
NoSQL (Нереляционные базы данных) - это базы данных, которые используют для хранения информации модели, отличающиеся от привычных нам плоских таблиц. Термин NoSQL ("Not Only SQL") означает, что эти решения не ограничиваются жесткими рамками реляционной логики. Они предлагают более гибкие способы организации данных. В отличие от классического подхода, где структура данных...

Apache Cassandra – это нереляционная отказоустойчивая распределенная СУБД, рассчитанная на создание высокомасштабируемых и надёжных хранилищ огромных массивов данных, представленных в виде хэша. Проект был разработан на языке Java в корпорации Facebook в 2008 году, и передан фонду Apache Software Foundation в 2009 [1]. Эта СУБД относится к гибридным NoSQL-решениям, поскольку она...

ClickHouse – колоночная реляционная СУБД с открытым исходным кодом от компании Яндекс для быстрой обработки аналитических SQL-запросов на структурированных больших данных (Big Data) в режиме реального времени.

Kudu – это колоночное хранилище данных в экосистеме Apache Hadoop, нереляционная СУБД (NoSQL) с открытым исходным кодом от компании Cloudera для оперативной аналитики быстро меняющихся данных в режиме реального времени. Назначение, история разработки и развития Основное назначение Apache Kudu состоит в заполнении аналитического разрыва между 2-мя движками хранения данных Apache...

Greenplum – open-source продукт, массивно-параллельная реляционная СУБД для хранилищ данных с гибкой горизонтальной масштабируемостью и столбцовым хранением данных на основе PostgreSQL. Благодаря своим архитектурным особенностям и мощному оптимизатору запросов, Гринплам отличается особой надежностью и высокой скоростью обработки SQL-запросов над большими объемами данных, поэтому эта MPP-СУБД широко применяется для аналитики Big...

Tarantool – open-source продукт российского происхождения, сервер приложений на языке Lua, интегрированный с резидентной NoSQL-СУБД, которая содержит все обрабатываемые данные и индексы в оперативной памяти, а также включает быстрый движок для работы с постоянным хранилищем (жесткие диски). Благодаря своим архитектурным особенностям, Тарантул позволяет быстро обрабатывать большие объемы данных, поэтому эта...
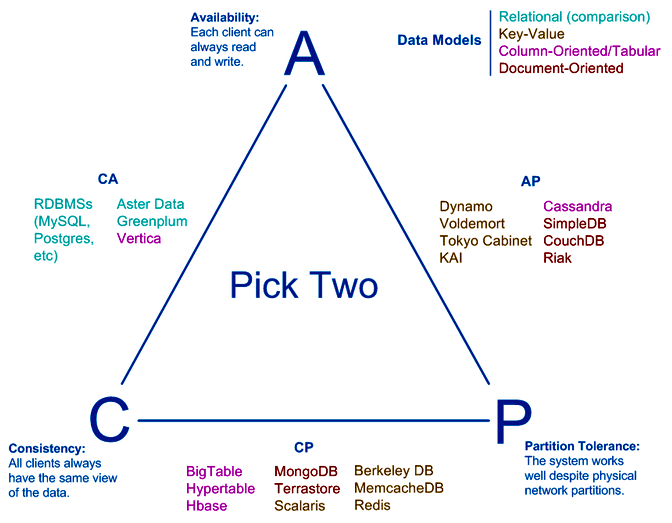
CAP – это акроним от англоязычных слов Consistency (Согласованность, Целостность), Availability (Доступность) и Partition tolerance (Устойчивость к разделению). Согласно утверждению профессора Калифорнийского университета в Беркли, Эрика Брюера, сделанному в 2000-м году, в распределенных системах осуществимы лишь 2 свойства из указанных 3-х. В частности, считается что нереляционные базы данных жертвуют согласованностью данных в...

Impala – это массив-параллельный механизм интерактивного выполнения SQL-запросов к данным, хранящимся в Apache Hadoop (HDFS и HBase), написанный на языке С++ и распространяющийся по лицензии Apache 2.0. Также Импала называют MPP-движком (Massively Parallel Processing), распределенной СУБД и даже базой данных стека SQL-on-Hadoop. Как появился Apache Impala и чем это связано...

Apache HBase – это нереляционная, распределенная база данных с открытым исходным кодом, написанная на языке Java по аналогии BigTable от Google. Изначально эта СУБД класса NoSQL создавалась компанией Powerset в 2007 году для обработки больших объёмов данных в рамках поисковой системы на естественном языке. Проектом верхнего уровня Apache Software Foundation HBase стала...
Apache Hive - это SQL интерфейс доступа к данным для платформы Apache Hadoop. Hive позволяет выполнять запросы, агрегировать и анализировать данные используя SQL синтаксис. Для данных в файловой системе HDFS используется схема доступа на чтение, позволяющая обращаться с данными, как с обыкновенной таблицей или реляционной СУБД. Запросы HiveQL транслируются в Java-код...