
NoSQL (Нереляционные базы данных) - это базы данных, которые используют для хранения информации модели, отличающиеся от привычных нам плоских таблиц. Термин NoSQL ("Not Only SQL") означает, что эти решения не ограничиваются жесткими рамками реляционной логики. Они предлагают более гибкие способы организации данных. В отличие от классического подхода, где структура данных...

Kudu – это колоночное хранилище данных в экосистеме Apache Hadoop, нереляционная СУБД (NoSQL) с открытым исходным кодом от компании Cloudera для оперативной аналитики быстро меняющихся данных в режиме реального времени. Назначение, история разработки и развития Основное назначение Apache Kudu состоит в заполнении аналитического разрыва между 2-мя движками хранения данных Apache...
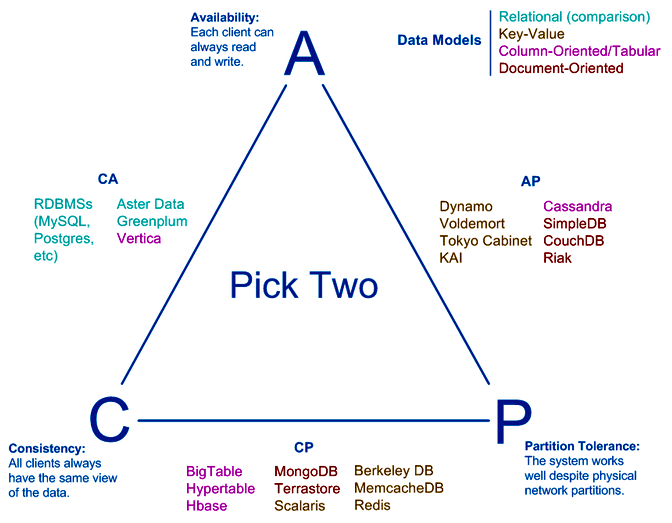
CAP – это акроним от англоязычных слов Consistency (Согласованность, Целостность), Availability (Доступность) и Partition tolerance (Устойчивость к разделению). Согласно утверждению профессора Калифорнийского университета в Беркли, Эрика Брюера, сделанному в 2000-м году, в распределенных системах осуществимы лишь 2 свойства из указанных 3-х. В частности, считается что нереляционные базы данных жертвуют согласованностью данных в...

Impala – это массив-параллельный механизм интерактивного выполнения SQL-запросов к данным, хранящимся в Apache Hadoop (HDFS и HBase), написанный на языке С++ и распространяющийся по лицензии Apache 2.0. Также Импала называют MPP-движком (Massively Parallel Processing), распределенной СУБД и даже базой данных стека SQL-on-Hadoop. Как появился Apache Impala и чем это связано...