
Apache Flink – это распределенная отказоустойчивая платформа обработки информации с открытым исходным кодом, используемая в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop. Разработанный в 2010 году в Техническом университете Берлина в качестве альтернативы Hadoop MapReduce для распределенных вычислений больших наборов данных, Flink использует подход ориентированного...

Apache Spark – это Big Data фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop [1]. История появления Спарк и сравнение с Apache Hadoop Основным автором Apache Spark считается Матей Захария (Matei Zaharia), румынско-канадский учёный в области информатики....
Spark SQL - это часть Spark Structured API, с помощью этого API Вы можете работать с данными так, как будто Вы работаете с SQL сервером. API работает в обе стороны: результат выполнения SQL запроса - dataframe, в обратном направлении - регистрация существующего dataframe, как таблицы (к которой можно выполнить SQL...
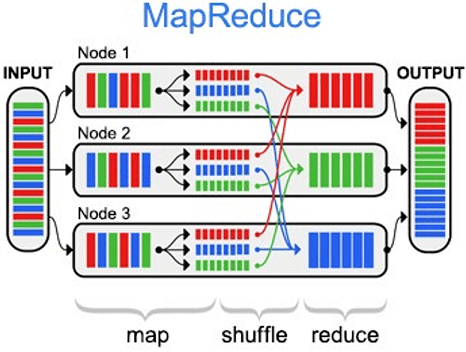
MapReduce – это модель распределённых вычислений от компании Google, используемая в технологиях Big Data для параллельных вычислений над очень большими (до нескольких петабайт) наборами данных в компьютерных кластерах, и фреймворк для вычисления распределенных задач на узлах (node) кластера [1]. Назначение и области применения MapReduce можно по праву назвать главной технологией...

Apache Samza (Самза) – это асинхронная вычислительная Big Data среда с открытым исходным кодом для распределенных потоковых вычислений практически в реальном времени, разработанная в 2013 году в соцсети LinkedIn на языках Scala и Java. Проектом верхнего уровня Apache Software Foundation Самза стала в 2014 году [1]. Samza vs Apache Kafka...
Apache Storm (Сторм, Шторм) – это Big Data фреймворк с открытым исходным кодом для распределенных потоковых вычислений в реальном времени, разработанный на языке программирования Clojure. Изначально созданный Натаном Марцем и командой из BackType, этот проект был открыт с помощью исходного кода, приобретенного Twitter. Первый релиз состоялся 17 сентября 2011 года,...

Apache Parquet - это бинарный, колоночно-ориентированный формат хранения больших данных, изначально созданный для экосистемы Hadoop, позволяющий использовать преимущества сжатого и эффективного колоночно-ориентированного представления информации. Паркет позволяет задавать схемы сжатия на уровне столбцов и добавлять новые кодировки по мере их появления [1]. Вместе с Apache Avro, Parquet является очень популярным форматом...