGraph — это распределенное графоориентированное хранилище данных с массивно-параллельной...
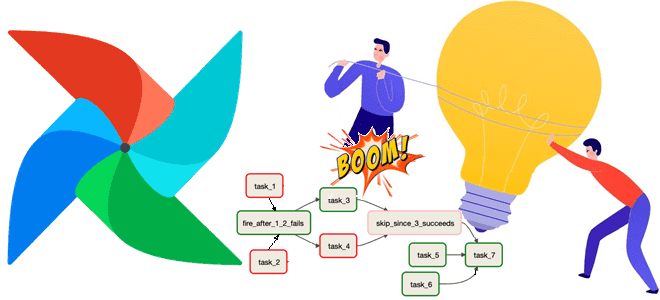
Как установить и отследить в Apache AirFlow зависимости экземпляров задач друг от друга, узнать о запуске конкретной задачи в DAG, использовать обратные вызовы и правила триггеров, а также шаблоны и макросы Jinja. Полезные примеры управления ETL-конвейерами для дата-инженера в GUI и CLI-интерфейсах. Как узнать время запуска последнего экземпляра задачи? Будучи...

Как повысить скорость выполнение SQL-запросов в Spark-приложениях, используя Gluten – новый вычислительный движок, объединяющий несколько векторизированных механизмов выполнения с поддержкой аппаратных ускорителей. Что такое Gluten и как он появился в Apache Spark Когда данных много, их обработка может длиться долго. Чтобы ускорить вычисления с Big Data, разработчики распределенных приложений и...
Недавно мы писали об изменении статуса и улучшении протокола KRaft в Apache Kafka 3.3. Сегодня погрузимся в эту тему чуть глубже и рассмотрим, как отказ от Zookeeper влияет на количество разделов и возможность одного и того же кластера Kafka с одним набором топиков обслуживать разные типы приложений в различных бизнес-сценариях....
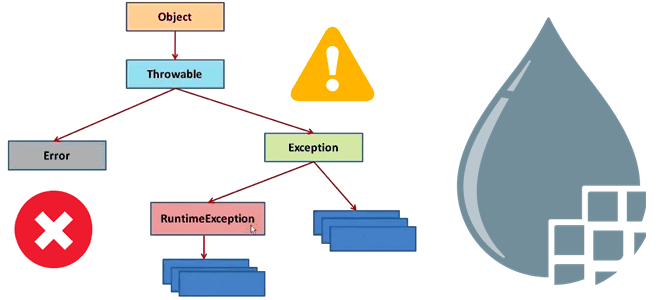
Сегодня посмотрим на Apache NiFi с точки зрения разработчика Data Flow и разберем ключевые нюансы обработки ошибок, генерации исключений и лучшие практики работы с ними для практических задач дата-инженерии. Исключения процессоров Apache NiFi При том, что Apache NiFi имеет множество готовых процессоров для подключения ко внешним источникам или приемникам данных,...
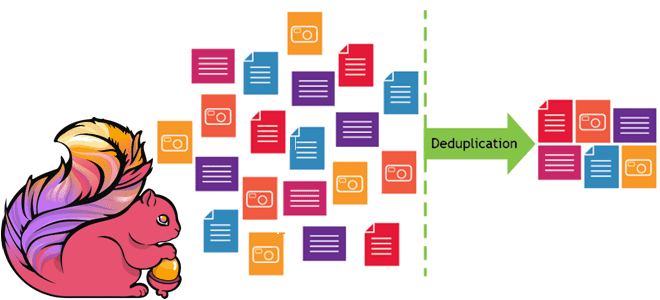
Чем опасны дубли данных при их потоковой обработке и как реализовать дедупликацию в Apache Flink SQL. Смотрим на практическом примере для обучения дата-инженеров и разработчиков распределенных приложений. Потоковая дедупликация данных в Apache Flink SQL Apache Flink можно назвать уникальный фреймворком для разработки распределенных приложений в области Big Data, который унифицирует...